Download as PDF, PPTX











![16©2017 Open-NFP
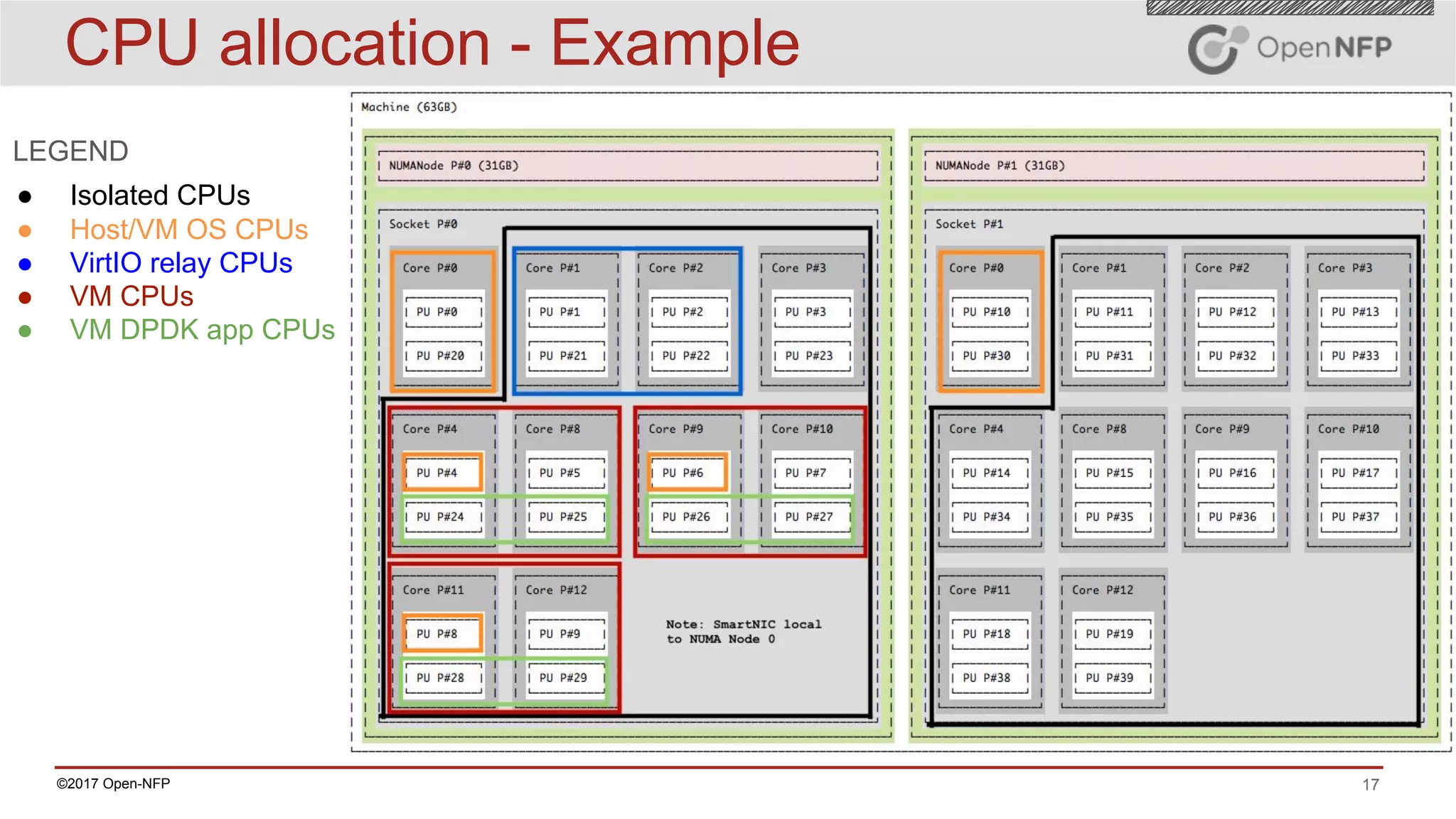
● CRITICAL - Do not use the same CPU for more than one task
● Isolate and pin CPUs dedicated for critical tasks
● Pin VMs to unique CPUs
■ vcpupin <domain> [--vcpu <number>] [--cpulist <string>]
● Pin DPDK apps to unique CPUs (or logical cores in VM)
○ use -c <coremap> or --l <corelist> to specify CPUs DPDK app uses
CPU affinity and pinning](https://image.slidesharecdn.com/measuringa25and40gbpsdataplane-170615124700/75/Measuring-a-25-and-40Gb-s-Data-Plane-16-2048.jpg)

![19©2017 Open-NFP
BIOS settings (2/3)
● Correct setting of BIOS for DUT (w/ SmartNIC) is important, to address:
○ Throughput variations due to CPU power state changes (C-state; P-state)
○ Blips (short duration packet drops) due to interrupts (SMI)
● Example settings (HP) changes - settings will vary from BIOS to BIOS
● Power Management
○ Power Regulator = [Static High Performance] (was “dynamic power
savings”)
○ Minimum Processor Core Idle C-state = [No C-states] (was C-6)
○ Minimum Package Idle C-state = [ No package state] (was C-6)
○ Power Profile = [ Max Performance ] (was “customer”) this ended up setting the
above anyway (and graying them out)
● Prevent CPUs from entering power savings modes as transitions cause OS and VM drivers to
drop packets.](https://image.slidesharecdn.com/measuringa25and40gbpsdataplane-170615124700/75/Measuring-a-25-and-40Gb-s-Data-Plane-19-2048.jpg)
![20©2017 Open-NFP
BIOS settings (3/3)
● Example settings (HP) changes (cont.)
● SMI - System Management Interrupts
○ Memory pre-failure notification = [disabled] (was enabled)
● When enabled, CPU is periodically interrupted, resulting in packet drops when close to throughput
capacity.
