Downloaded 19 times








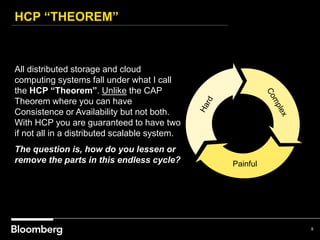
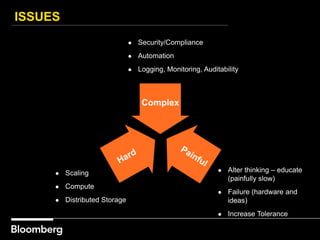
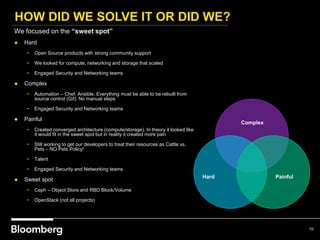

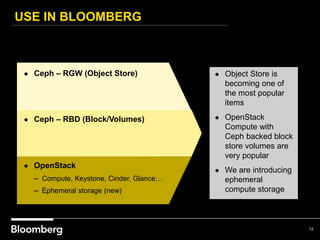
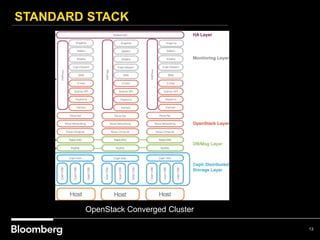

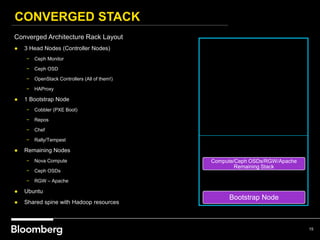
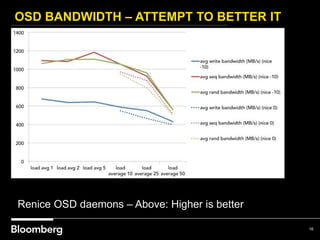
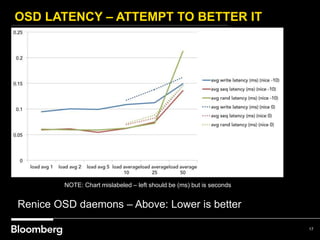

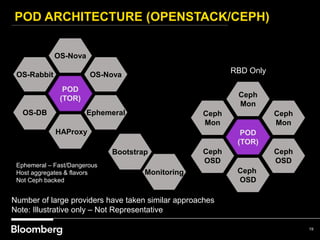
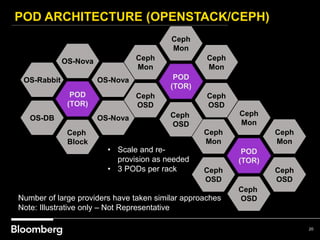
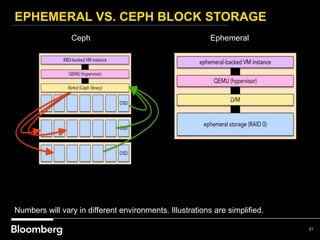

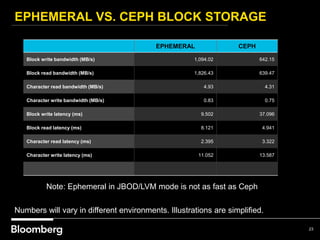

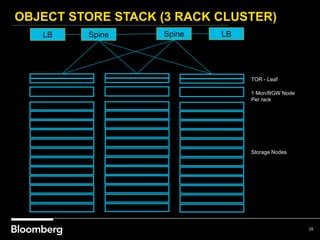
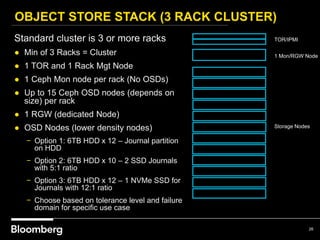







This document provides an overview of how Bloomberg uses Ceph and OpenStack in its cloud infrastructure. Some key points: - Bloomberg uses Ceph for object storage with RGW and block storage with RBD. It uses OpenStack for compute functions. - Initially Bloomberg had a fully converged architecture with Ceph and OpenStack on the same nodes, but this caused performance issues. - Bloomberg now uses a semi-converged "POD" architecture with dedicated Ceph and OpenStack nodes in separate clusters for better scalability and performance. - Ephemeral storage provides faster performance than Ceph but lacks data integrity protections. Ceph offers replication and reliability at the cost of some latency. - Automation with Chef











































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)











