Downloaded 19 times















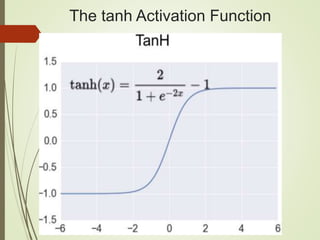
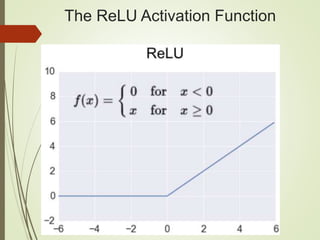




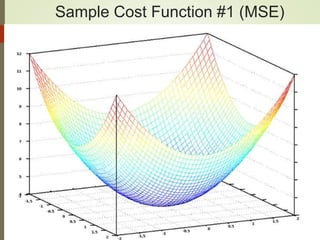
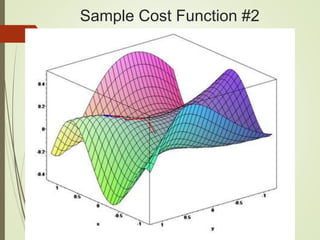
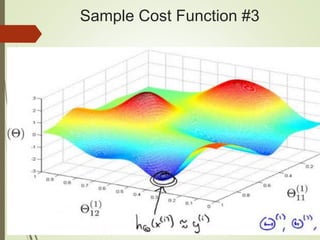


![Setting up Data & the Model
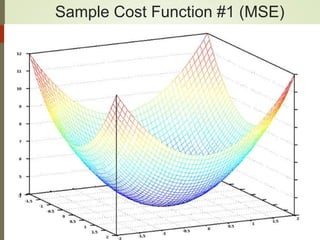
Normalize the data (DL only):
Subtract the ‘mean’ and divide by stddev
[Central Limit Theorem]
Initial weight values for NNs:
Random numbers between -1 and 1
More details:
http://cs231n.github.io/neural-networks-2/#losses](https://image.slidesharecdn.com/sfandroiddl-170928060634/85/Android-and-Deep-Learning-37-320.jpg)






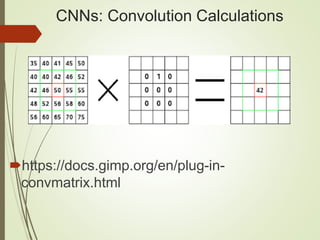
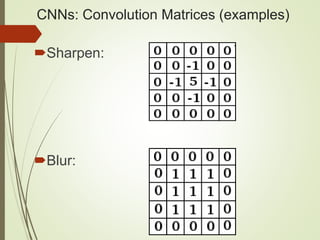
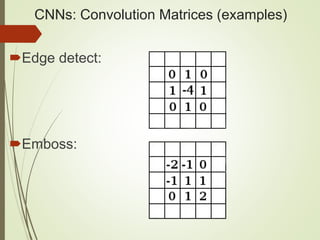
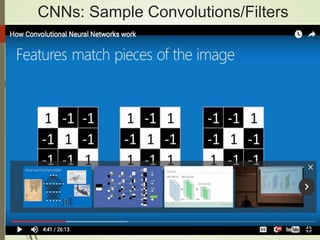
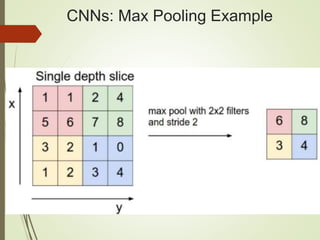
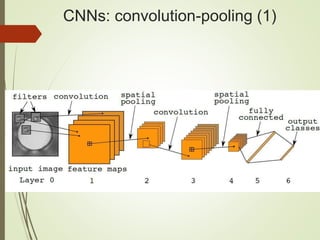
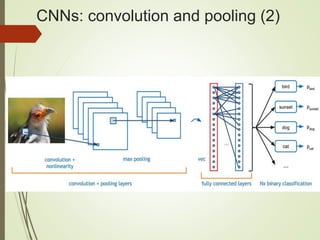















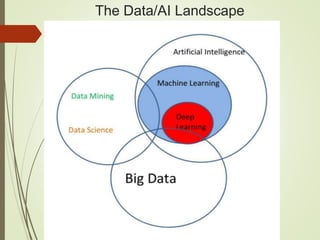
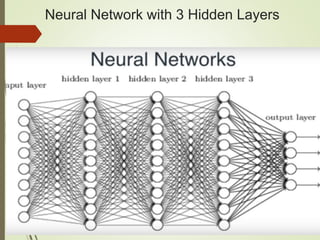
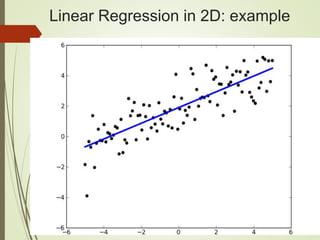
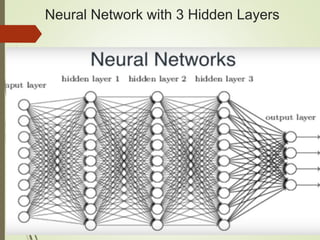
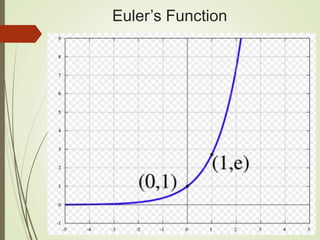
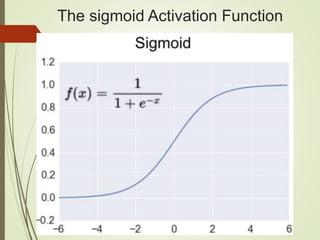
The document provides an overview of deep learning and its applications to Android. It begins with introductions to concepts like linear regression, activation functions, cost functions, and gradient descent. It then discusses neural networks, including convolutional neural networks (CNNs) and their use in image processing. The document outlines several approaches to integrating deep learning models with Android applications, including generating models externally or using pre-trained models. Finally, it discusses future directions for deep learning on Android like TensorFlow Lite.







































![Deep learning in python ommunic [CNN].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/deeplearninginpythoncnn-251207084743-a5c807e1-thumbnail.jpg?width=640&height=640&fit=bounds)