Download as PDF, PPTX










![SFrame Python API
Make a little SFrame of 1 column and 5 values:
>> sf = gl.SFrame({‘x’:[1,2,3,4,5]})
Normalizes the column x:
>> sf[‘x’] = sf[‘x’] / sf[‘x’].sum()
Uses a python lambda to create a new column:
>> sf[‘x-squared’] = sf[‘x’].apply(lambda x: x*x if x > 0 else 0)
Create a new column using a vectorized operator:
>> sf[‘x-cubed’] = sf[‘x-squared’] * sf[‘x’]
Create a new SFrame taking only 2 of the columns:
>> sf2 = sf[[‘x’,’x-squared’]]](https://image.slidesharecdn.com/time-series-151005170602-lva1-app6892/85/Scalable-data-structures-for-data-science-12-320.jpg)

![nrating
sf[‘nrating’]-=-sf2[‘rating’]
What is the SFrame?
sf#=#gl.SFrame(‘netflix_tr.frame’)
user movie rating
netflix_tr.frame
sf
user
item
rating
sf2$=$gl.SFrame(‘netflix_norm.frame’)
user movie rating
netflix_norm.frame
sf2
user
item
rating](https://image.slidesharecdn.com/time-series-151005170602-lva1-app6892/85/Scalable-data-structures-for-data-science-14-320.jpg)
![nrating
sf[‘nrating’]-=-sf2[‘rating’]
What is the SFrame?
sf#=#gl.SFrame(‘netflix_tr.frame’)
user movie rating
netflix_tr.frame
sf
user
item
rating
sf2$=$gl.SFrame(‘netflix_norm.frame’)
user movie rating
netflix_norm.frame
sf2
user
item
rating
diff
anonymous
diff$=$sf[‘rating’]$0 sf2[‘rating’]](https://image.slidesharecdn.com/time-series-151005170602-lva1-app6892/85/Scalable-data-structures-for-data-science-15-320.jpg)
![What is the SFrame?
Filtering
sf[sf[‘rating’]->=-3]
Joins
Sf.join(user_table,-on=‘user_id’)
Random/Array3indexing
row10-=-sf[10]
Table_with_every_other_row =-sf[::2]
Rather3Fast3Parallelized3UDFs3(Interproc SHM)
sf[‘rating’].apply(lambda-x:-x*x)
Not a SQL
Frontend](https://image.slidesharecdn.com/time-series-151005170602-lva1-app6892/85/Scalable-data-structures-for-data-science-16-320.jpg)

![Query Evaluation
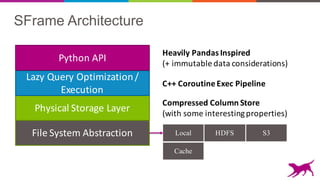
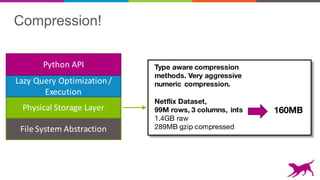
Physical)Storage)Layer
Lazy)Query)Optimization)/)
Execution
Python)API
File)System)Abstraction
p['X4']'='p['X3']'+'p['X2']
g='p[p['X1']'<'10]](https://image.slidesharecdn.com/time-series-151005170602-lva1-app6892/85/Scalable-data-structures-for-data-science-20-320.jpg)









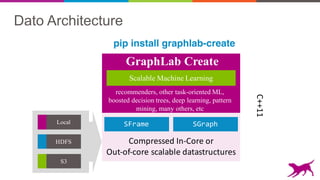
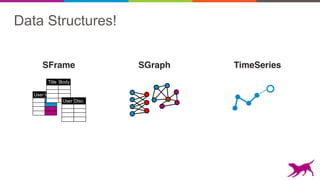
This document discusses scalable out-of-core data structures for data science. It introduces SFrame and SGraph, which allow machine learning on large datasets that exceed memory by using compressed columnar storage and lazy evaluation. SFrame provides a Python API for feature engineering and vectorized operations on tabular data. SGraph supports graph algorithms like PageRank on very large graphs with billions of nodes and edges. These tools are open source and support HDFS, S3, and other storage backends to enable scalable machine learning.





























































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)













