Downloaded 50 times



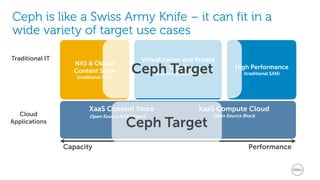
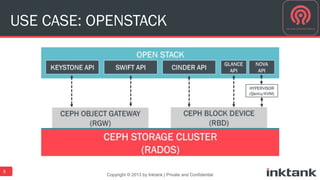
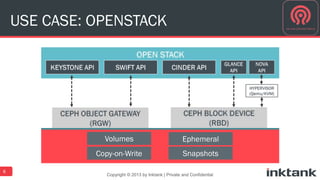
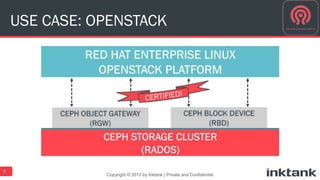
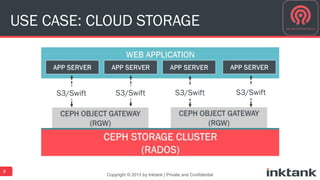
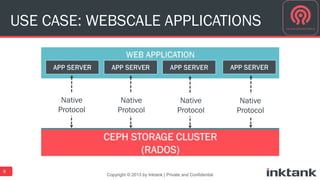
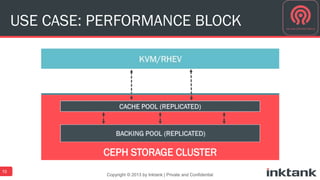
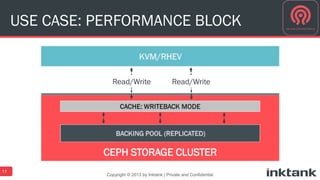
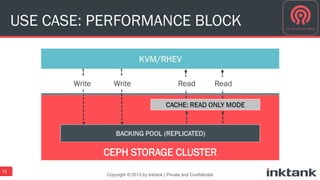











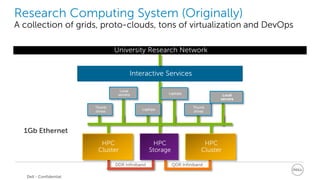

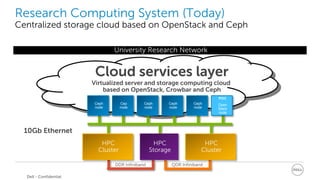

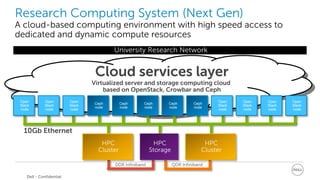




This document discusses best practices for implementing Ceph-powered storage as a service. It covers planning a Ceph implementation based on business and technical requirements. Various use cases for Ceph are described, including OpenStack, cloud storage, web-scale applications, high performance block storage, archive/cold storage, databases and Hadoop. Architectural considerations for redundancy, servers, networking are also discussed. The document concludes with a case study of a university implementing a Ceph-based storage cloud to address storage needs for cancer and genomic research data.






















































































