Download as PDF, PPTX








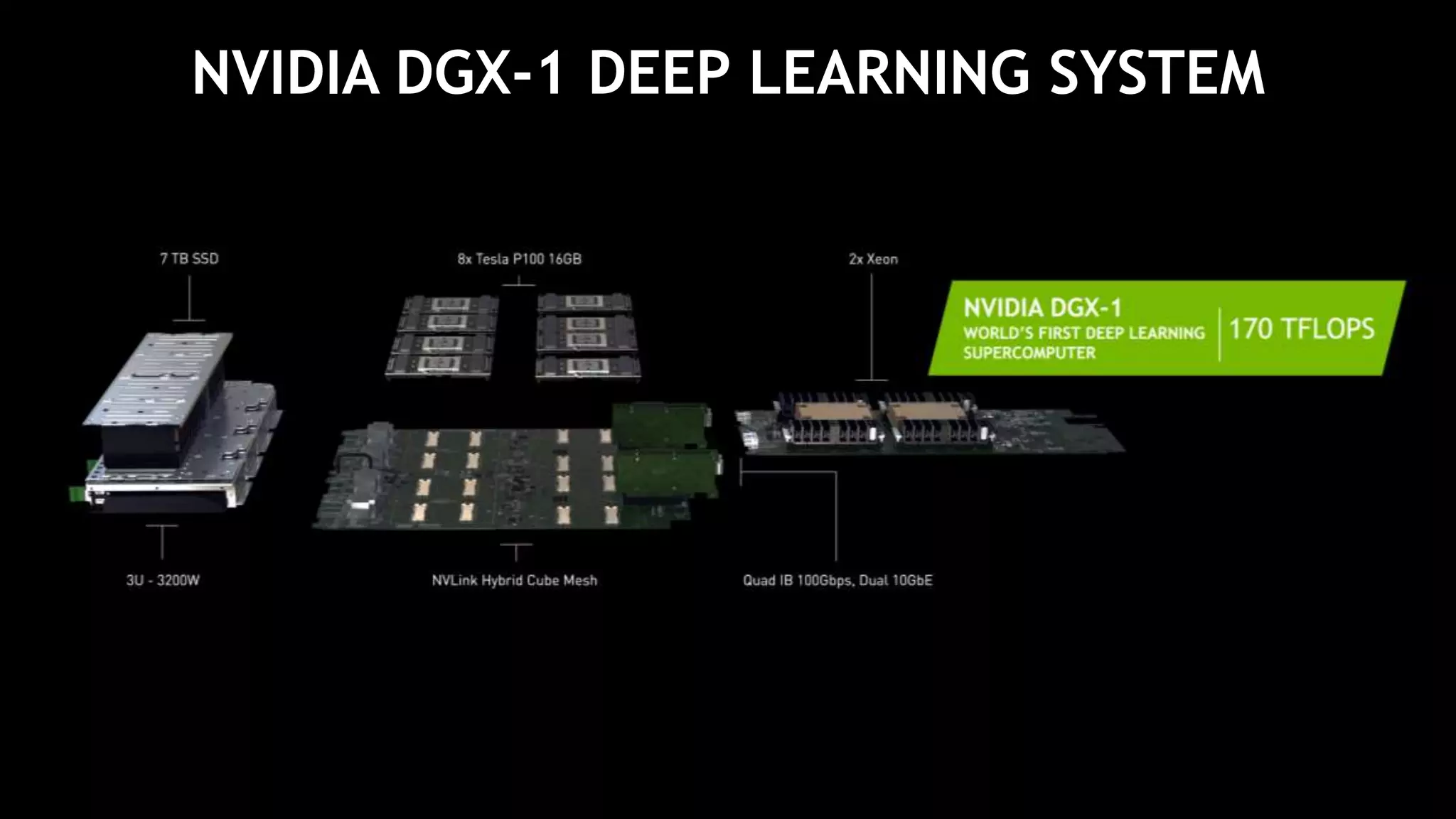





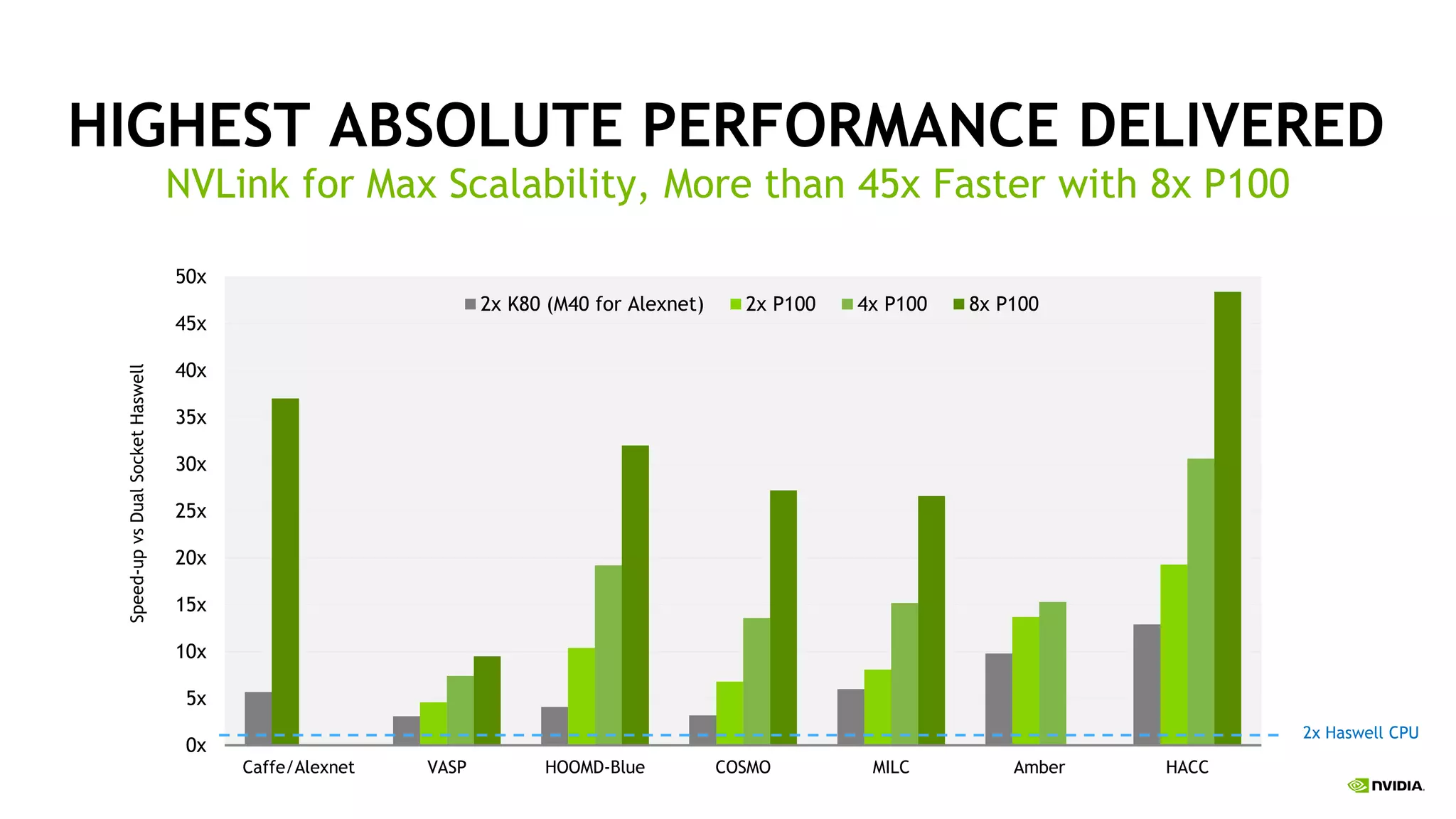
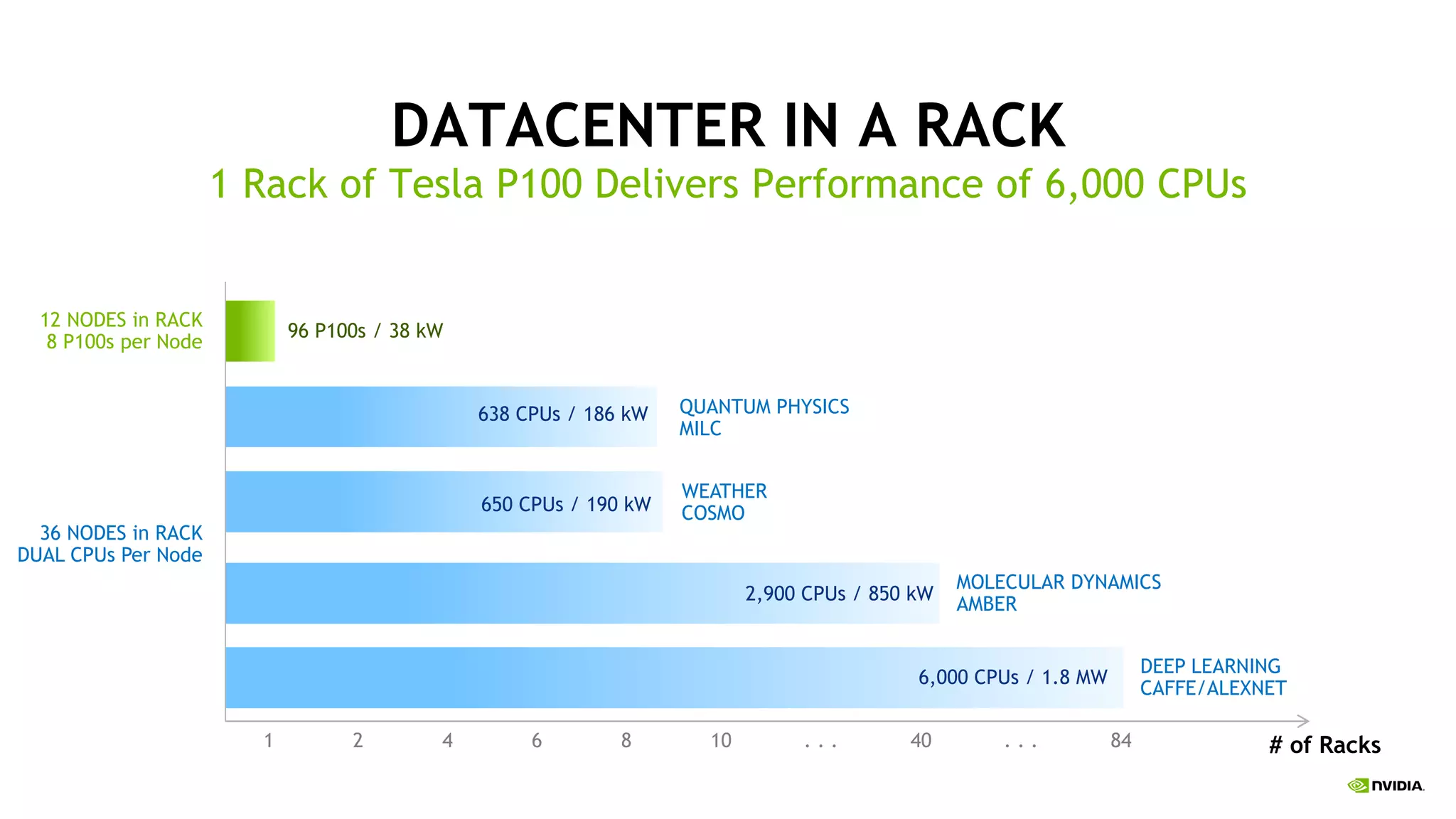



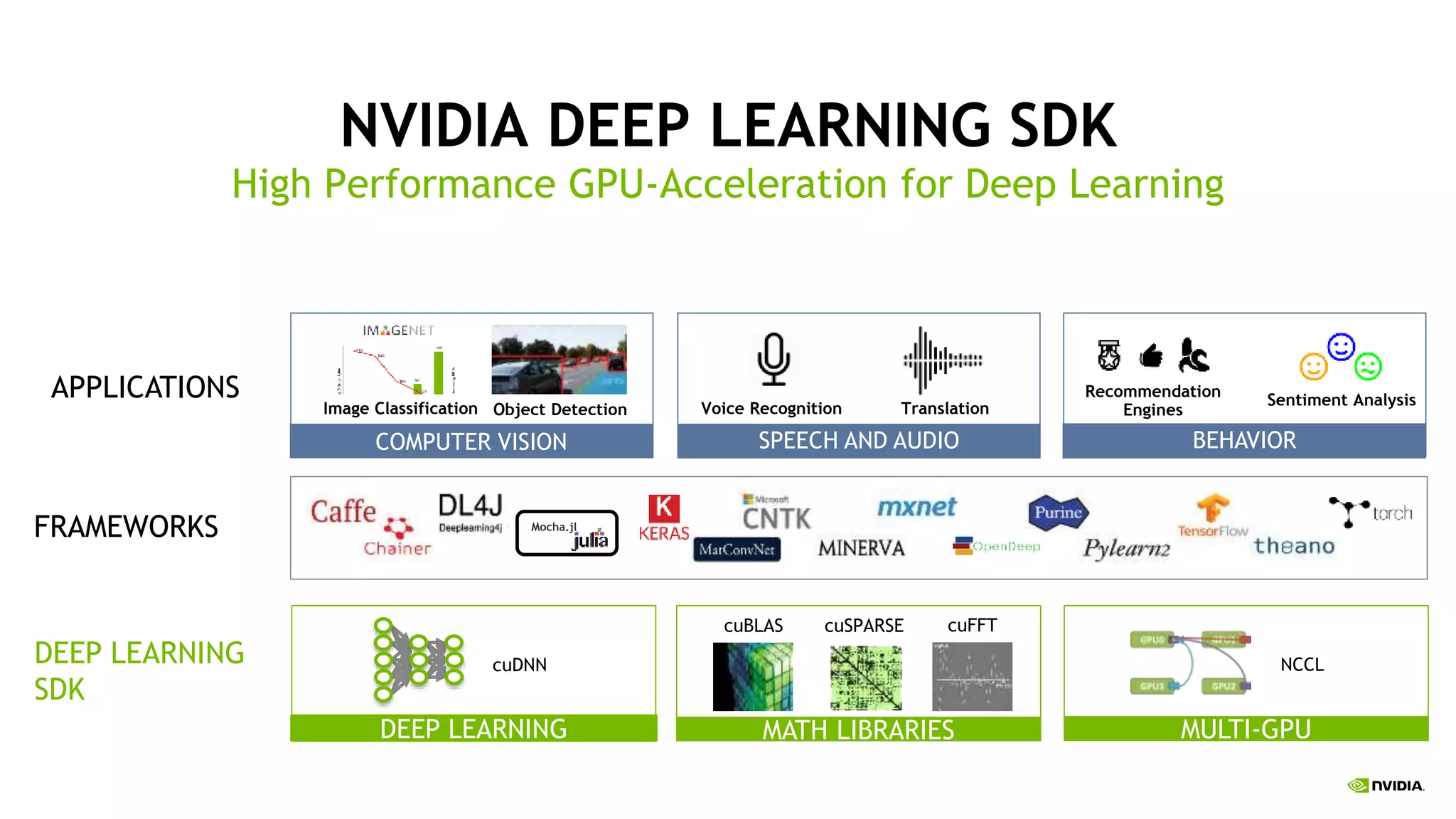




The document provides an update on deep learning and announcements from NVIDIA's GPU Technology Conference (GTC16). It discusses achievements in deep learning like object detection surpassing human-level performance. It also summarizes NVIDIA's latest products like the DGX-1 deep learning supercomputer, Tesla P100 GPU, and improvements to tools like cuDNN that accelerate deep learning. The document emphasizes how these announcements and products will help further progress in deep learning research and applications.





































![OS in mobile devices [Android]](https://cdn.slidesharecdn.com/ss_thumbnails/osinmobiledevices11-141129052006-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)

































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)















