Downloaded 36 times












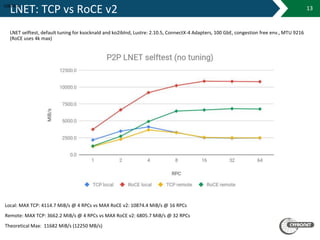



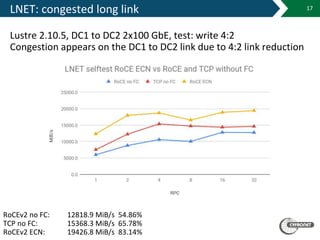

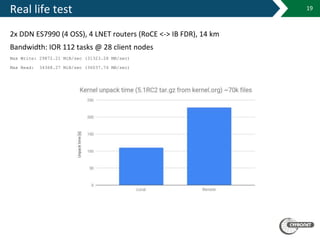




The document details the capabilities and infrastructure of the Academic Computer Centre Cyfronet AGH, which is the largest academic computing center in Poland with over 45 years of experience. It highlights their supercomputers, Prometheus and Zeus, as well as their leadership in Polish grid and cloud infrastructure for scientific purposes. The document also discusses various technical aspects of their networking and computing services, including advancements in RoCE technology and its performance compared to TCP.



















![[232] 성능어디까지쥐어짜봤니 송태웅](https://cdn.slidesharecdn.com/ss_thumbnails/232-161025013504-thumbnail.jpg?width=640&height=640&fit=bounds)



































































