Downloaded 84 times




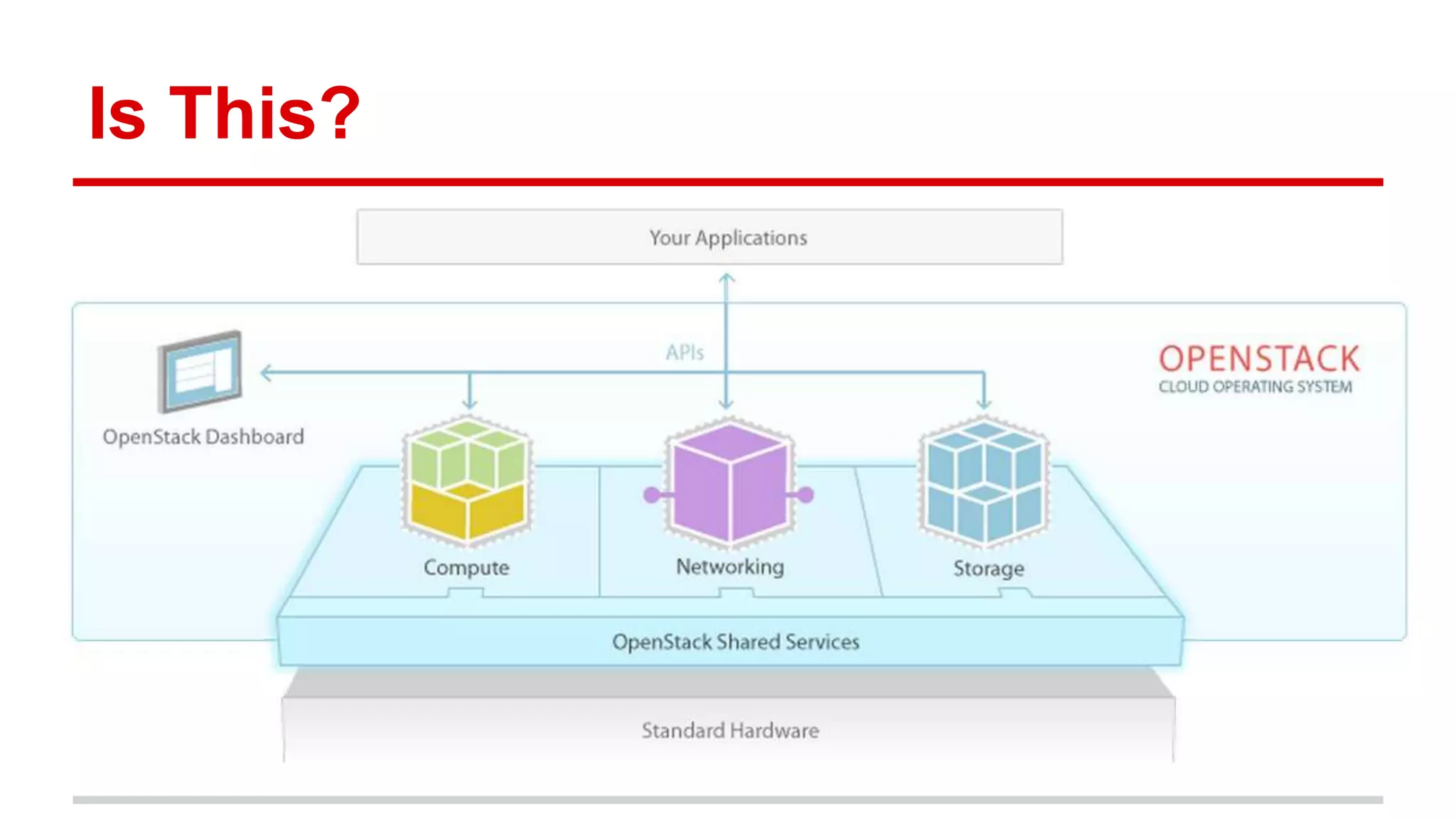







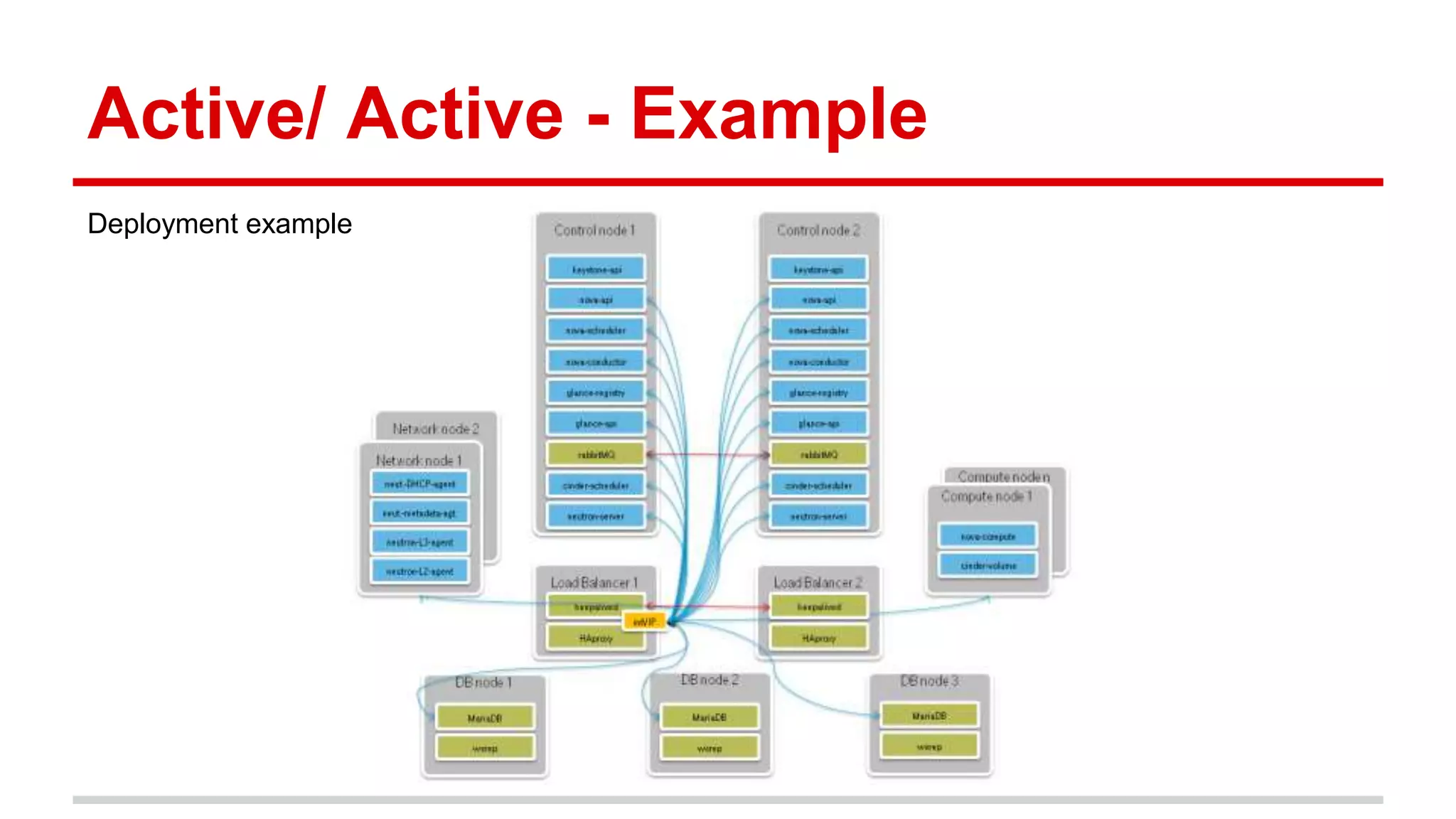



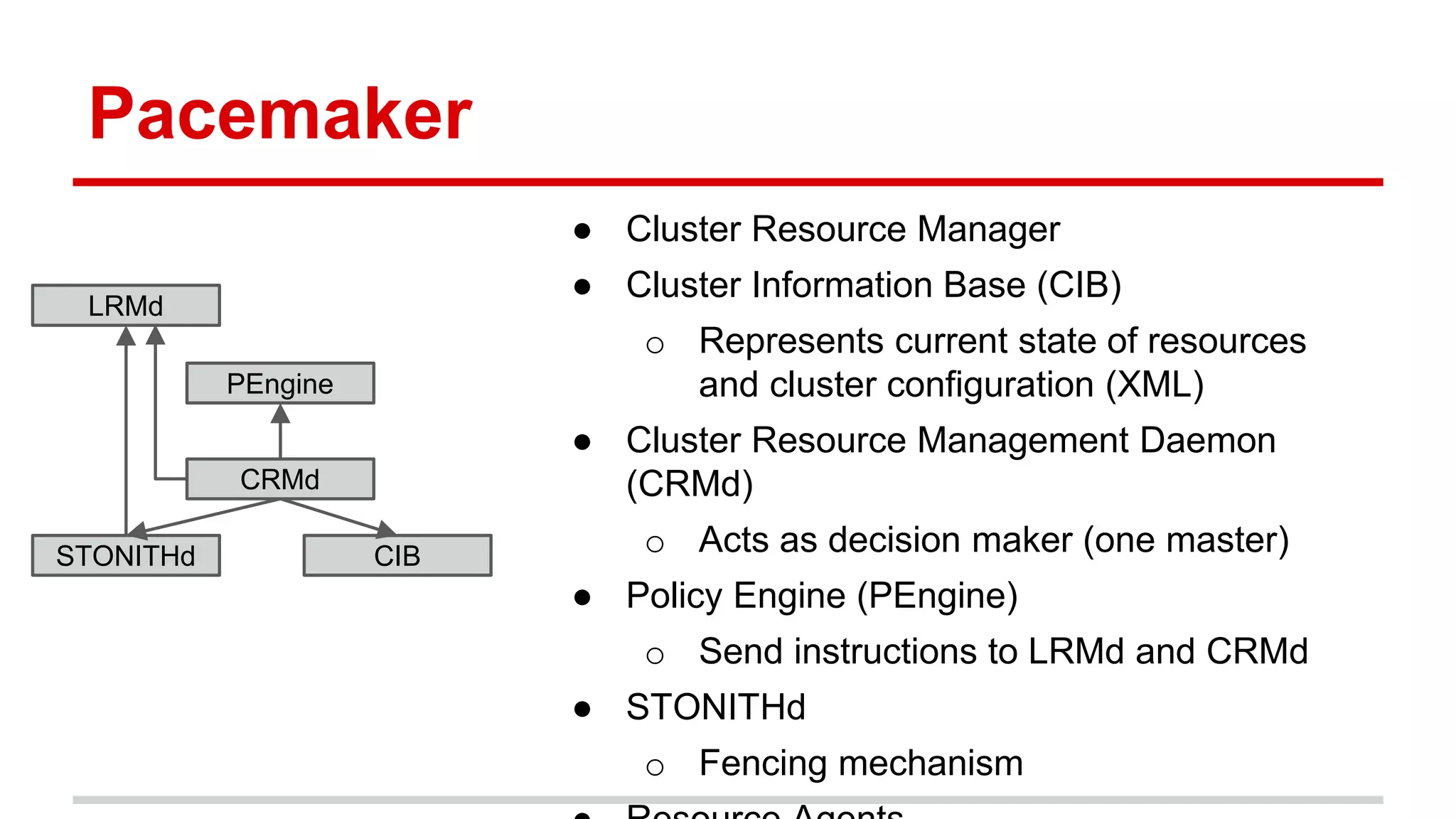

