Download as PDF, PPTX










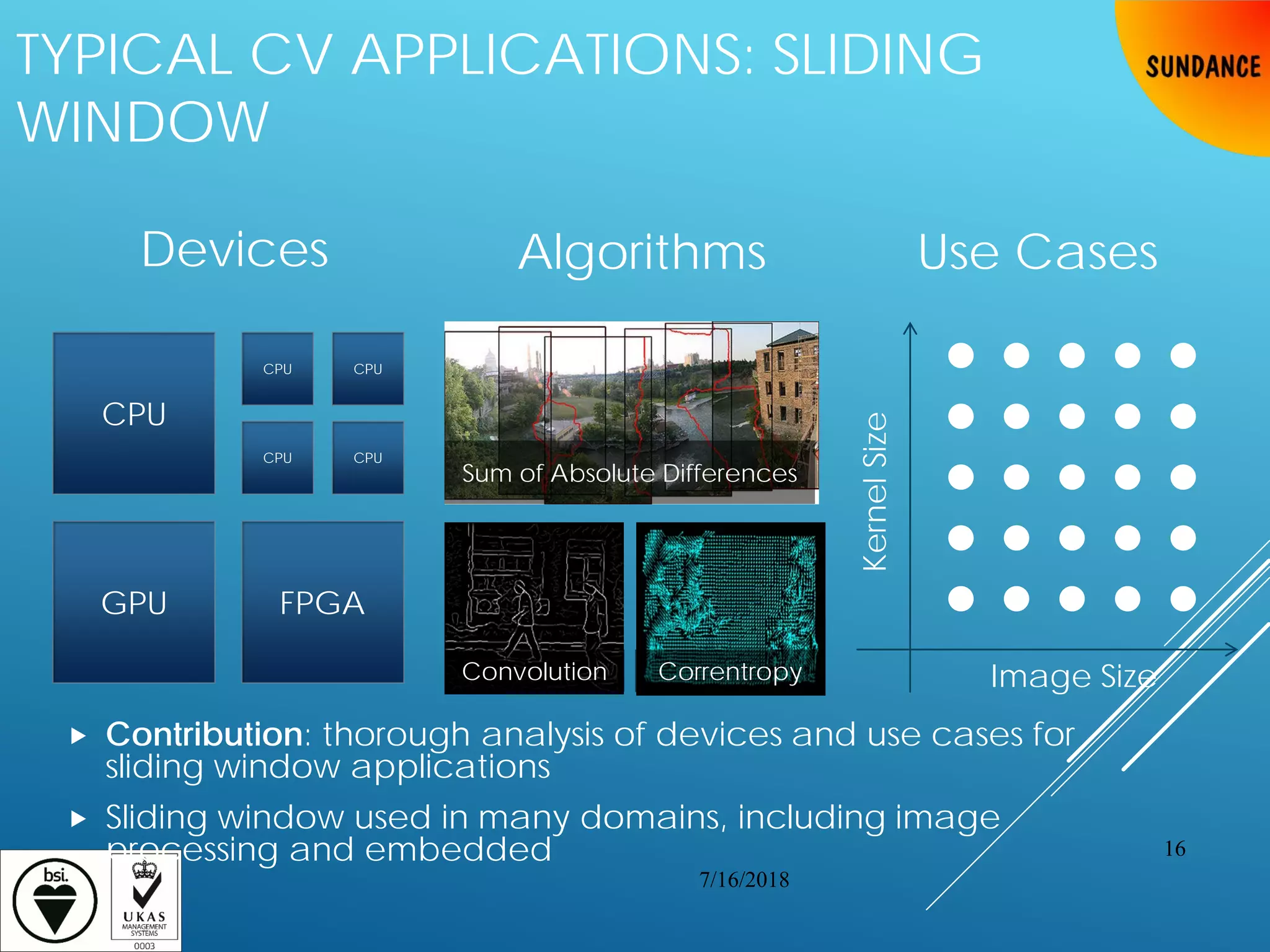
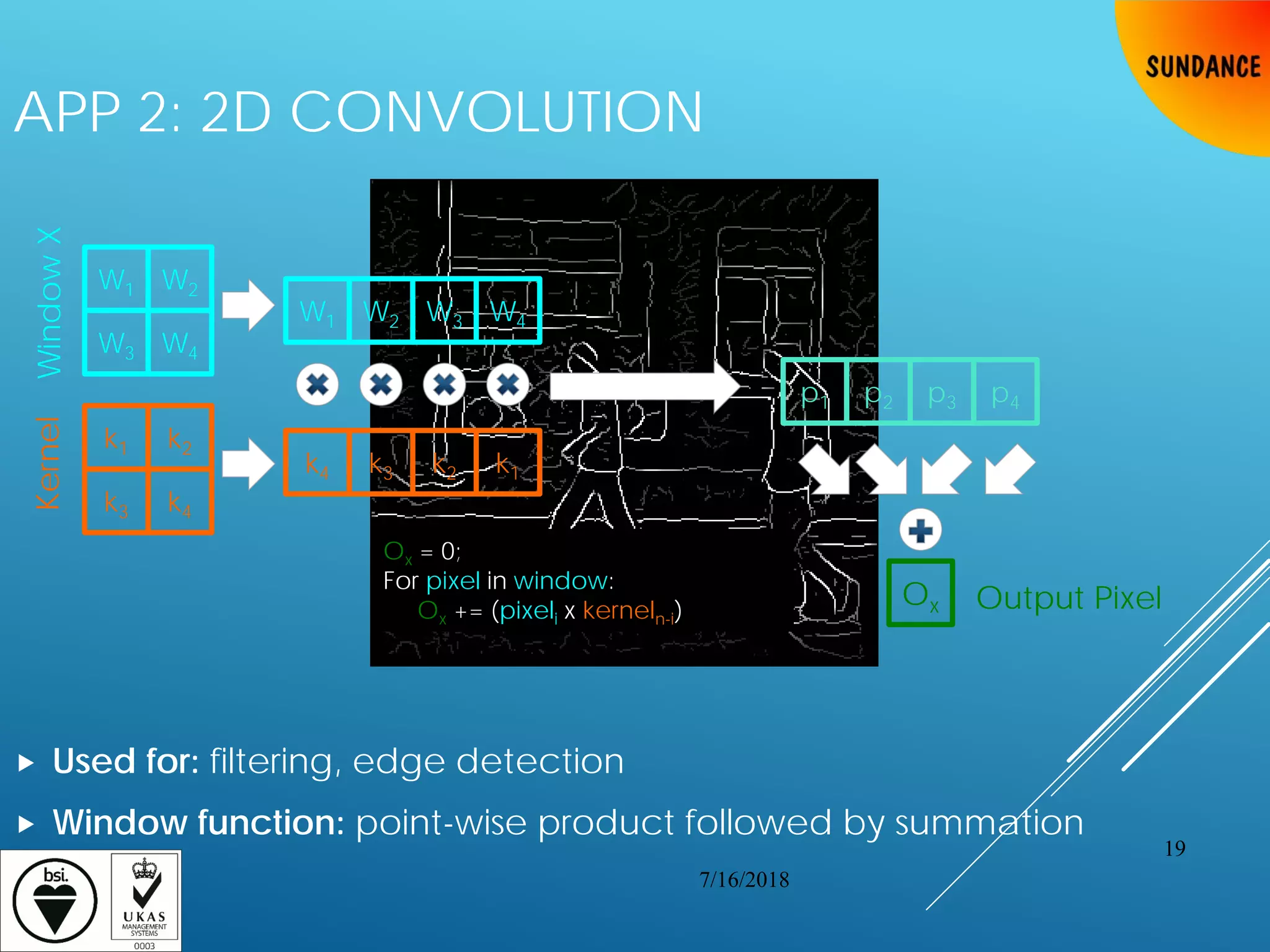
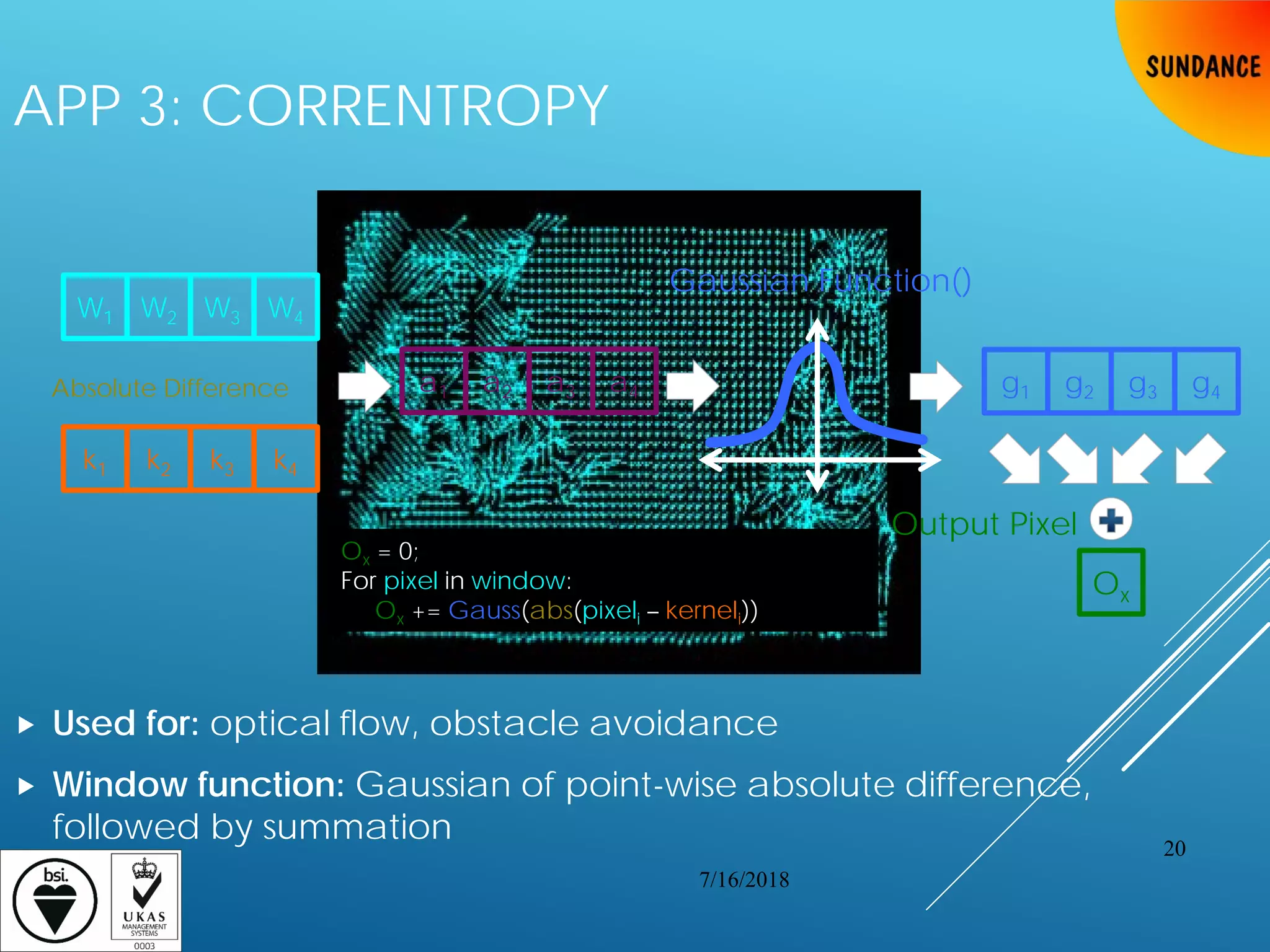
![TYPICAL CV APPLICATIONS: SLIDING
WINDOW APPLICATIONS
Consider a 2D Sliding Window with 16-bit grayscale image inputs
Applies window function against a window from image and the kernel
“Slides” the window to get the next input
Repeats for every possible window
45x45 kernel on 1080p 30-FPS video = 120 billion memory accesses/second
Window KernelWindow 0
Window Function
Output Pixel
Window W-1
