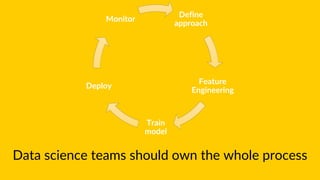
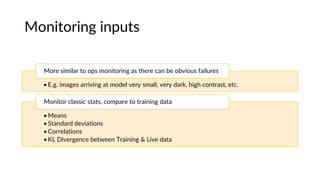
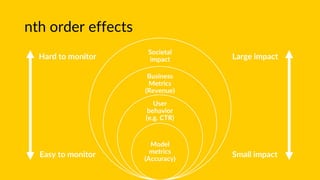
The document discusses the importance of monitoring machine learning models in production. It notes that the world is constantly changing and data used to train models may no longer accurately reflect reality. It recommends techniques like online learning, active learning, and monitoring model inputs, outputs, and ground truth to continually update models with new data from the real world. Challenges include interpreting model behavior and monitoring higher-order societal impacts, which are difficult but important to address for ensuring model accountability.




















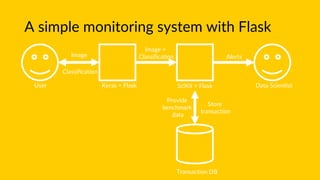
![Bare Bones Flask Serving
image = flask.request.files["image"].read()
image = prepare_image(image, target=(224, 224))
preds = model.predict(image)
results = decode_predictions(preds)
data["predictions"] = []
for (label, prob) in results[0]:
r = {"label": label, "probability": float(prob)}
data["predictions"].append(r)
data["success"] = True
return flask.jsonify(data)](https://image.slidesharecdn.com/monitoringmodels-180527133825/85/Monitoring-Models-in-Production-25-320.jpg)
![Statistical monitoring with SciKit
ent = scipy.stats.entropy(pk,qk,base=2)
if ent > threshold:
abs_diff = np.abs(pk-qk)
worst_offender = lookup[np.argmax(abs_diff)]
max_deviation = np.max(abs_diff)
alert(model_id,ent,
worst_offender,max_deviation)](https://image.slidesharecdn.com/monitoringmodels-180527133825/85/Monitoring-Models-in-Production-26-320.jpg)