Downloaded 26 times




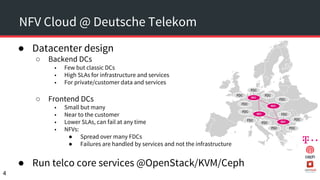





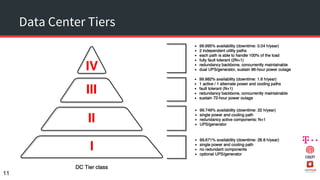

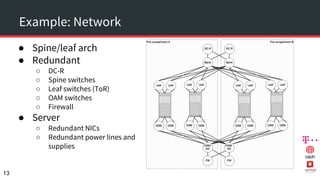

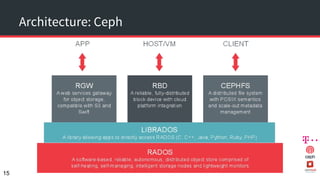

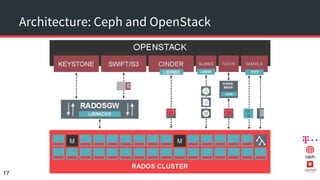


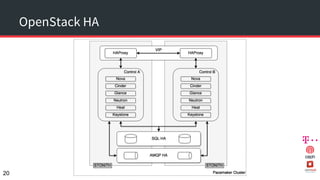



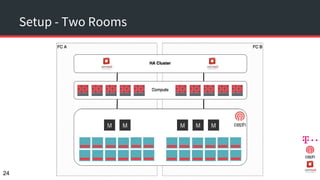
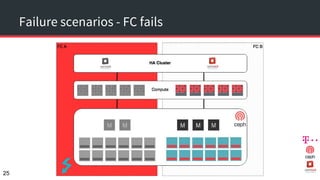
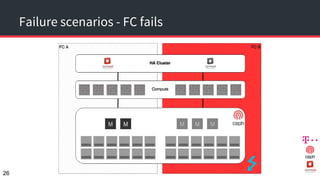
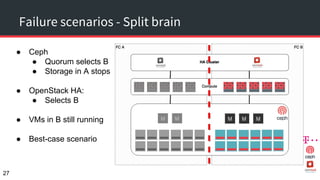
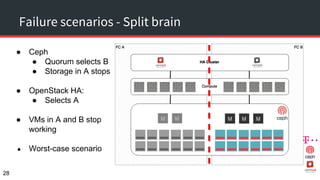

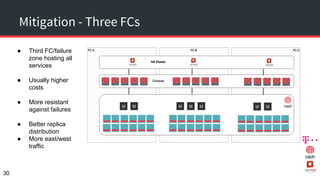
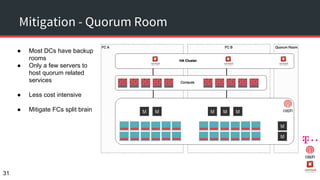




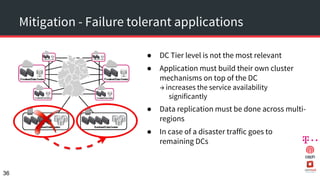






The document discusses achieving 99.999% availability in OpenStack using Ceph, focusing on data center designs, high availability (HA) components, and failure scenarios. It emphasizes the importance of careful planning, redundancy, and quorum in maintaining system stability and service continuity. Additionally, it highlights that while five nines availability is challenging and costly, effective application design and infrastructure can significantly improve service availability.








































