● Disable all non-essential SMIs
● Frequency of SMI varies
■ On an HP DL380 gen9 it is every 60s
■ On gen6,7 it is every hour
■ On gen8 every 5 minutes](https://image.slidesharecdn.com/measuringa25and40gbpsdataplane-170615124700/75/Measuring-a-25-and-40Gb-s-Data-Plane-20-2048.jpg)



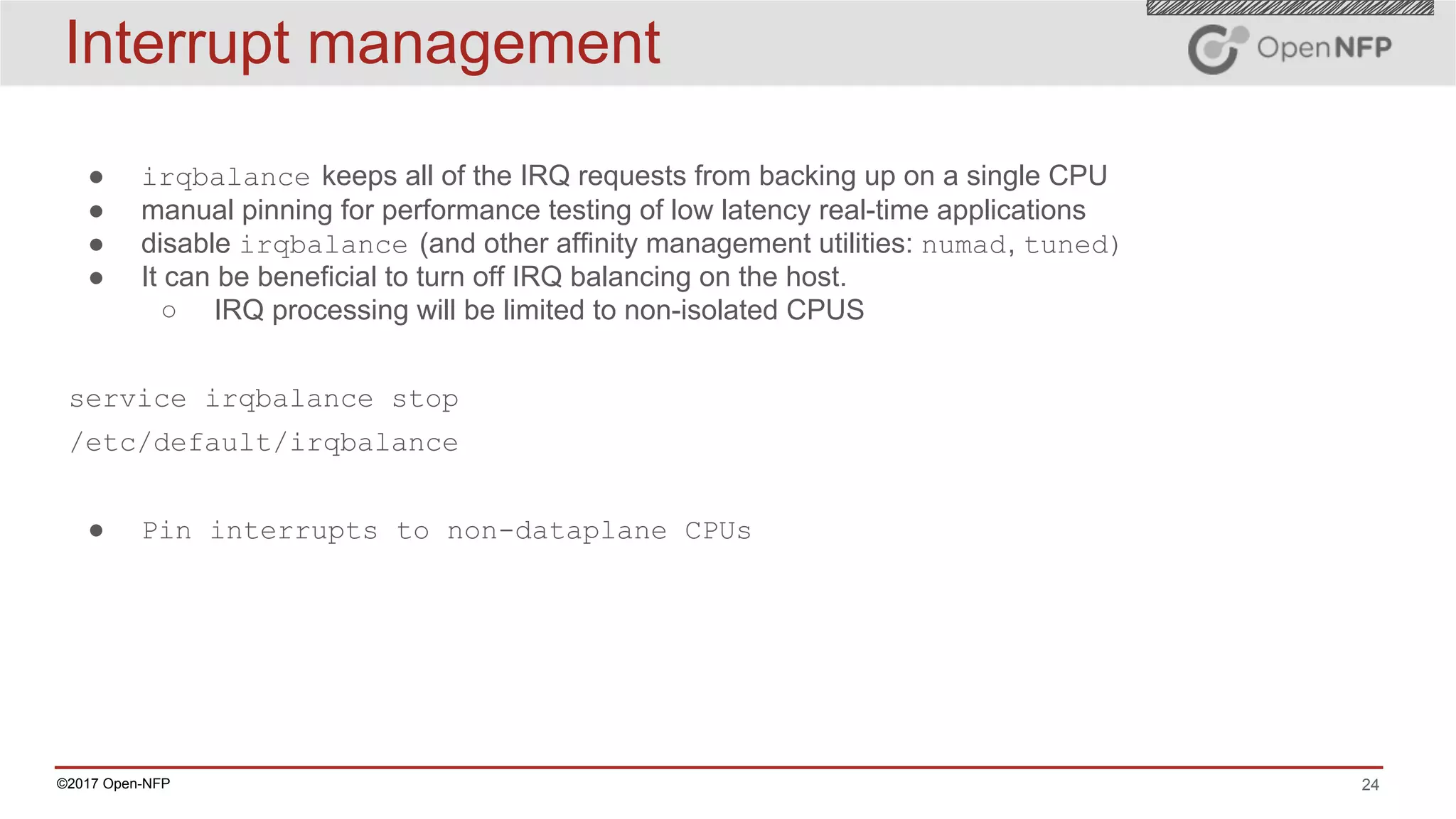

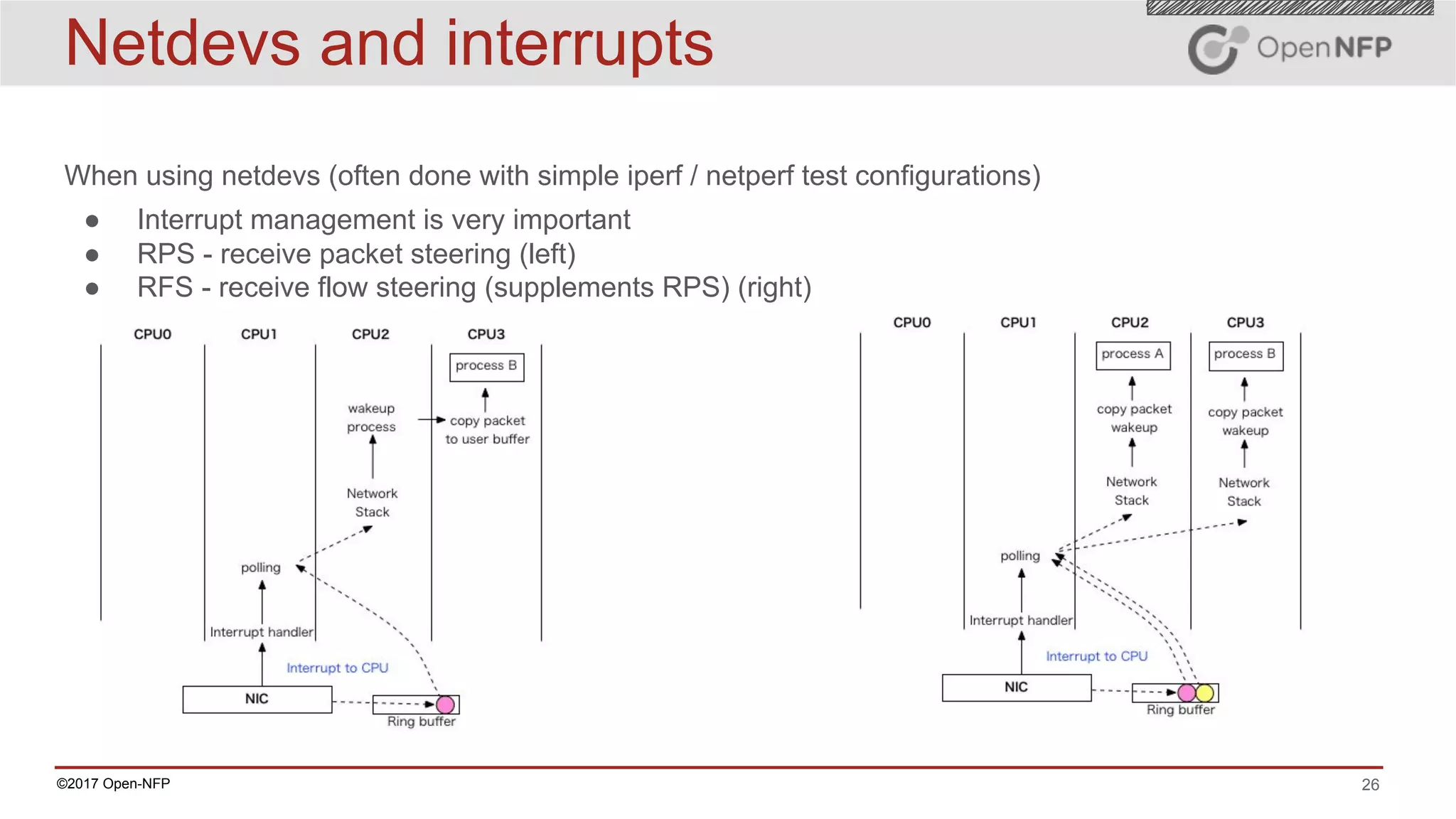


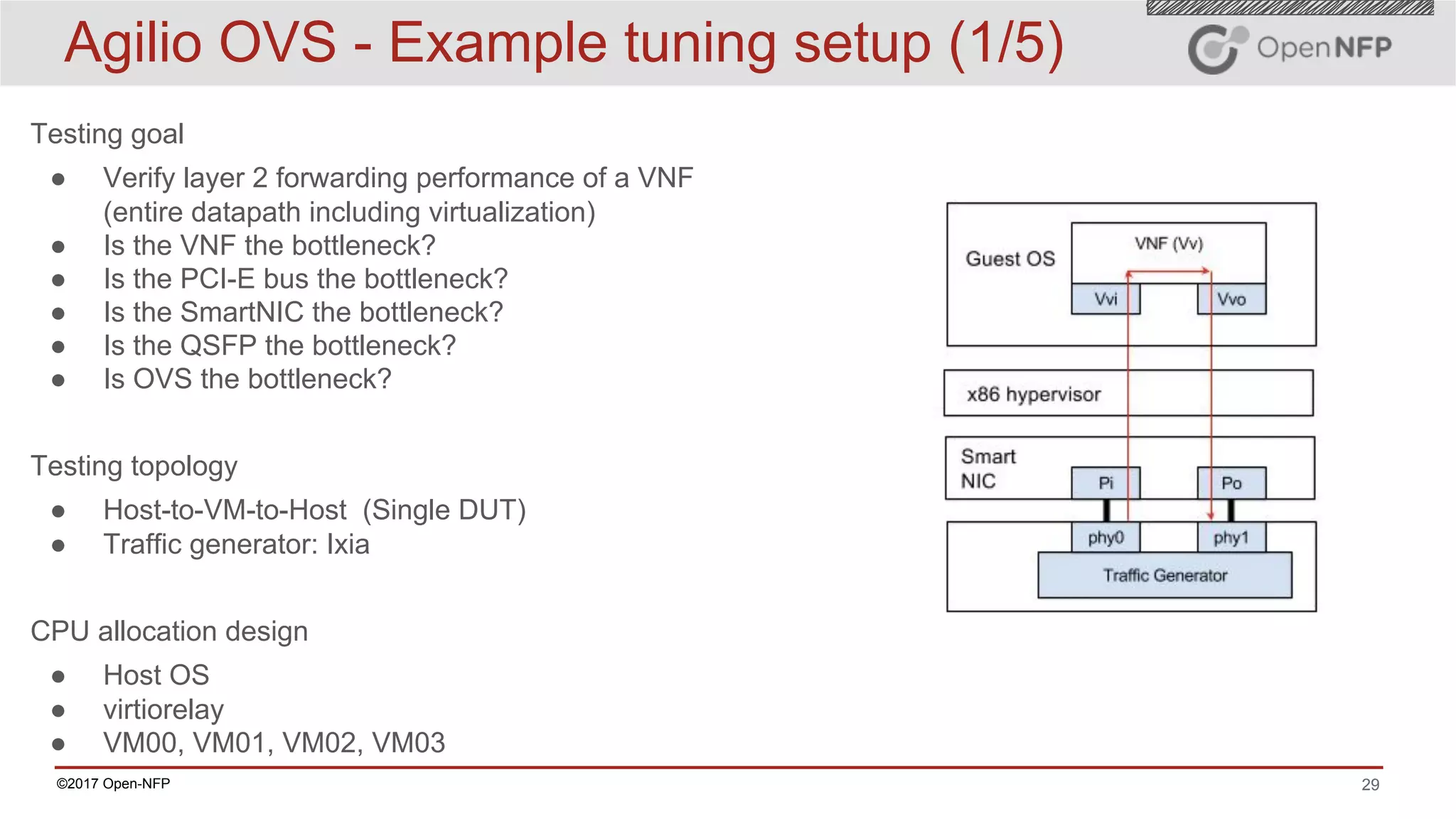





