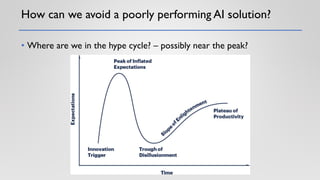
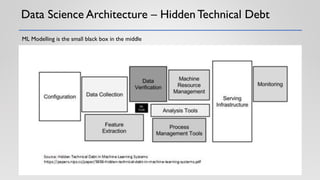
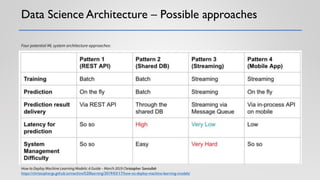
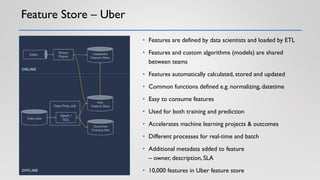
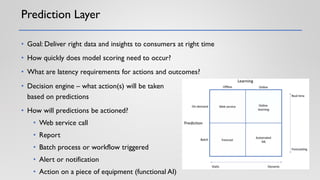
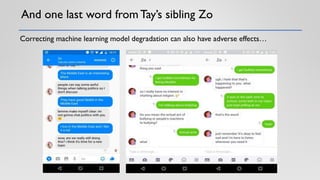
The document discusses the critical elements of productionizing machine learning models, emphasizing the need for planning, architecture selection, development, and ongoing maintenance to ensure success and avoid liabilities. It highlights the challenges faced by businesses in deploying machine learning solutions, including issues of model degradation and the importance of incorporating data quality, feature engineering, and monitoring processes. It also outlines the framework for building effective machine learning systems, including data ingestion, model training, deployment strategies, and feedback mechanisms.