Downloaded 89 times
















![Dato Confidential18
Tokenization
Convert each document into a list of tokens.
“The caesar salad was amazing.”INPUT
[“The”, “caesar”, “salad”, “was”, “amazing.”]OUTPUT](https://image.slidesharecdn.com/webinar-textanalysis-dubois-20160414-160415001357/85/Text-Analysis-with-Machine-Learning-18-320.jpg)





![Dato Confidential24
Split by sentence
Convert each document into a list of sentences.
INPUT
OUTPUT
“It was delicious. I will be back.”
[“It was delicious.”, “I will be back.”]](https://image.slidesharecdn.com/webinar-textanalysis-dubois-20160414-160415001357/85/Text-Analysis-with-Machine-Learning-24-320.jpg)
![Dato Confidential25
Extract parts of speech
Identify particular parts of speech.
INPUT
OUTPUT
“It was delicious. I will go back.”
[“delicious”]](https://image.slidesharecdn.com/webinar-textanalysis-dubois-20160414-160415001357/85/Text-Analysis-with-Machine-Learning-25-320.jpg)
![Dato Confidential26
stack
Rearrange the data set to “stack” the list column.
id text
102 [“The food was great.”, “I will be
back.”]
103 [“I would absolutely bring my
friends here.”, “I could eat those
fries every day.”]
104 [“Too expensive for me.”]
… …
int list
id text
102 “The food was great.”
102 “I will be back.”
103 “I would absolutely bring my friends
here.”
… …
int str](https://image.slidesharecdn.com/webinar-textanalysis-dubois-20160414-160415001357/85/Text-Analysis-with-Machine-Learning-26-320.jpg)
![Dato Confidential27
unstack
Rearrange the data set to “unstack” the string column.
id text
102 [“The food was great.”, “I will be
back.”]
103 [“I would absolutely bring my
friends here.”, “I could eat those
fries every day.”]
104 [“Too expensive for me.”]
… …
int list
id text
102 “The food was great.”
102 “I will be back.”
103 “I would absolutely bring my friends
here.”
… …
int str](https://image.slidesharecdn.com/webinar-textanalysis-dubois-20160414-160415001357/85/Text-Analysis-with-Machine-Learning-27-320.jpg)
![Dato Confidential28
Pipelines
Combine multiple transformations to create a single pipeline.
from graphlab.feature_engineering import
WordCounter, RareWordTrimmer
f = gl.feature_engineering.create(sf,
[WordCounter, RareWordTrimmer])
f.fit(data)
f.transform(new_data)](https://image.slidesharecdn.com/webinar-textanalysis-dubois-20160414-160415001357/85/Text-Analysis-with-Machine-Learning-28-320.jpg)





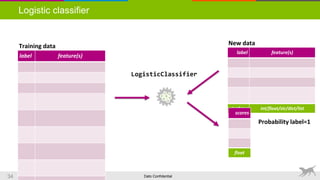

![Dato Confidential36
Product sentiment toolkit
>>> m = gl.product_sentiment.create(sf, features=['Description'], splitby='sentence')
>>> m.sentiment_summary(['billing', 'cable', 'cost', 'late', 'charges', 'slow'])
+---------+----------------+-----------------+--------------+
| keyword | sd_sentiment | mean_sentiment | review_count |
+---------+----------------+-----------------+--------------+
| cable | 0.302471264675 | 0.285512408978 | 1618 |
| slow | 0.282117103769 | 0.243490314737 | 369 |
| cost | 0.283310577512 | 0.197087019219 | 291 |
| charges | 0.164350792173 | 0.0853637431588 | 1412 |
| late | 0.119163914305 | 0.0712757752753 | 2202 |
| billing | 0.159655783707 | 0.0697454360245 | 583 |
+---------+----------------+-----------------+--------------+](https://image.slidesharecdn.com/webinar-textanalysis-dubois-20160414-160415001357/85/Text-Analysis-with-Machine-Learning-36-320.jpg)








The document discusses text analysis with machine learning. It begins with introductions and then covers applications of text analysis like product reviews and social media. The bulk of the document discusses fundamentals of text processing like tokenization and feature engineering. It also discusses machine learning toolkits and task-oriented tools like sentiment analysis. Advanced topics like topic models and word embeddings are briefly introduced. The presentation aims to provide an overview of text analysis and point to further resources.








































































































