Download as PDF, PPTX



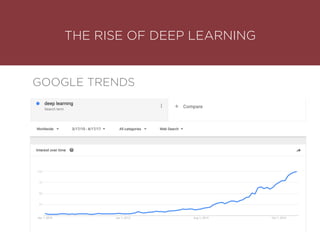

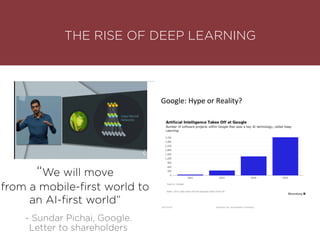
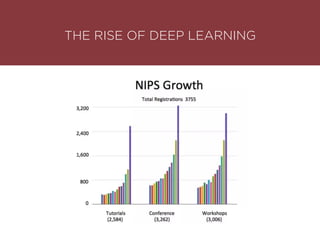







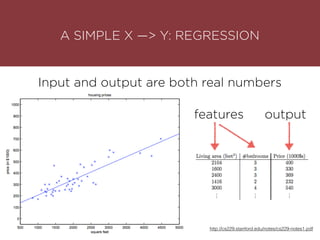
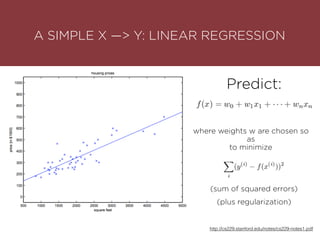
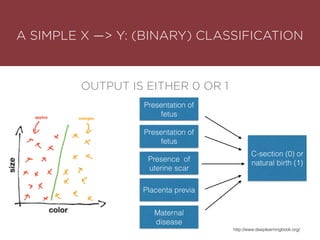
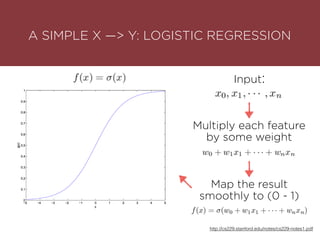
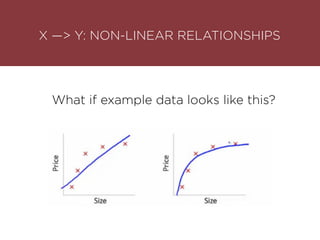
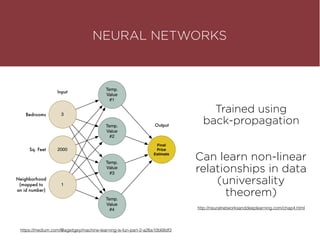
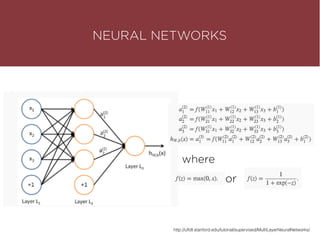
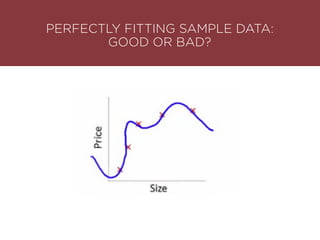
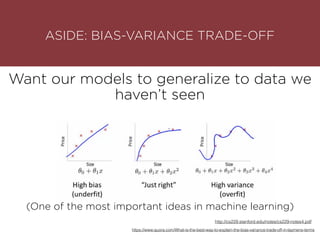
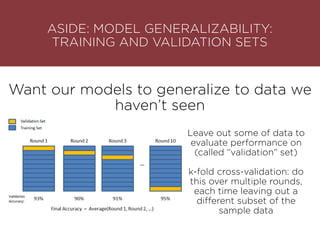
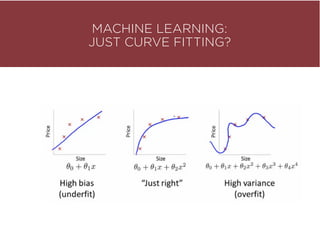









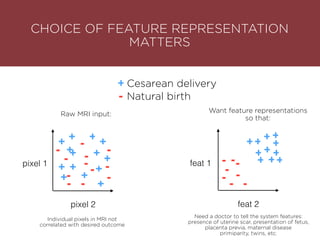





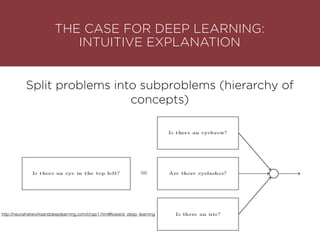




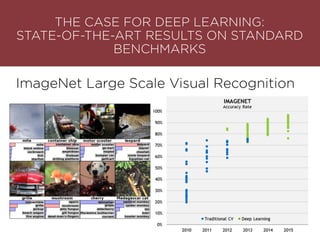
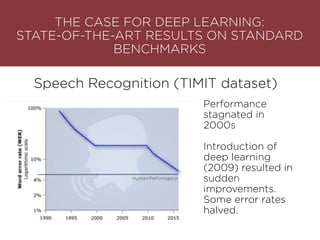
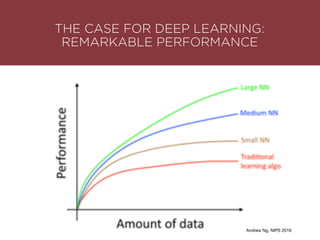
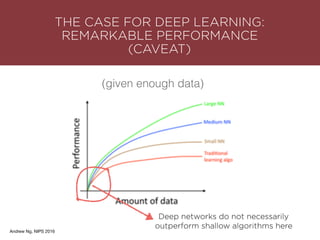





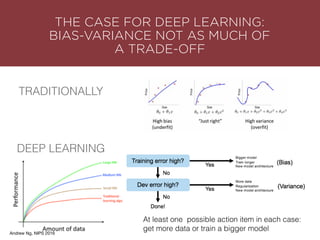



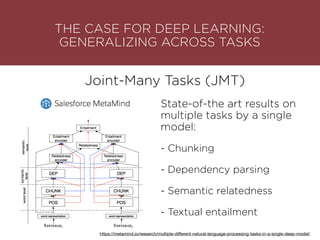


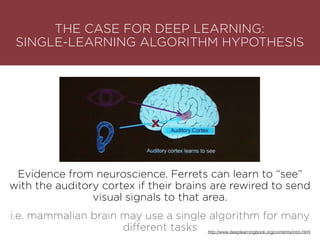

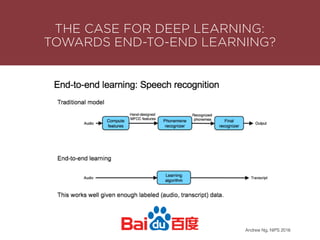
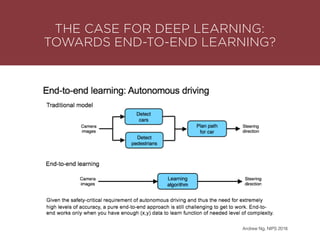




The presentation by Maurizio Caló Caligaris at NYU's Center for Genomics outlines the fundamentals of deep learning, emphasizing its rise and significance in transitioning from a mobile-first to an AI-first world. It discusses key concepts such as supervised learning, the bias-variance tradeoff, and the advantages of automatic feature representation without human input. Additionally, it highlights the current state of deep learning, including its performance improvements across various benchmarks and tasks, supported by advancements in computation and data availability.



































































