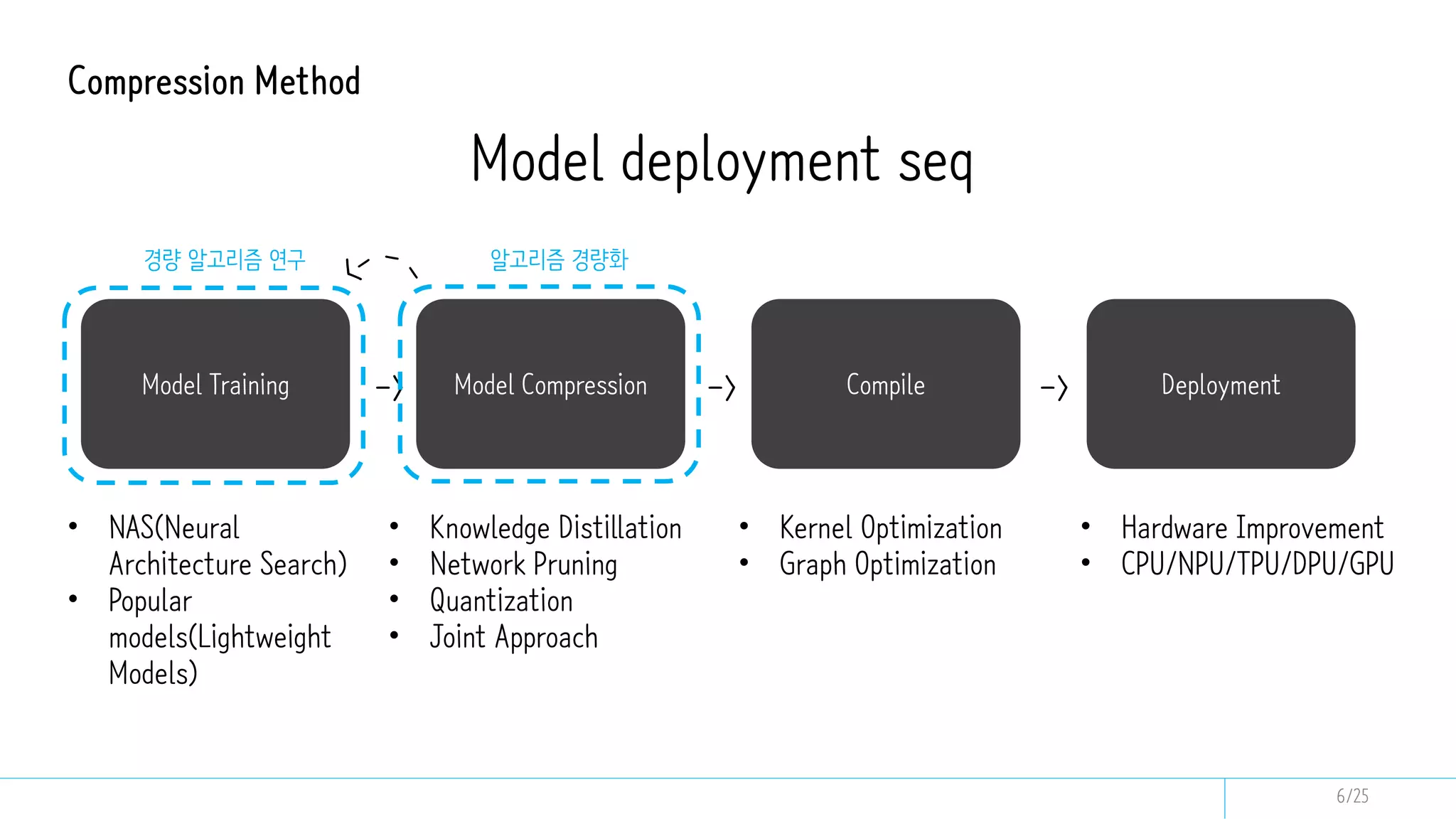