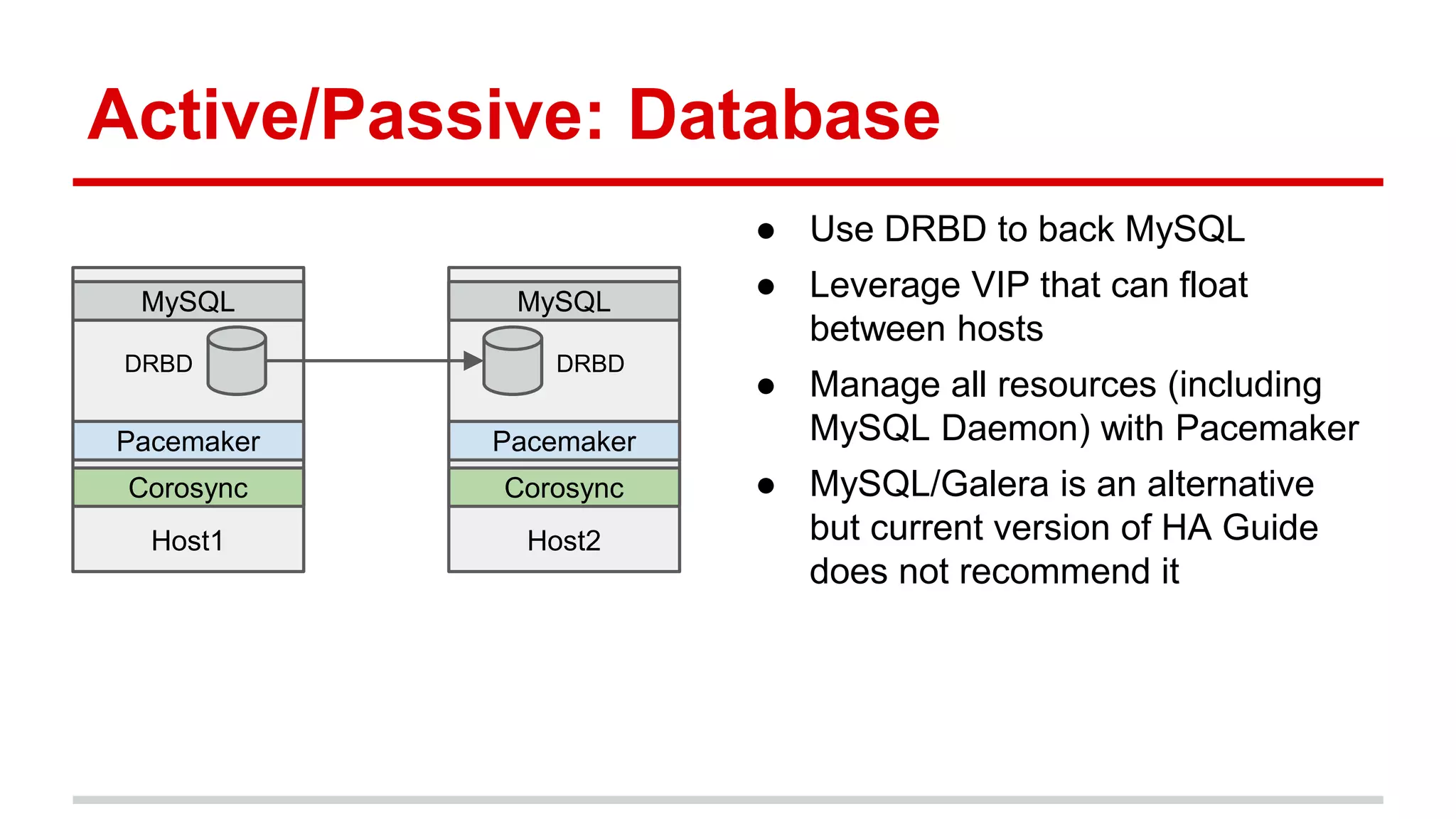
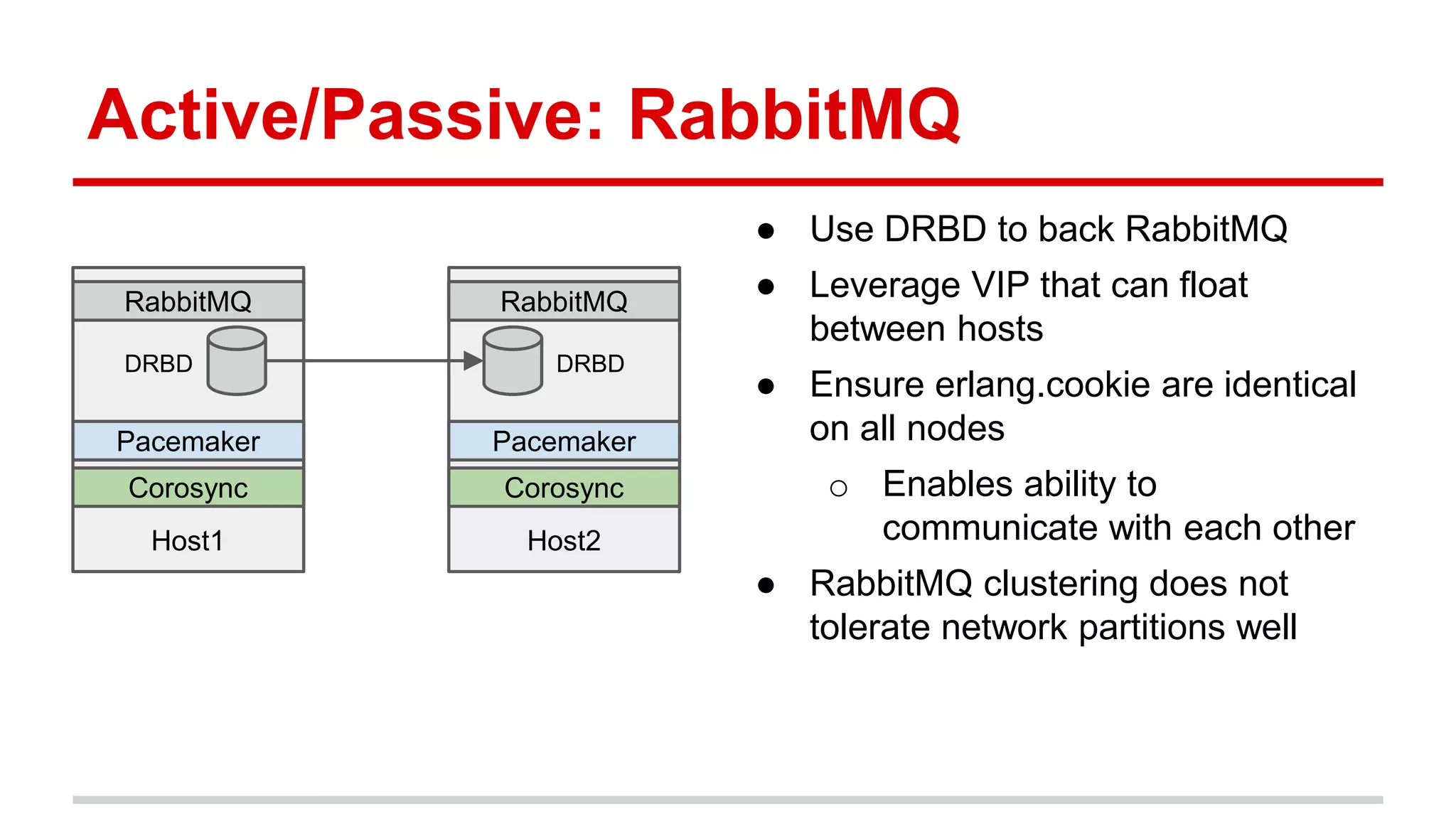












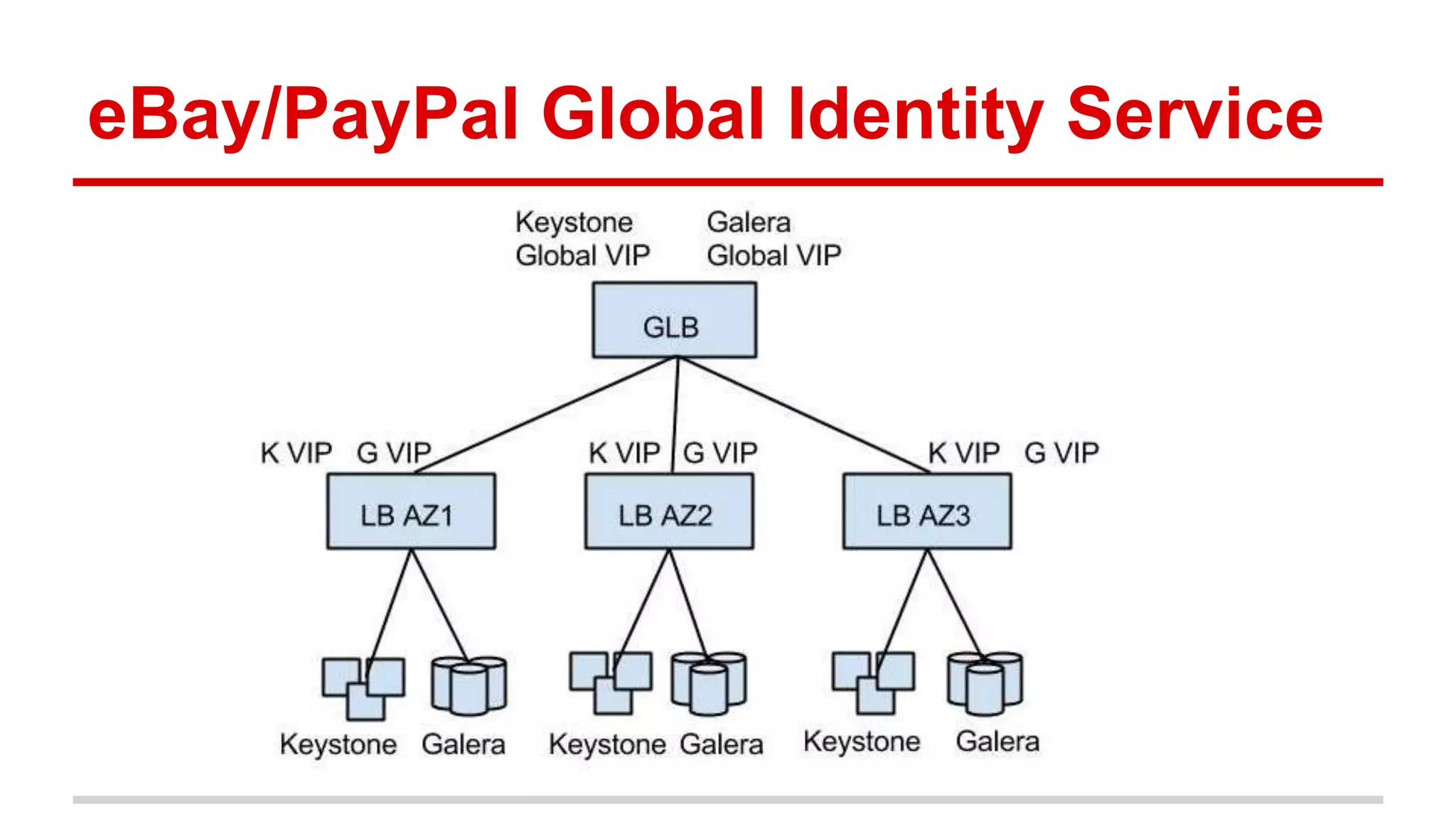




This document discusses various approaches to implementing high availability (HA) in OpenStack including active/active and active/passive configurations. It provides an overview of HA techniques used at Deutsche Telekom and eBay/PayPal including load balancing APIs and databases, replicating RabbitMQ and MySQL, and configuring Pacemaker/Corosync for OpenStack services. It also discusses lessons learned around testing failures, placing services across availability zones, and having backups for HA infrastructures.















































































