Downloaded 125 times








![Model server = Model Artifact + ...
matching_model v2
[
....
]
Build Docker and deploy to the cloud.
Now what?
It is still an anonymous black box.](https://image.slidesharecdn.com/dataopsmachinelearninginproduction-180215192745/85/Data-ops-Machine-Learning-in-production-15-320.jpg)
![Model server = Model Artifact +
Metadata + Runtime + Deps
/predict
input:
string text;
bytes image;
output:
string summary;
JVM DL4j
GPU
matching_model v2
[
....
]
gRPC HTTP server](https://image.slidesharecdn.com/dataopsmachinelearninginproduction-180215192745/85/Data-ops-Machine-Learning-in-production-16-320.jpg)
![Model server = Model Artifact +
Metadata + Runtime + Deps + Sidecar
/predict
input:
string text;
bytes image;
output:
string summary;
JVM DL4j
GPU
matching_model v2
[
....
]
gRPC HTTP server
routing, shadowing
pipelining
tracing
metrics
autoscaling
A/B, canary
sidecar
serving
requests](https://image.slidesharecdn.com/dataopsmachinelearninginproduction-180215192745/85/Data-ops-Machine-Learning-in-production-17-320.jpg)







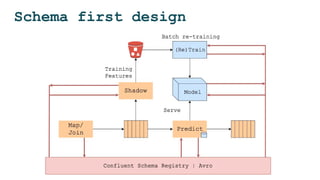
![Step 1: Schema first design
● Data defines the contracts and API between components
● Avro/Protobuf for all data records
● Confluent Schema Registry to manage Avro schemas
● Not only for Kafka. Must be used for all the data
pipelines (batch, Spark, etc)
{"namespace": "example.avro",
"type": "record",
"name": "User",
"fields": [
{"name": "name", "type": "string"},
{"name": "number", "type": ["int", "null"]},
{"name": "color", "type": ["string", "null"]}
]
}](https://image.slidesharecdn.com/dataopsmachinelearninginproduction-180215192745/85/Data-ops-Machine-Learning-in-production-35-320.jpg)
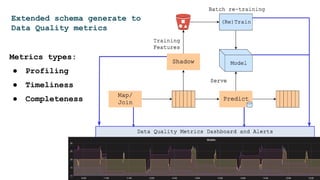
![Step 2: Extend schema
● Avro/Protobuf can catch data format bugs
● How about data profile? Min, max, mean, etc?
● Describe a data profile, statistical properties and
validation rules in extended schema!
{"name": "User",
"fields": [
{"name": "name", "type": "string", "min_length": 2, "max_length": 128},
{"name": "age", "type": ["int", "null"], "range": "[10, 100]"},
{"name": "sex", "type": ["string", "null"], " enum": "[male, female, ...]"},
{"name": "wage", "type": ["int", "null"], "validator": "DSL here..."}
]
}](https://image.slidesharecdn.com/dataopsmachinelearninginproduction-180215192745/85/Data-ops-Machine-Learning-in-production-37-320.jpg)


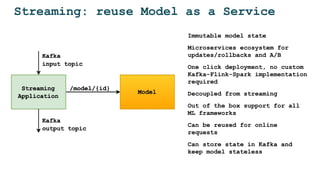
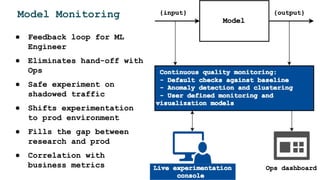
![Model server = Metadata + Model Artifact +
Runtime + Deps + Sidecar + Training Metadata
/predict
input:
output:
JVM DL4j
GPU
matching_model v2
[
....
]
gRPC HTTP server
sidecar
serving
requests
training data stats:
- min
- max
- clusters
- autoencoder
compare with prod
data in runtime](https://image.slidesharecdn.com/dataopsmachinelearninginproduction-180215192745/85/Data-ops-Machine-Learning-in-production-41-320.jpg)


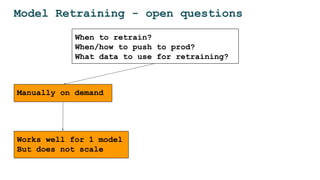
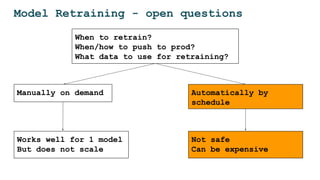
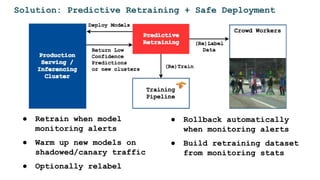