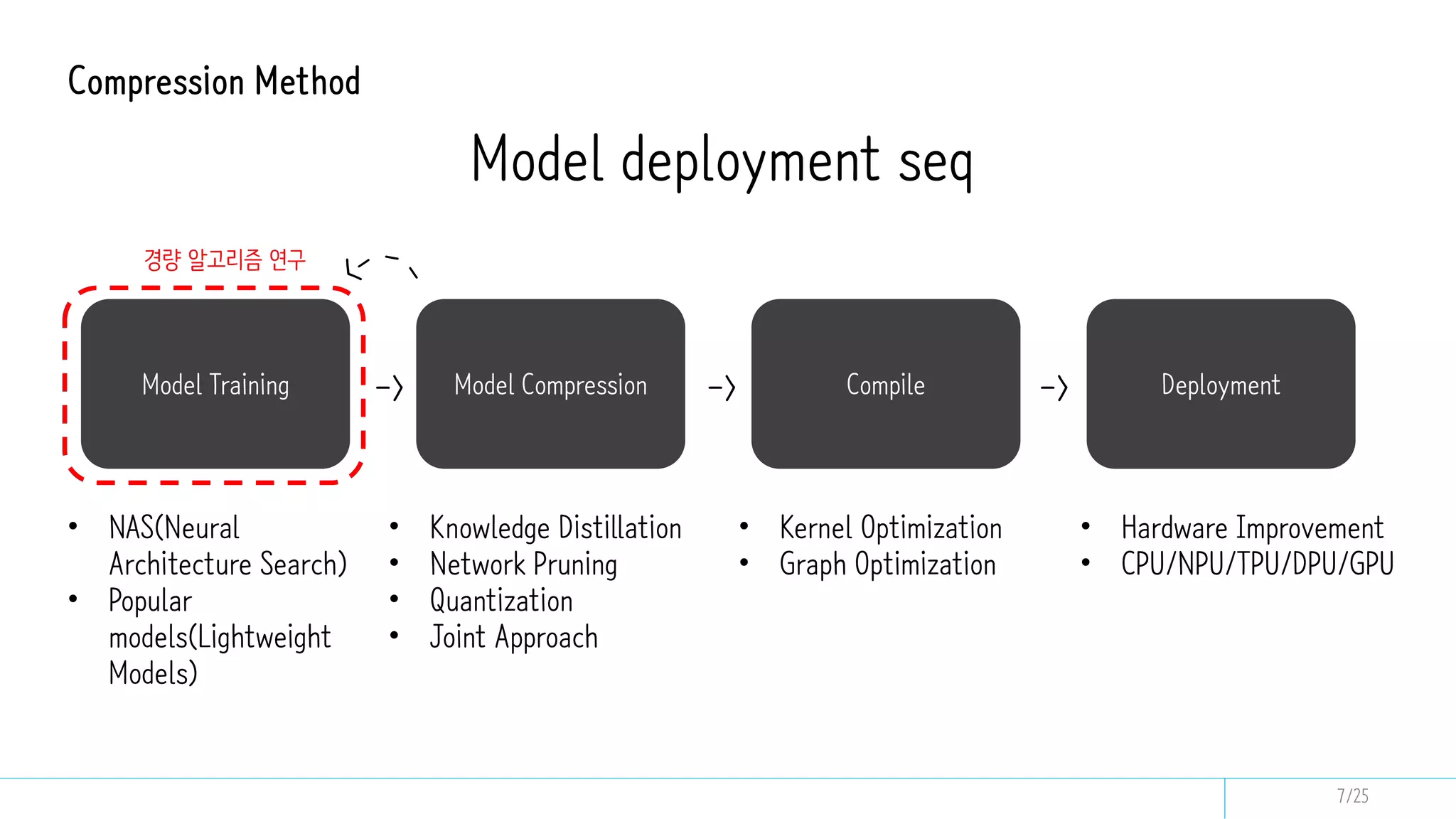
