Download as PDF, PPTX



































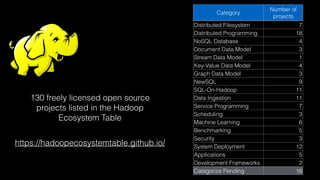






















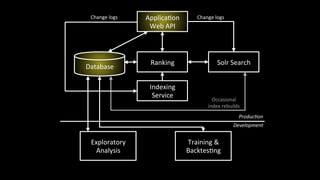




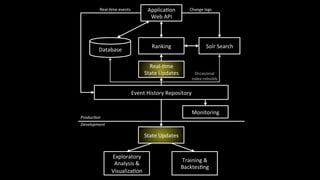








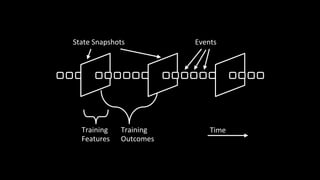

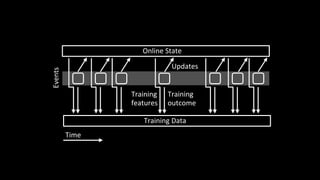














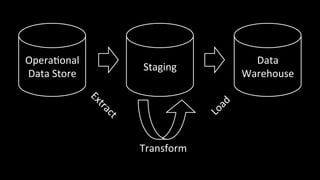








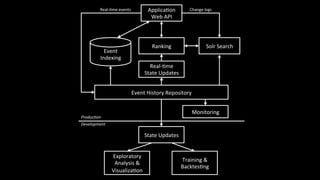









1. The document discusses architecting data science platforms for a dating product using an event-driven architecture that stores all data as a stream of events. 2. Key aspects of the architecture include an event history repository that stores real-time event streams, a Solr search index for querying events, and using the event stream for both online and offline machine learning. 3. The architecture aims to enable fast experimentation cycles by using the same code and data for production, development, and training machine learning models.


































































![Lect 1 Number systems and base conversions. [Autosaved].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/lect1numbersystemsandbaseconversions-260111134109-67c2d865-thumbnail.jpg?width=640&height=640&fit=bounds)