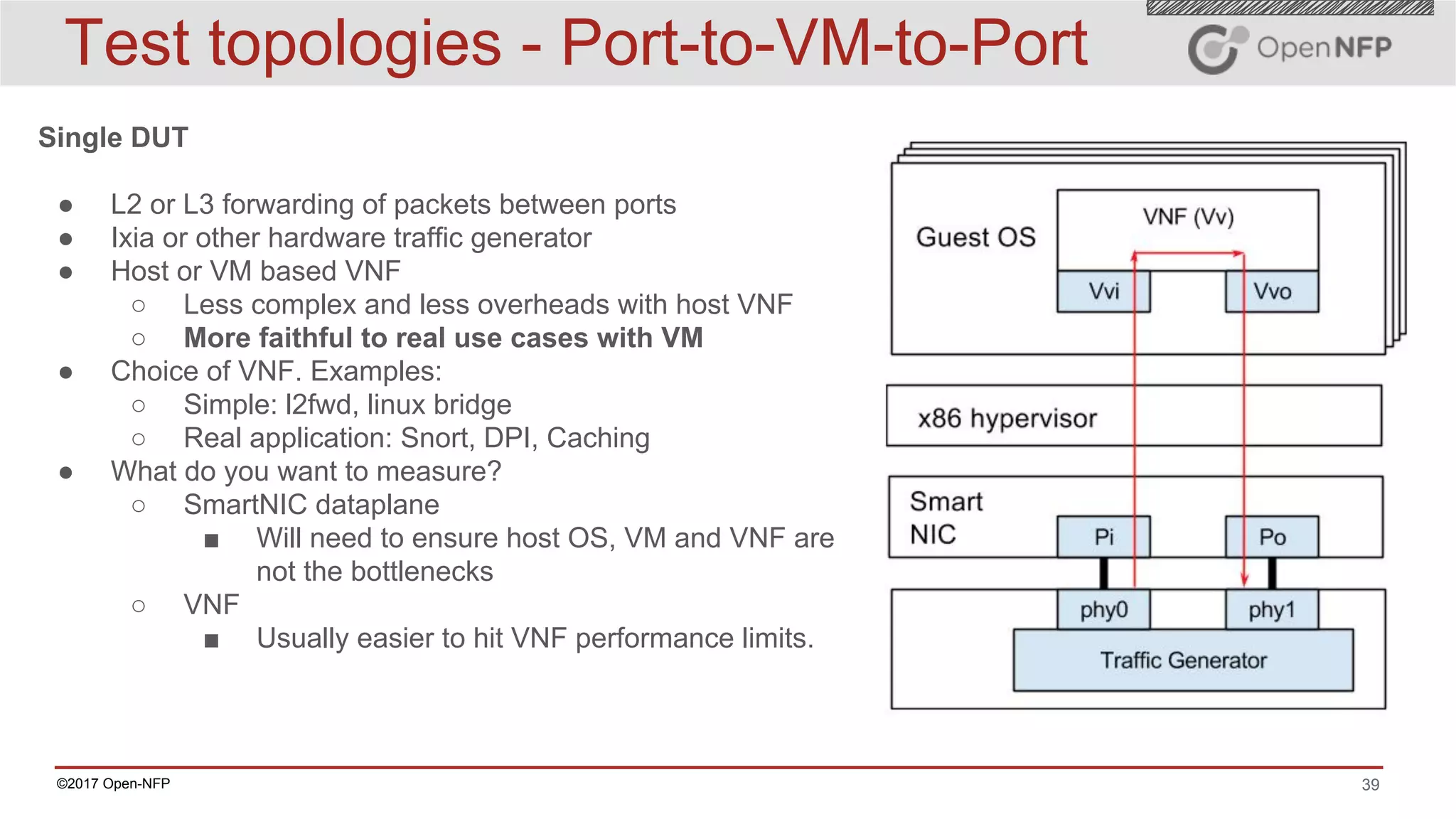

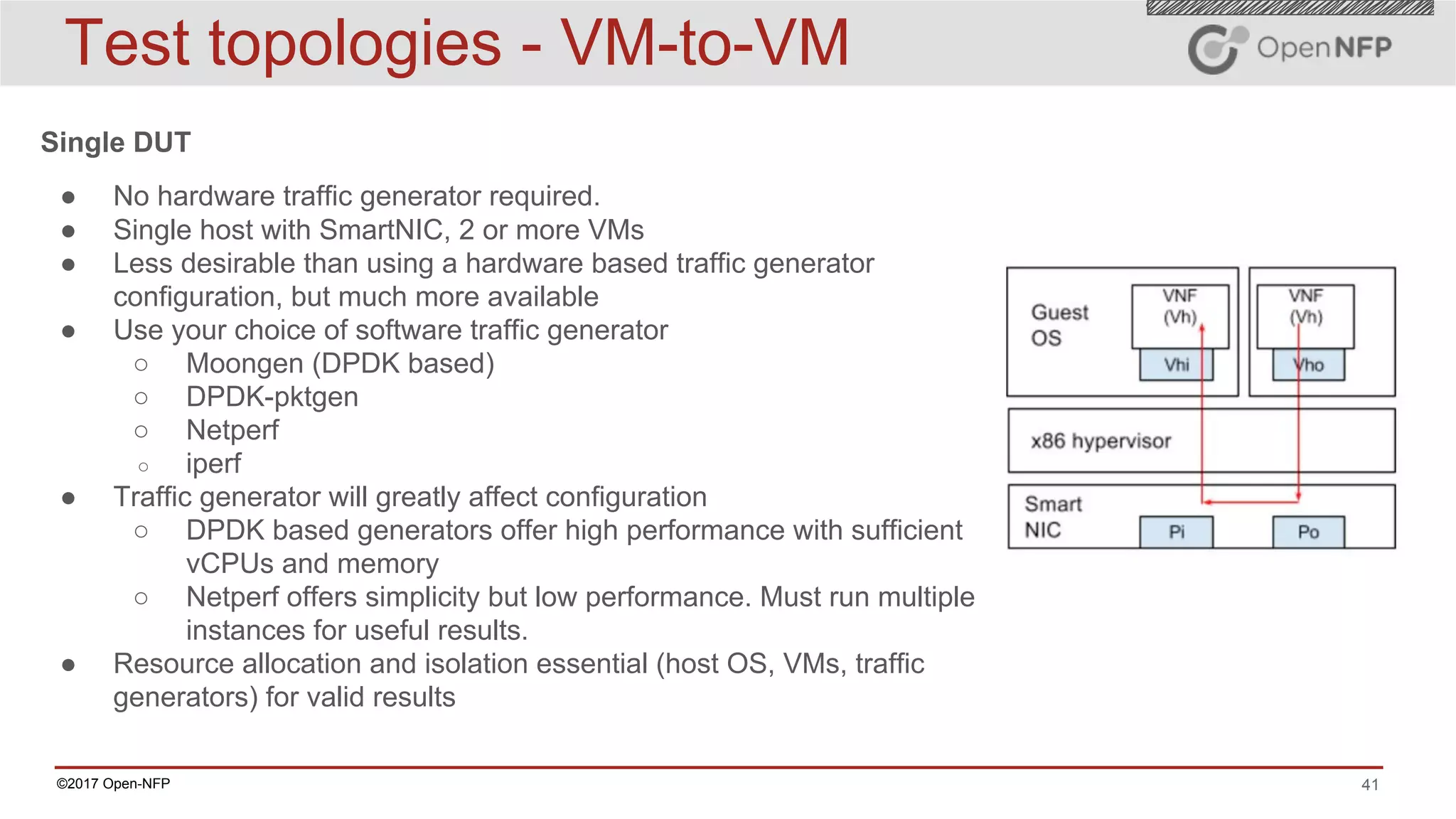
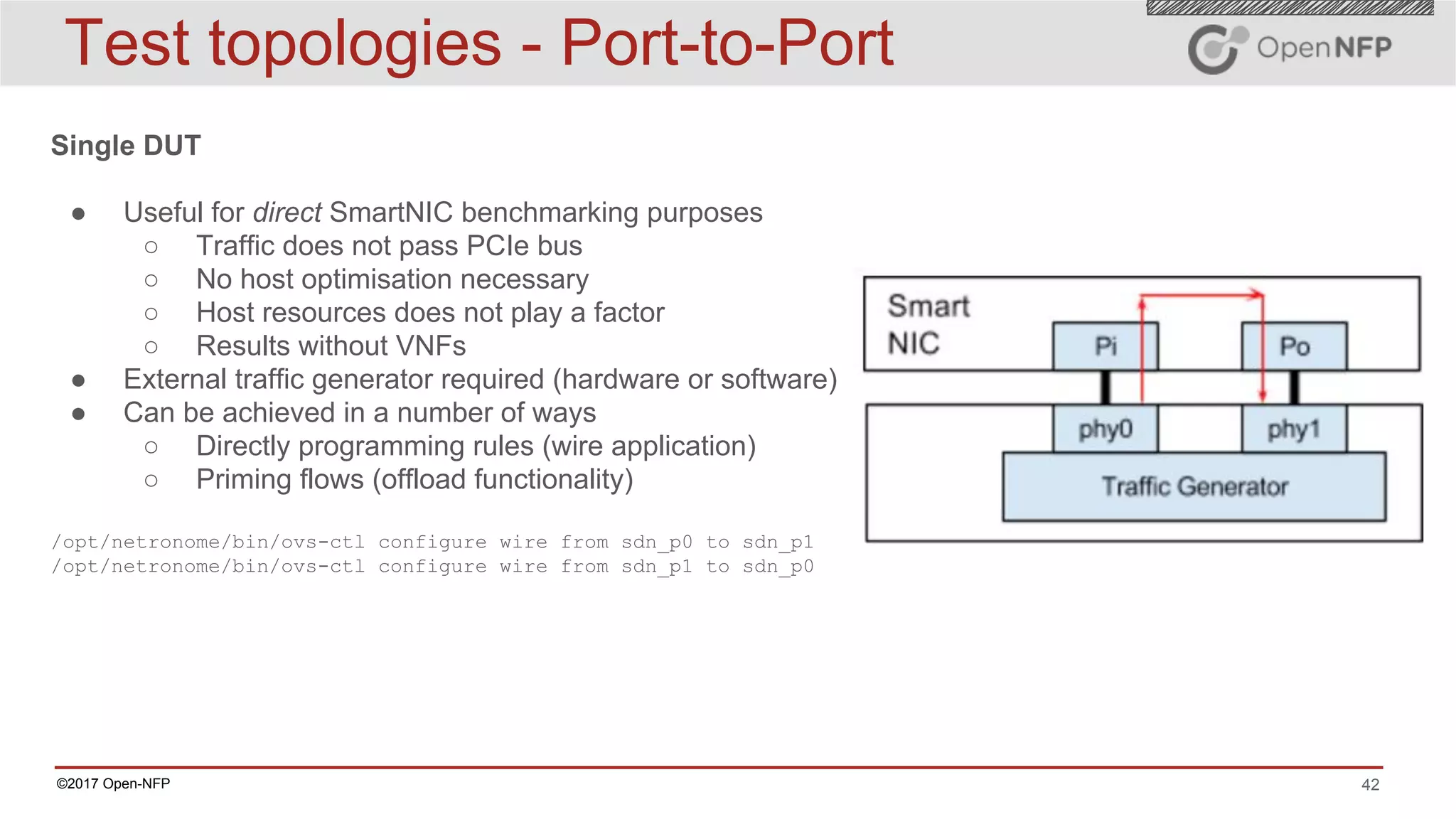
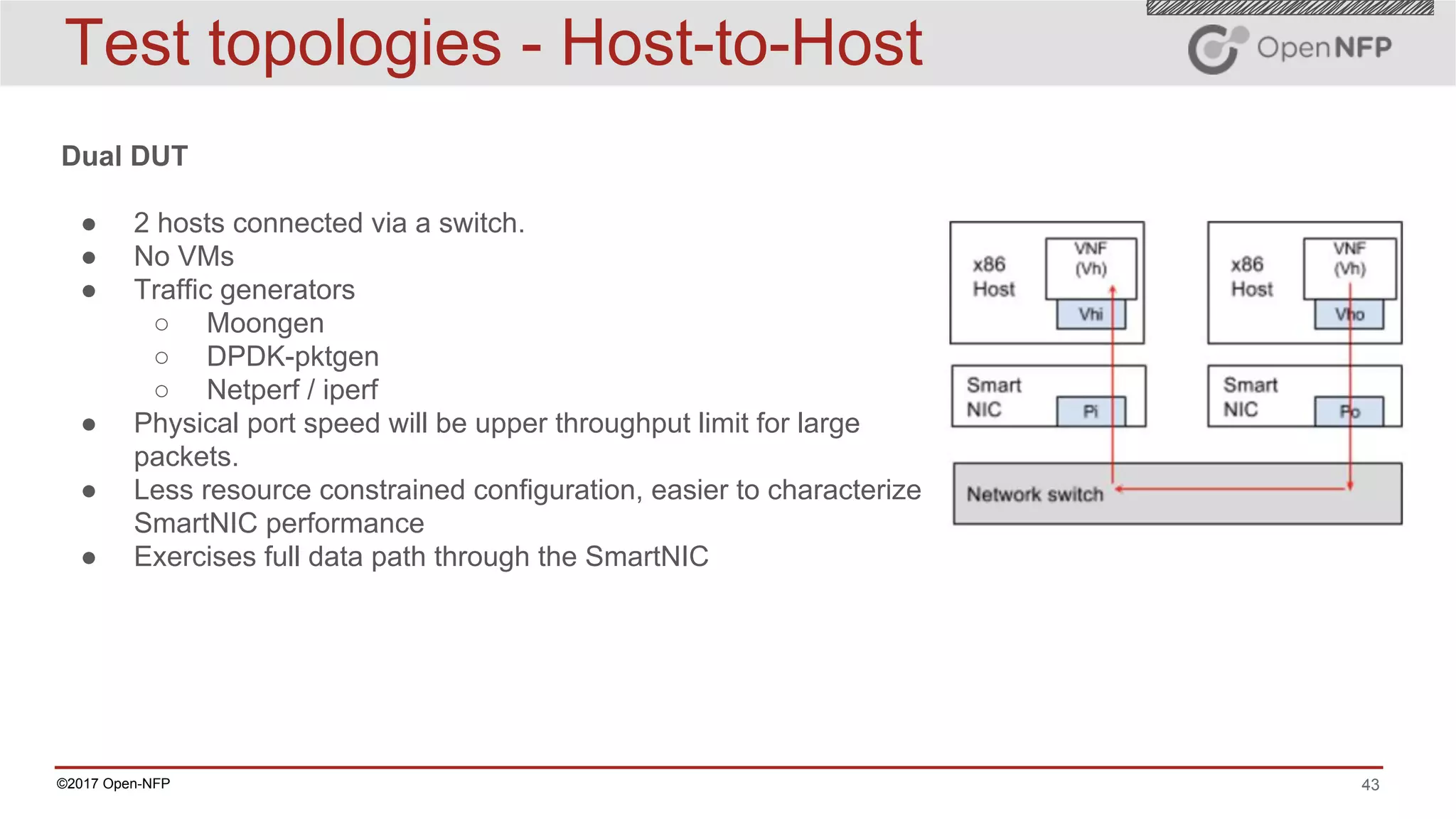
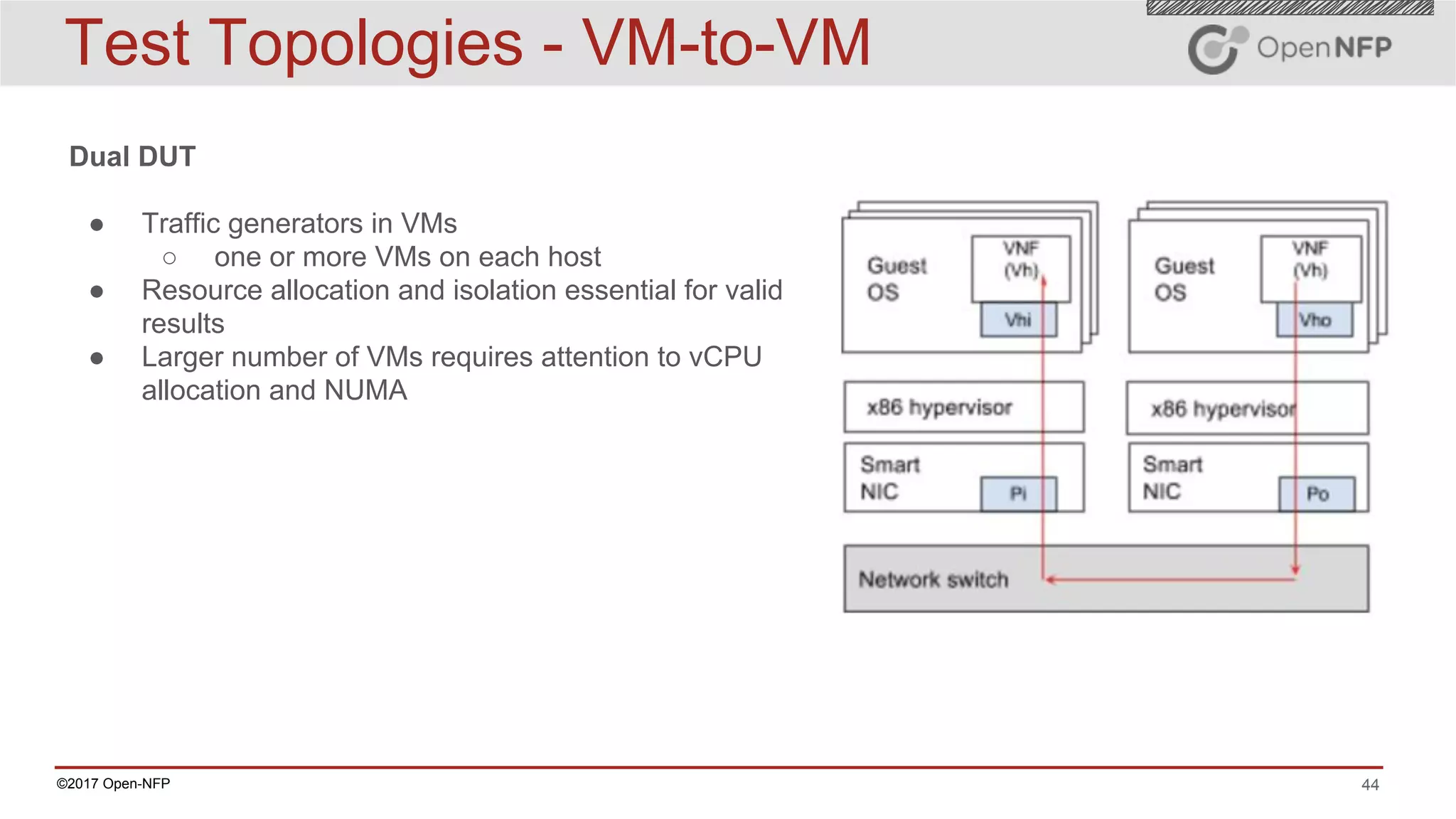

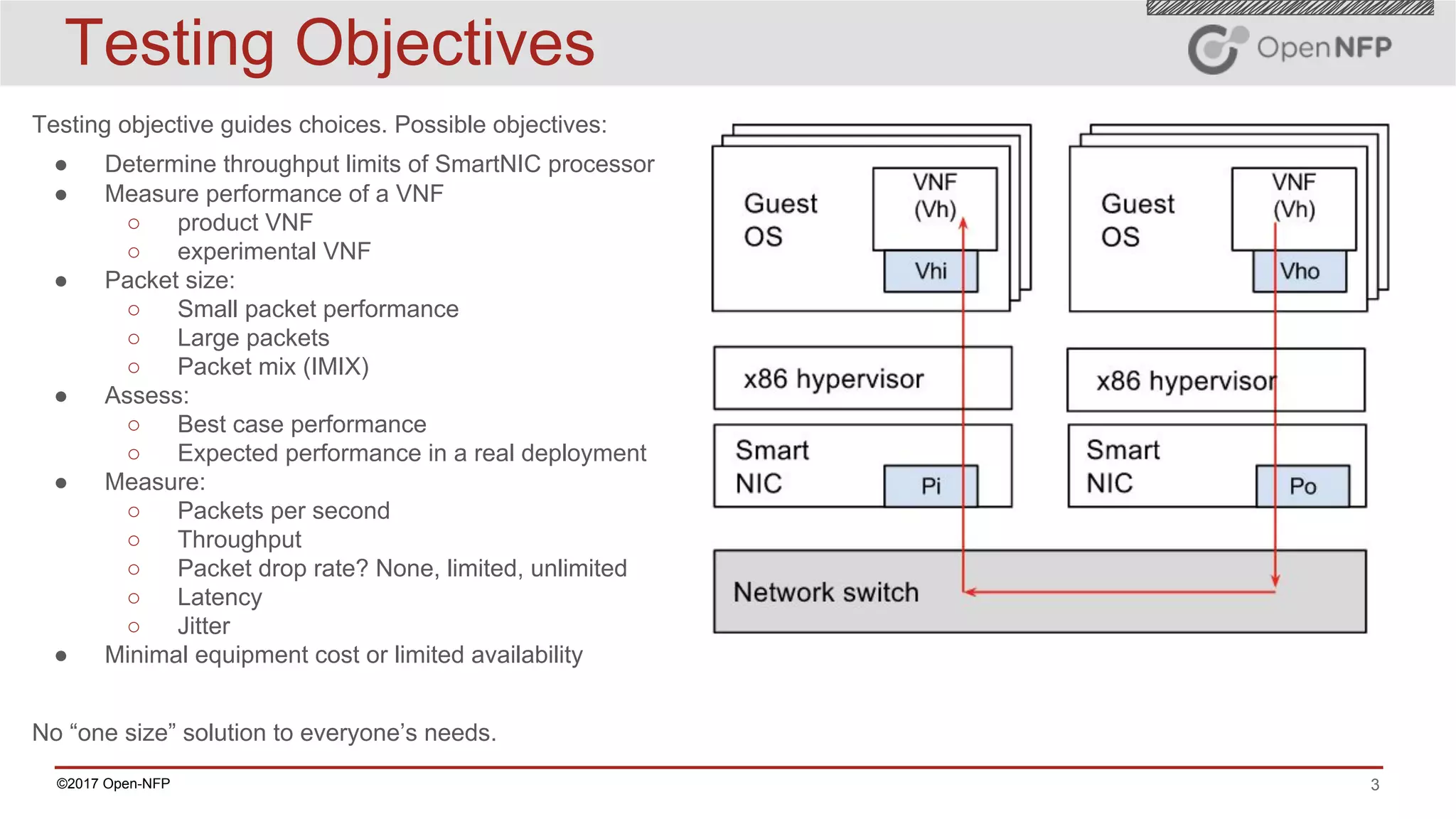
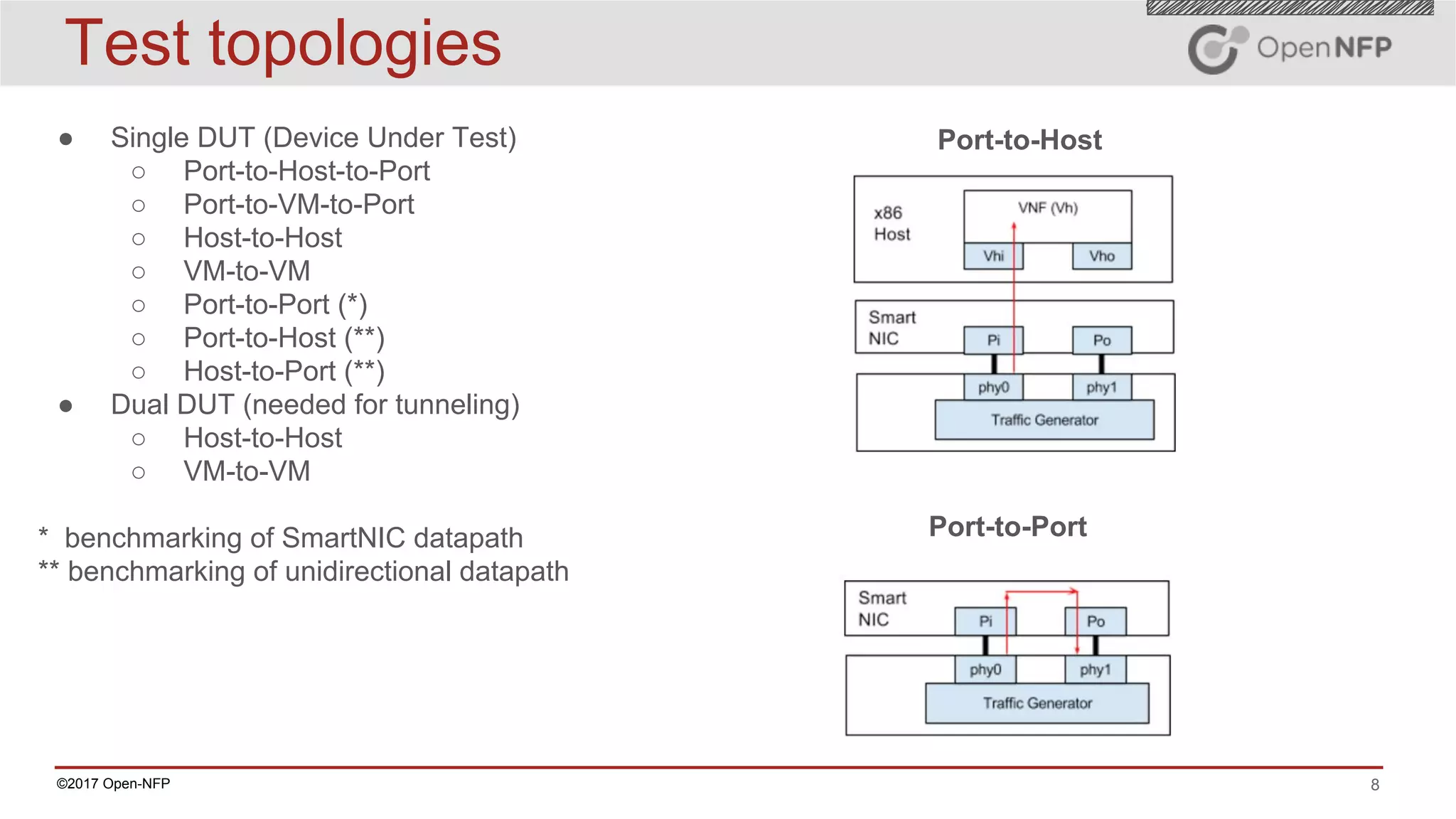
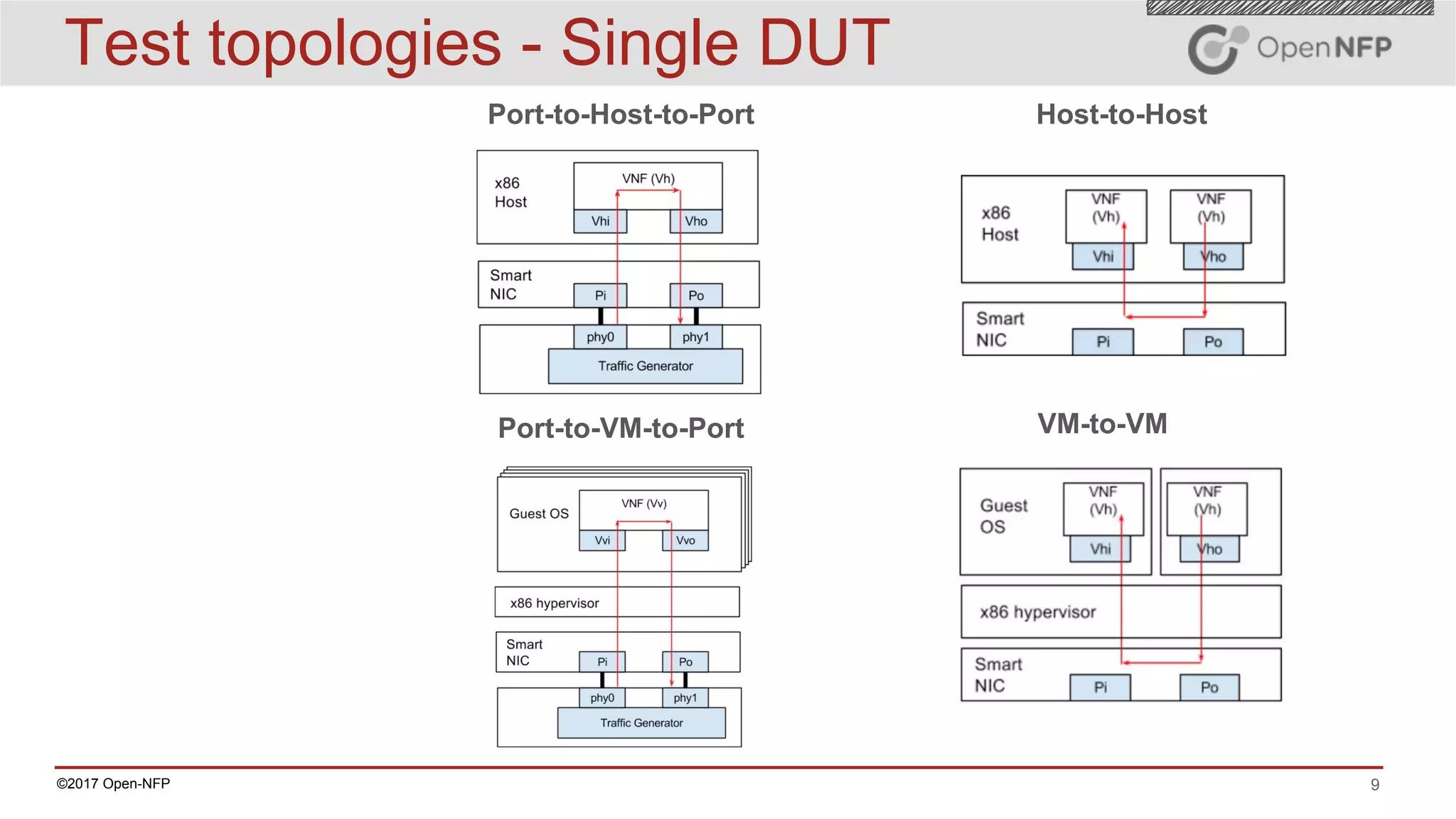
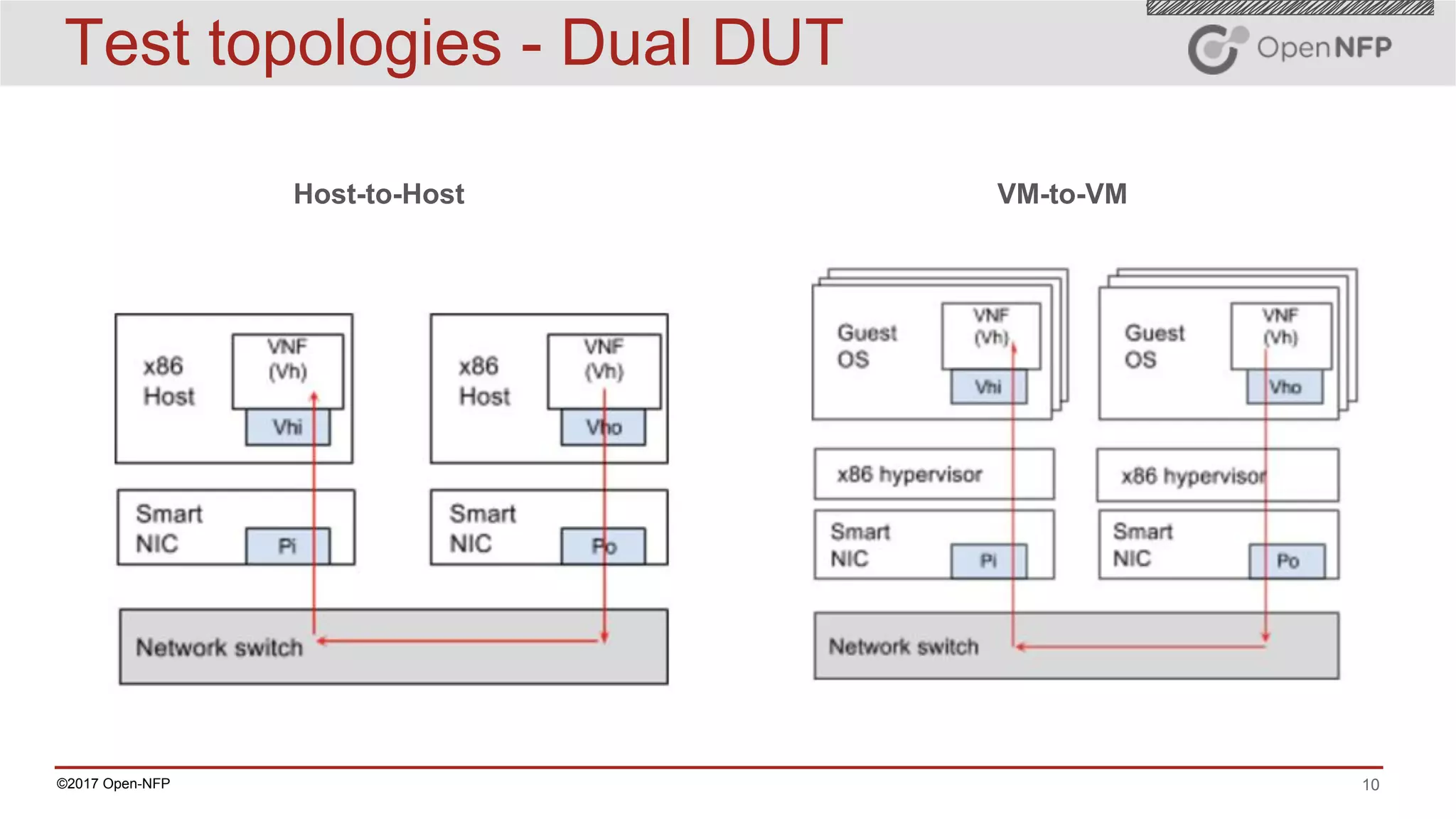