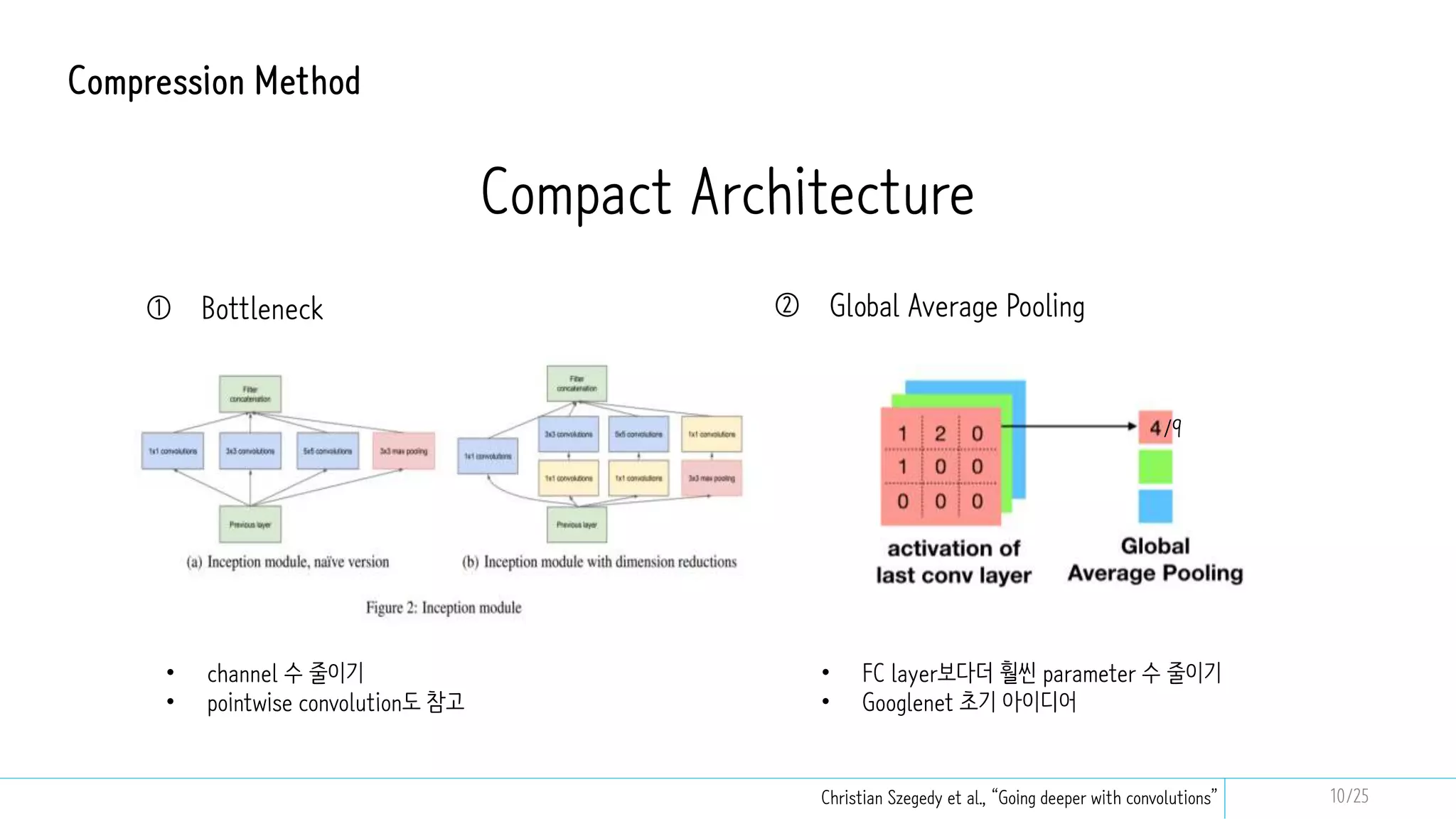
