



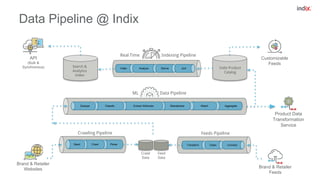


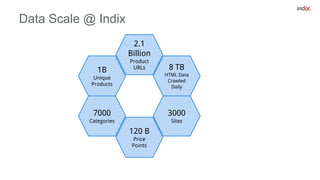















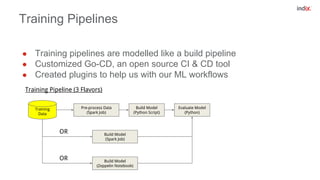

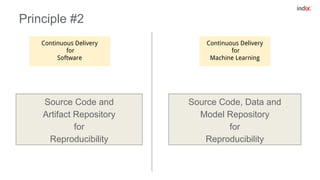















This document discusses principles for applying continuous delivery practices to machine learning models. It begins with background on the speaker and their company Indix, which builds location and product-aware software using machine learning. The document then outlines four principles for continuous delivery of machine learning: 1) Automating training, evaluation, and prediction pipelines using tools like Go-CD; 2) Using source code and artifact repositories to improve reproducibility; 3) Deploying models as containers for microservices; and 4) Performing A/B testing using request shadowing rather than multi-armed bandits. Examples and diagrams are provided for each principle.











































































