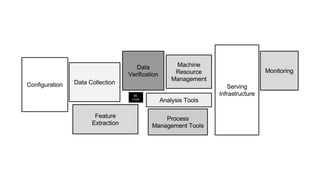
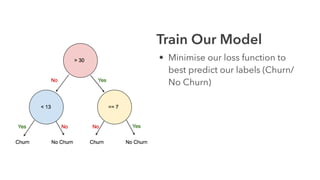
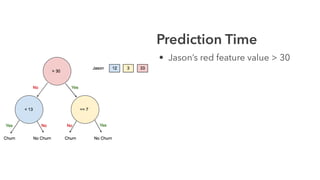
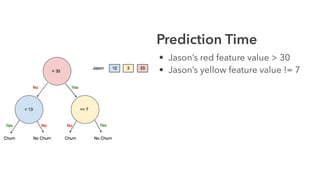
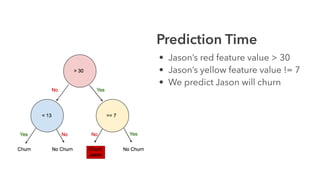
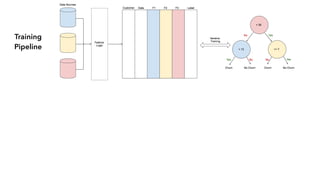
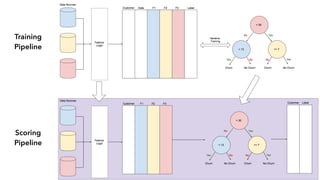
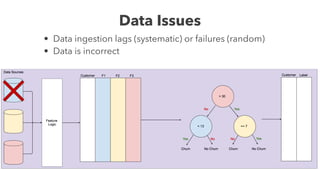
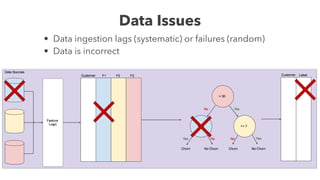
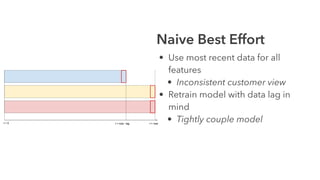
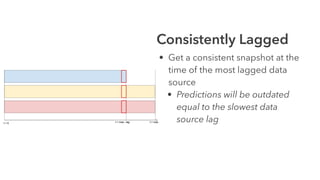
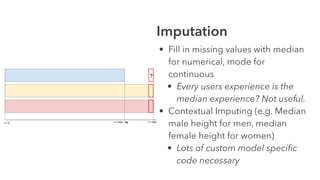
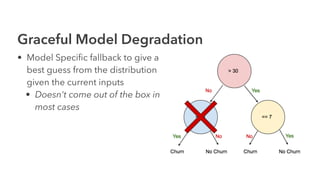
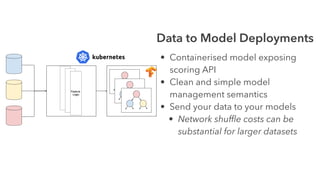
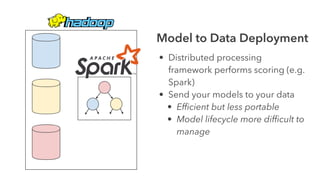
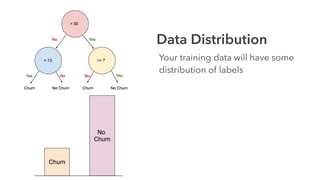
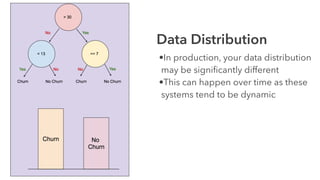
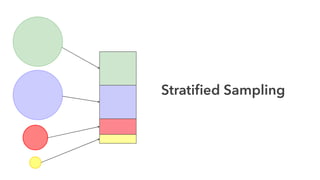
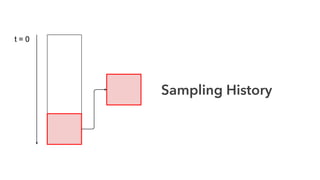
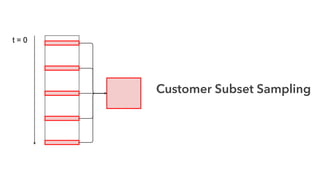
Cameron Joannidis discusses the intersection of machine learning and engineering, focusing on system design, data issues, and deployment strategies. He emphasizes the importance of understanding data distribution and model performance in production, along with methods for improving machine learning iteration speed. The document outlines challenges such as data ingestion lags, feature importance, and provides insights into effective model management and deployment solutions.