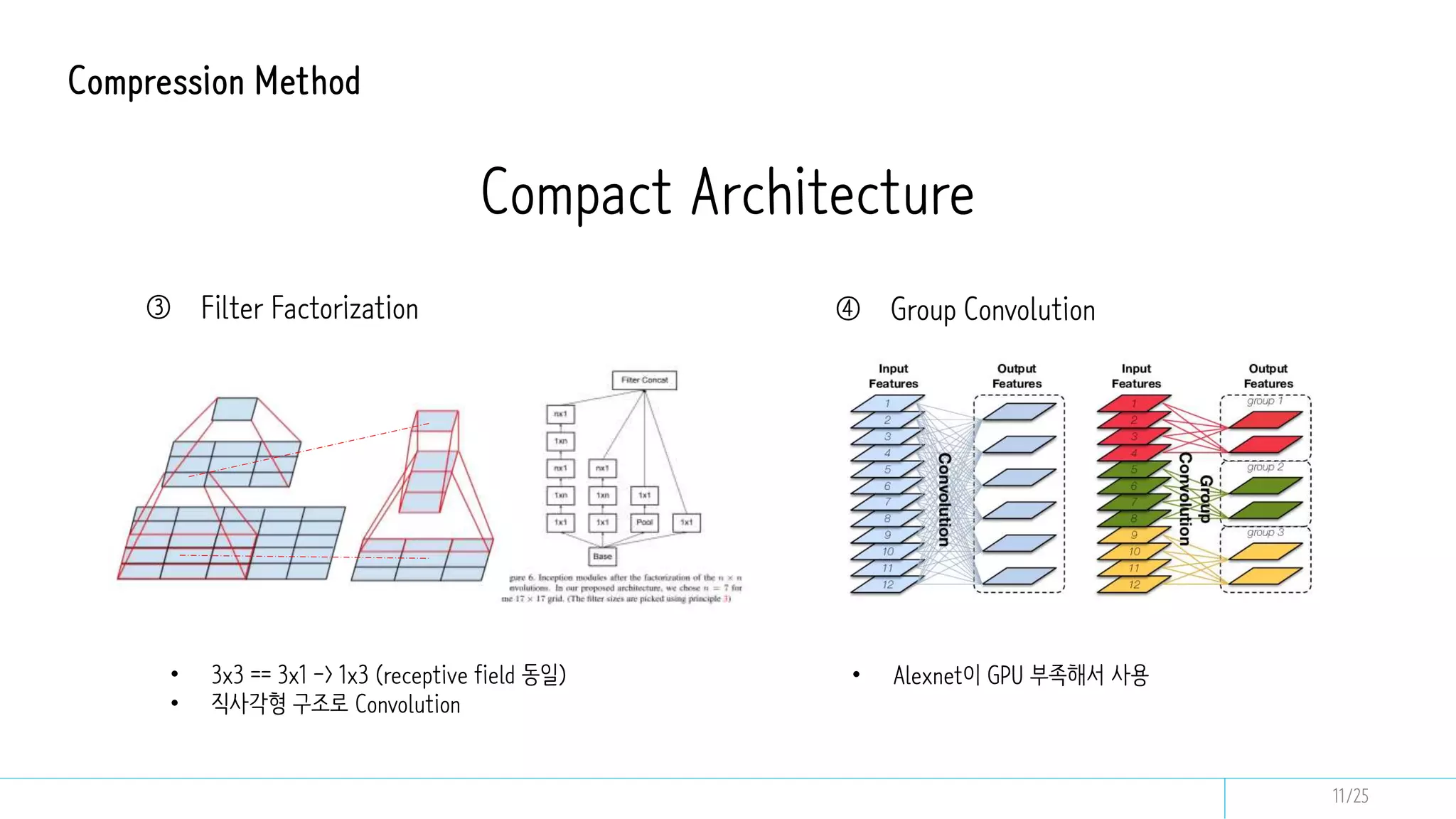
