Downloaded 313 times



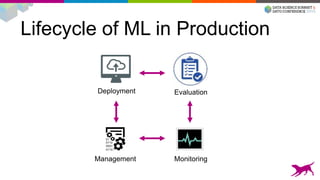
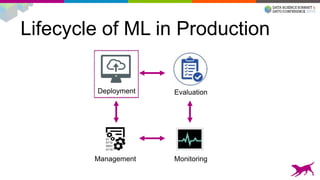

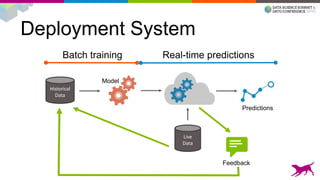
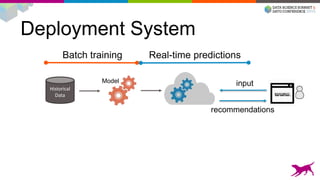
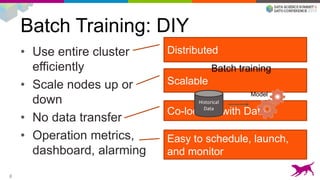
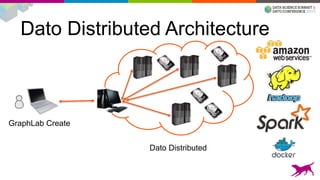

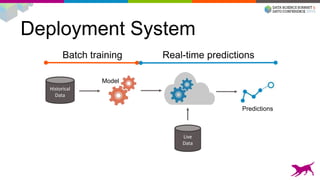
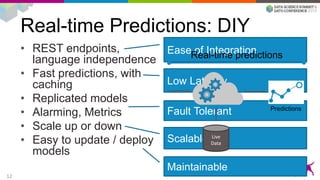
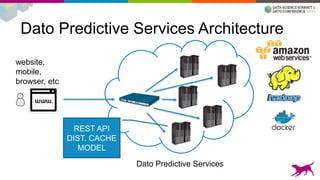


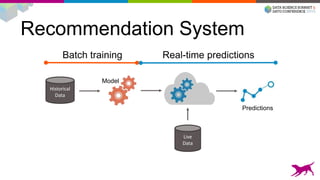
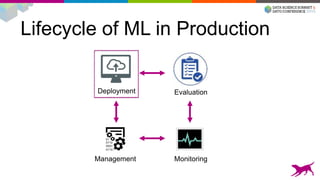

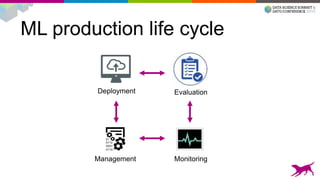

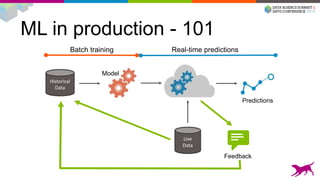
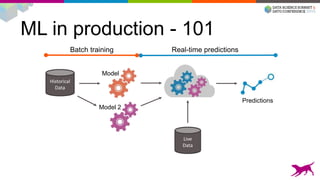


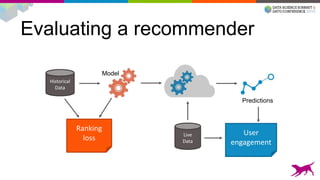
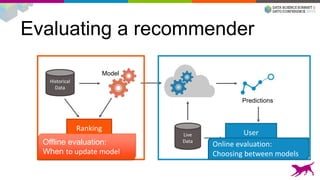

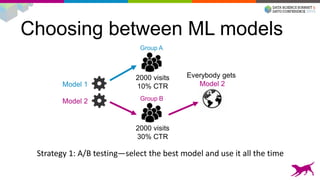

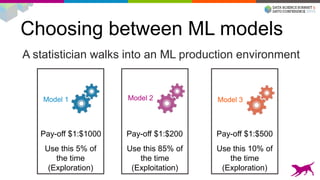



1) Deploying machine learning models into production involves evaluating, monitoring, deploying, and managing models over their lifecycle. 2) Evaluation involves continuously tracking metrics on both historical and live data to determine when models need to be updated. Monitoring involves choosing between existing models, such as by using A/B testing or multi-armed bandits. 3) Dato provides tools to simplify each stage of the machine learning lifecycle from batch training to real-time predictions to continuous evaluation and management of models in production.

























































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)











