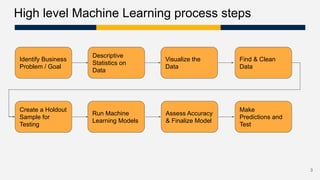
The document provides a workshop overview for completing a first machine learning project, covering the machine learning process from identifying business problems to model evaluation. It outlines steps for data preparation, model training using various algorithms, and assessing model performance. Additionally, it includes resources and definitions relevant to machine learning concepts.















![Clean our data
What if ‘age’ is not available for some people?
We could replace missing data with the median or mean.
print("Median Age: ",train_df.Age.median())
print("Mean Age: ",train_df.Age.mean())
# We'll use the mean
train_df['Age'] = train_df['Age'].fillna(train_df.Age.mean())
17](https://image.slidesharecdn.com/workshopyourfirstmachinelearningproject-211014133408/85/Workshop-Your-first-machine-learning-project-17-320.jpg)
![Clean our data
Algorithms need numerical inputs.
How do we handle non-numbers, like ‘male’ or ‘female’?
We’ll map them to binary values (male = 0, female = 1)
train_df['Sex'] = train_df['Sex'].map( {'female': 1, 'male': 0} ).astype(int)
train_df.head()
18](https://image.slidesharecdn.com/workshopyourfirstmachinelearningproject-211014133408/85/Workshop-Your-first-machine-learning-project-18-320.jpg)
![Clean our data
Let’s drop columns we won’t use from our dataset
# Remove columns that we won't use
train_df = train_df.drop(['PassengerId','Name', 'Parch', 'SibSp','Embarked','Ticket', 'Cabin'], axis=1)
train_df.head(5)
19](https://image.slidesharecdn.com/workshopyourfirstmachinelearningproject-211014133408/85/Workshop-Your-first-machine-learning-project-19-320.jpg)


![Split our data into input variables and output to predict
Define our independent (X) and dependent (Y) variables
X = train_df.drop("Survived", axis=1) # Training & Validation data
Y = train_df["Survived"] # Response / Target Variable
print(X.shape, Y.shape)
22](https://image.slidesharecdn.com/workshopyourfirstmachinelearningproject-211014133408/85/Workshop-Your-first-machine-learning-project-22-320.jpg)









![Now what? How to understand our model
We have a model, but what drives it?
We can analyze model drivers (sometimes).
# Look at importnace of features for random forest
def plot_model_var_imp( model , X , y ):
imp = pd.DataFrame(
model.feature_importances_ ,
columns = [ 'Importance' ] ,
index = X.columns
)
imp = imp.sort_values( [ 'Importance' ] , ascending = True )
imp[ : 10 ].plot( kind = 'barh' )
print ('Training accuracy Random Forest:',model.score( X , y ))
plot_model_var_imp(random_forest, X_train, Y_train) 32](https://image.slidesharecdn.com/workshopyourfirstmachinelearningproject-211014133408/85/Workshop-Your-first-machine-learning-project-32-320.jpg)










































