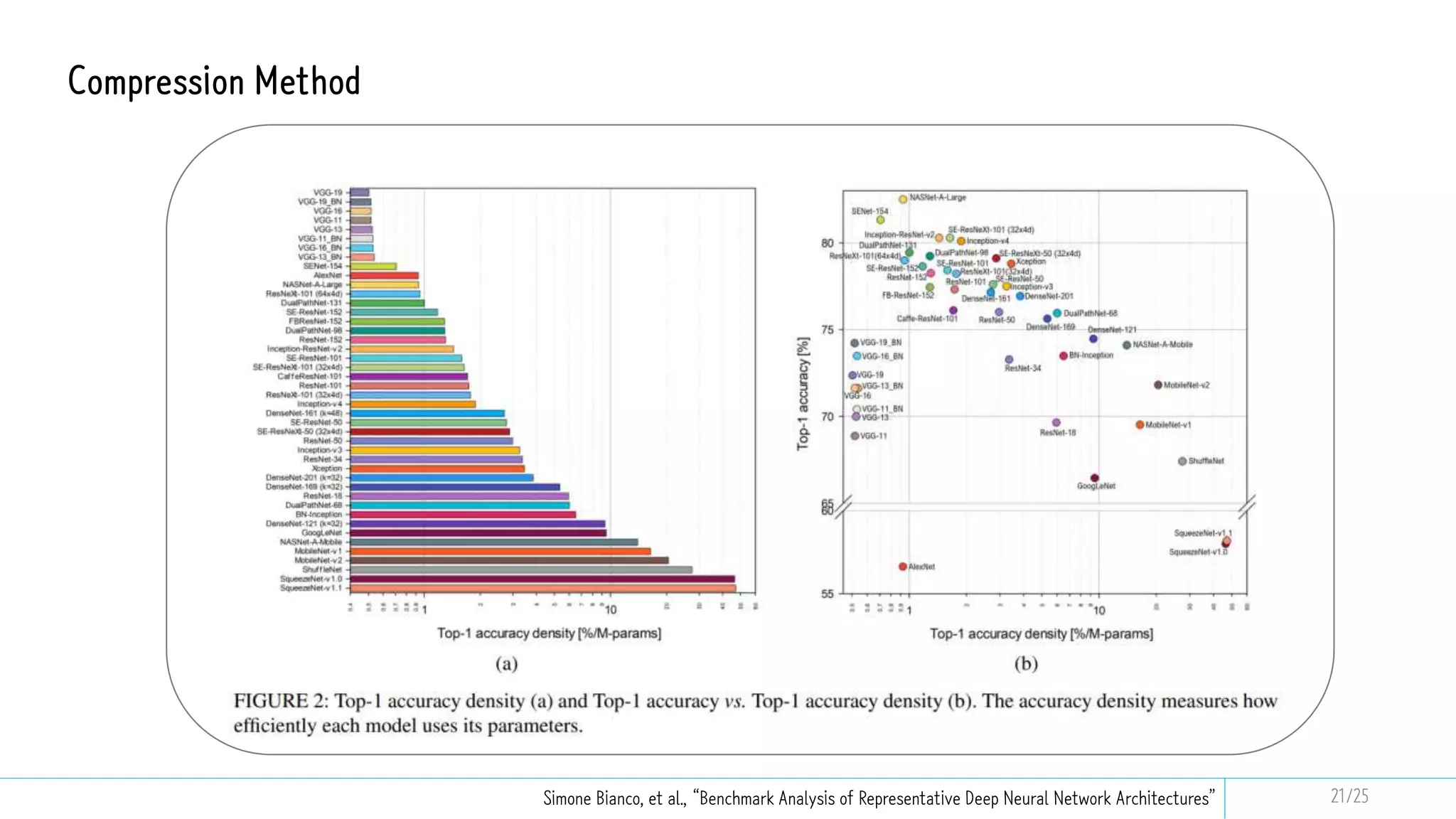
