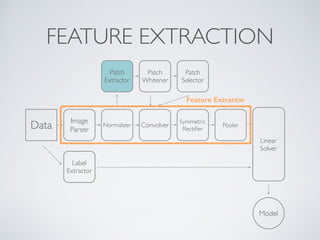
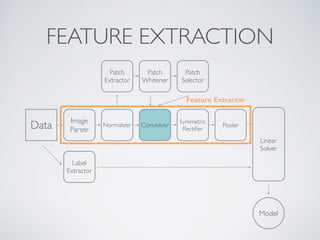
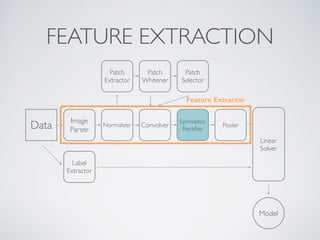
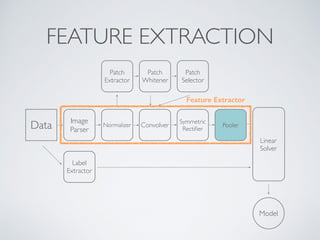
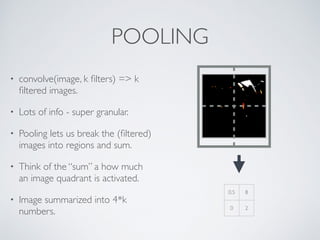
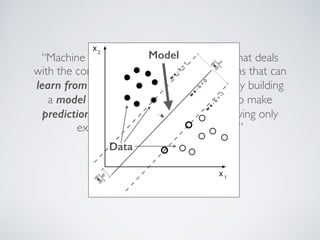
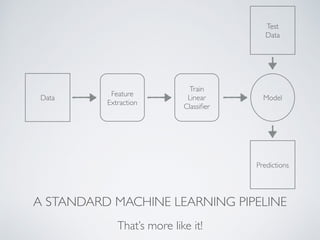
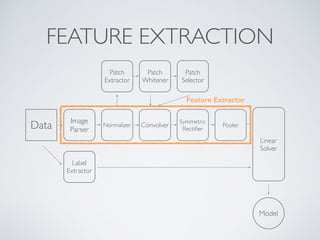
This document discusses machine learning pipelines and introduces Evan Sparks' presentation on building image classification pipelines. It provides an overview of feature extraction techniques used in computer vision like normalization, patch extraction, convolution, rectification and pooling. These techniques are used to transform images into feature vectors that can be input to linear classifiers. The document encourages building simple, intermediate and advanced image classification pipelines using these techniques to qualitatively and quantitatively compare their effectiveness.











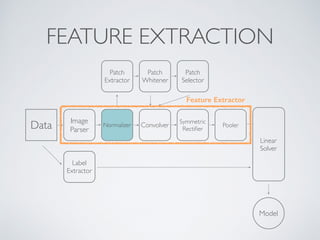
![NORMALIZATION
• Moves pixels from [0, 255] to
[-1.0,1.0].
• Why? Math!
• -1*-1 = 1, 1*1 =1
• If I overlay two pixels on each
other and they’re similar values,
their product will be close to 1
- otherwise, it will be close to 0
or -1.
• Necessary for whitening.
0
255
-1
+1](https://image.slidesharecdn.com/ugmw6deis9wmdpnexttl-signature-767cd3e5b3aefbf2f16d0f2edc338a40b5a7006cff60bc6a73e79d9b2339738c-poli-141121170601-conversion-gate02/85/Machine-Learning-Pipelines-19-320.jpg)