Download as PDF, PPTX

















![GET THE RIGHT TOOL
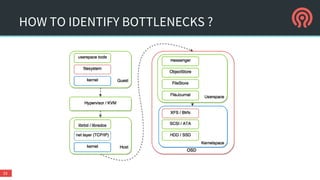
● Ceph performance tool not fully reliable for deep analysis
● Needed a tool to analyse all layers rbd.ko, librbd, block devices and files
○ Don’t reinvent the wheel !
○ There is a “swiss army knife” - fio
○ Contributed RBD support for fio upstream
○ Other helpers: blktrace, systemtap
34
“Get Jens' FIO code. It does things right, including writing
actual pseudo-random contents, which shows if the disk
does some de-duplication (aka optimize for
benchmarks): [...] Anything else is suspect - forget about
bonnie or other traditional tools.”
Linus Torvalds](https://image.slidesharecdn.com/jpcaaut3txuwlecn35t5-signature-da0a38e0f2f3ce79540b8d50f57be5eda35f667da69f636cd1c13d3acef124ec-poli-151122203535-lva1-app6892/85/Linux-Stammtisch-Munich-Ceph-Overview-Experiences-and-Outlook-34-320.jpg)



















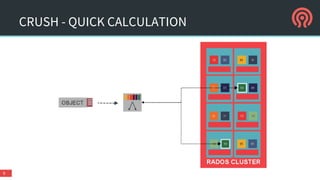
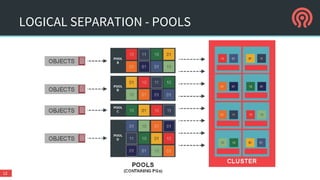
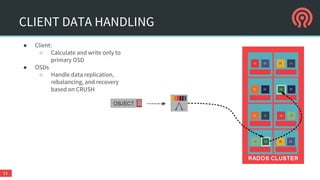
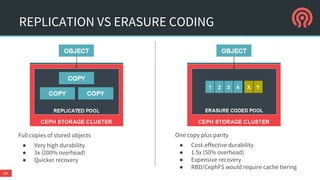
The document is a presentation by Danny Al-Gaaf on Ceph, covering its architecture, experiences, and future outlook, particularly in relation to OpenStack. It highlights the advantages of software-defined storage, including scalability, fault tolerance, and cost-effectiveness, while discussing performance, support, security, and high availability aspects. The conclusions suggest that Ceph is suitable for enterprise usage, especially with ongoing improvements in security and operational features.












































