The document outlines a comprehensive testing methodology for measuring the performance of SmartNICs in virtualized environments, detailing equipment and traffic generators needed, as well as configuration settings for optimal results. It emphasizes the importance of factors such as CPU allocation, BIOS settings, and interrupt management to minimize latency and improve throughput. Various test topologies and examples are provided to guide users in achieving precise performance evaluations.















![CETH for XDP [Linux Meetup Santa Clara | July 2016]](https://cdn.slidesharecdn.com/ss_thumbnails/ceth5overview1-160801192921-thumbnail.jpg?width=640&height=640&fit=bounds)





























![Thu 430pm solarflare_tolley_v1[1]](https://cdn.slidesharecdn.com/ss_thumbnails/thu430pmsolarflaretolleyv11-130618183538-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)



![[BDD 2025 - Mobile Development] Mobile Engineer and Software Engineer: Are we...](https://cdn.slidesharecdn.com/ss_thumbnails/md-mobileengineerandsoftwareengineerarewestillrelevantsidiqpermana-251127010650-55224ef1-thumbnail.jpg?width=640&height=640&fit=bounds)



![[BDD 2025 - Mobile Development] Crafting Immersive UI with E2E and AGSL Shade...](https://cdn.slidesharecdn.com/ss_thumbnails/md-craftingimmersiveuiwithe2eandagslshaderveronicaputrianggraini-251124030840-0c677f44-thumbnail.jpg?width=640&height=640&fit=bounds)



![[BDD 2025 - Full-Stack Development] The Modern Stack: Building Web & AI Appli...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-themodernstackbuildingwebaiapplicationswithserverless-251124030844-388cf04f-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Artificial Intelligence] Building AI Systems That Users (and Comp...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-buildingaisystemsthatusersandcompanieslove-251124030845-038f7732-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Artificial Intelligence] AI for the Underdogs: Innovation for Sma...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-aifortheunderdogsinnovationforsmallbusinesses-251124030839-72a599a4-thumbnail.jpg?width=640&height=640&fit=bounds)