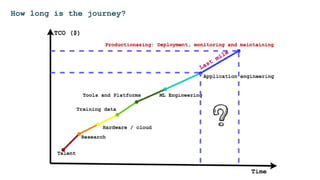
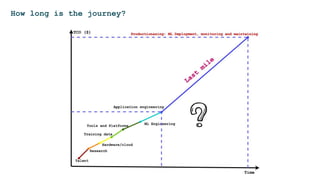
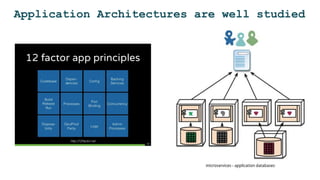
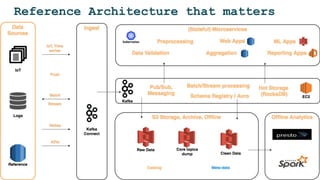
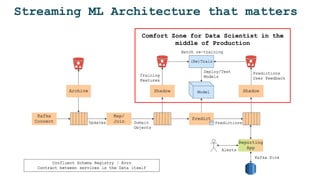
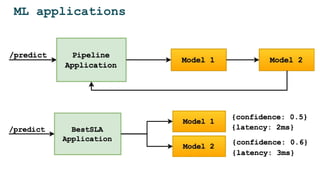
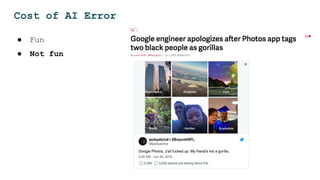
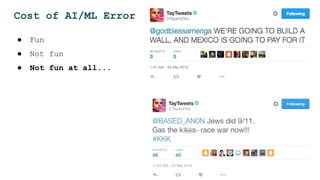
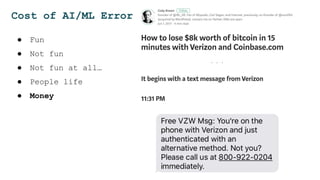
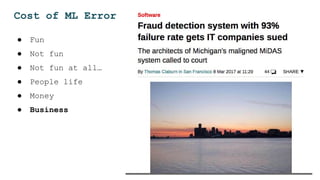
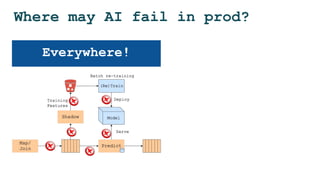
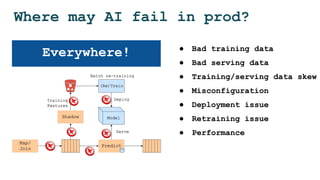
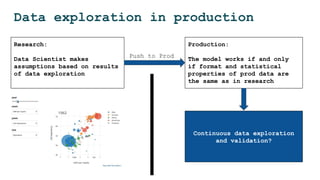
The document discusses the challenges and solutions for deploying machine learning in production, focusing on the architecture, data quality, and monitoring aspects. It highlights the importance of a unified framework for data processing and experimentation to ensure reliability and efficiency in model deployment. Key takeaways include the need for schema-first design, automated data profiling, and predictive retraining to minimize errors and enhance machine learning operations.
























































![[DSC Europe 25] Raul Cruz Bonilla - Harnessing GEN AI in Fashion, Luxury and ...](https://cdn.slidesharecdn.com/ss_thumbnails/me7nvup5thwqzwzblbvw-raul-cruz-harnessing-ai-en-luxury-260123083019-32ac5a43-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Josip Saban - Career building for data professionals.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/zroflcttkm1vmli0txea-josip-saban-career-building-for-data-professionals-260123083019-587cdb8c-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Predrag Maletic - Scaling AI in Banking – Our Strategic Journ...](https://cdn.slidesharecdn.com/ss_thumbnails/qu2onv0aruwlvqtygmxx-predrag-maletic-scaling-ai-in-banking-260123083019-6cf1da1d-thumbnail.jpg?width=640&height=640&fit=bounds)