Window 1Input: image of size x×y, kernel of size n×m
for (row=0; row < x-n; row++) {
for (col=0; col < y-m; col++) {
// get n*m pixels (i.e., windows
// starting from current row and col)
window=image[row:row+n-1][col:col+m-1]
output[row][col]=f(window,kernel)
}
}
7/16/2018
17](https://image.slidesharecdn.com/1-e3mvsundance-180725124009/75/E3MV-Embedded-Vision-Sundance-17-2048.jpg)




![VCS-1 (EMC2) HARDWARE FEATURES
Connectivity:
FM191-R; FMC-LPC to:
15x Digital I/Os [DB9]
12x Analogue Inputs [DB9]
8x Analogue Outputs [DB9]
1x Expansion [SEIC]
FM191-U; SEIC to:
4x USB3.0 [USB-c]
28x GPIO [40-pin GPIO]
FM191-A1; 40-pin GPIO
28x GPIO [DB9]
7/16/2018
27](https://image.slidesharecdn.com/1-e3mvsundance-180725124009/75/E3MV-Embedded-Vision-Sundance-27-2048.jpg)


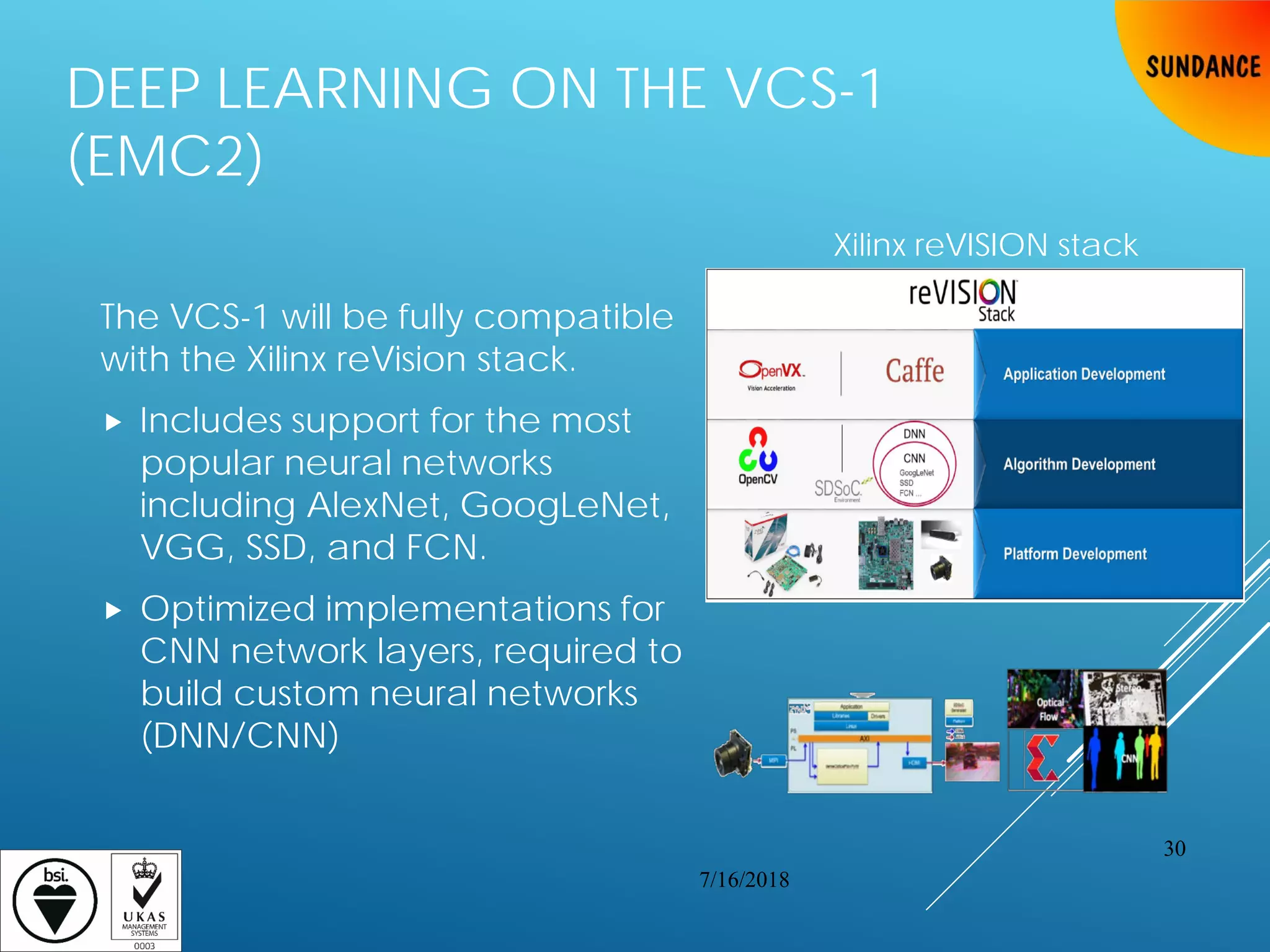








The document provides an overview of Sundance Multiprocessor Technology Ltd. and their EM3V - Embedded Vision product. Some key points: - Sundance is an employee-owned company with over 300 years of experience designing and building their own products. - Their VCS-1 (EMC2) system is a modular and reconfigurable hardware platform compatible with Zynq UltraScale+ MPSoC devices and a wide range of sensors. - The system includes open source software, firmware and documentation and is compatible with popular frameworks like ROS, OpenCV and deep learning stacks for running neural networks.
































![[Harvard CS264] 03 - Introduction to GPU Computing, CUDA Basics](https://cdn.slidesharecdn.com/ss_thumbnails/cs264201103-cudabasicsshare-110209024624-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)










































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)