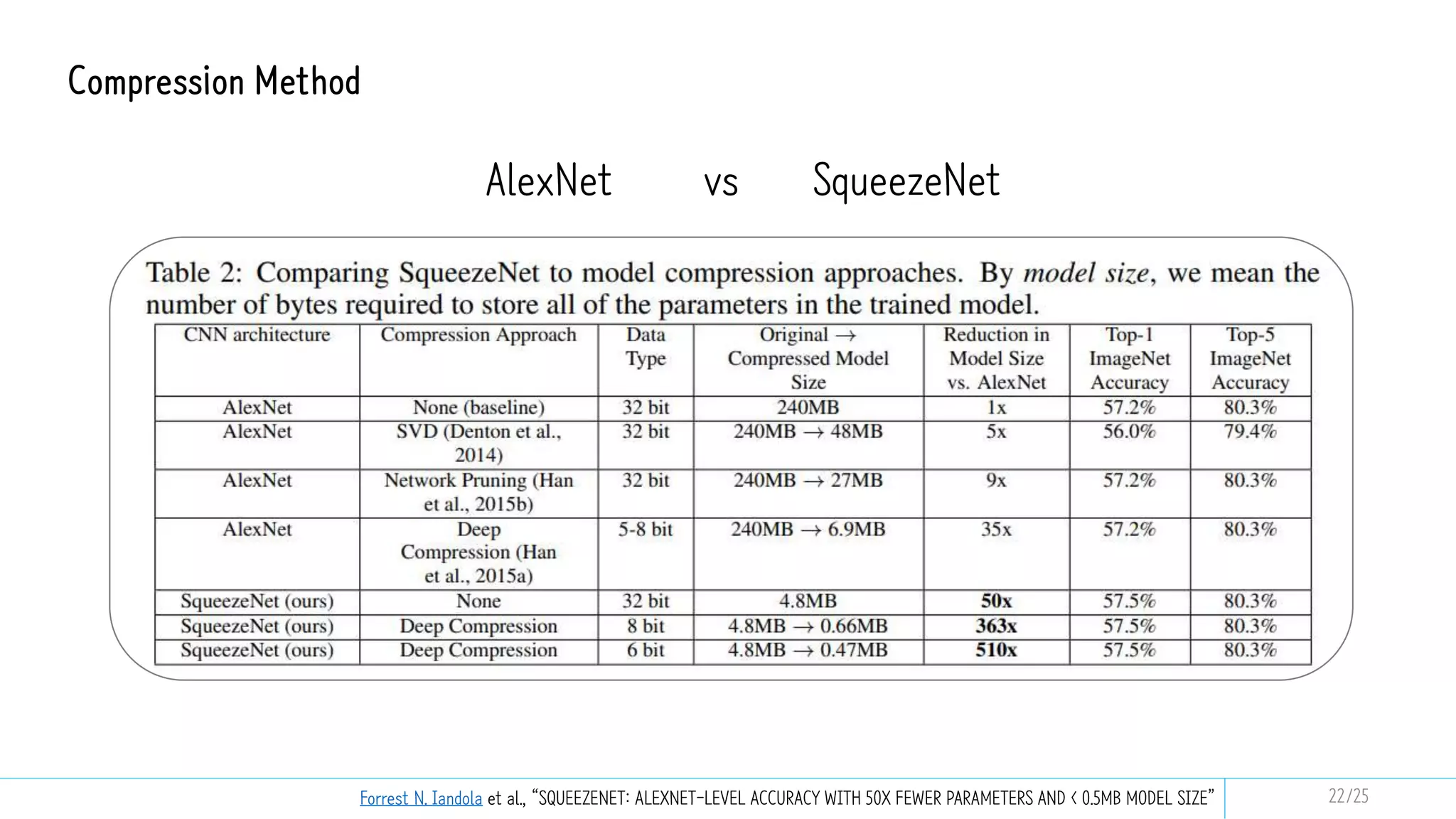
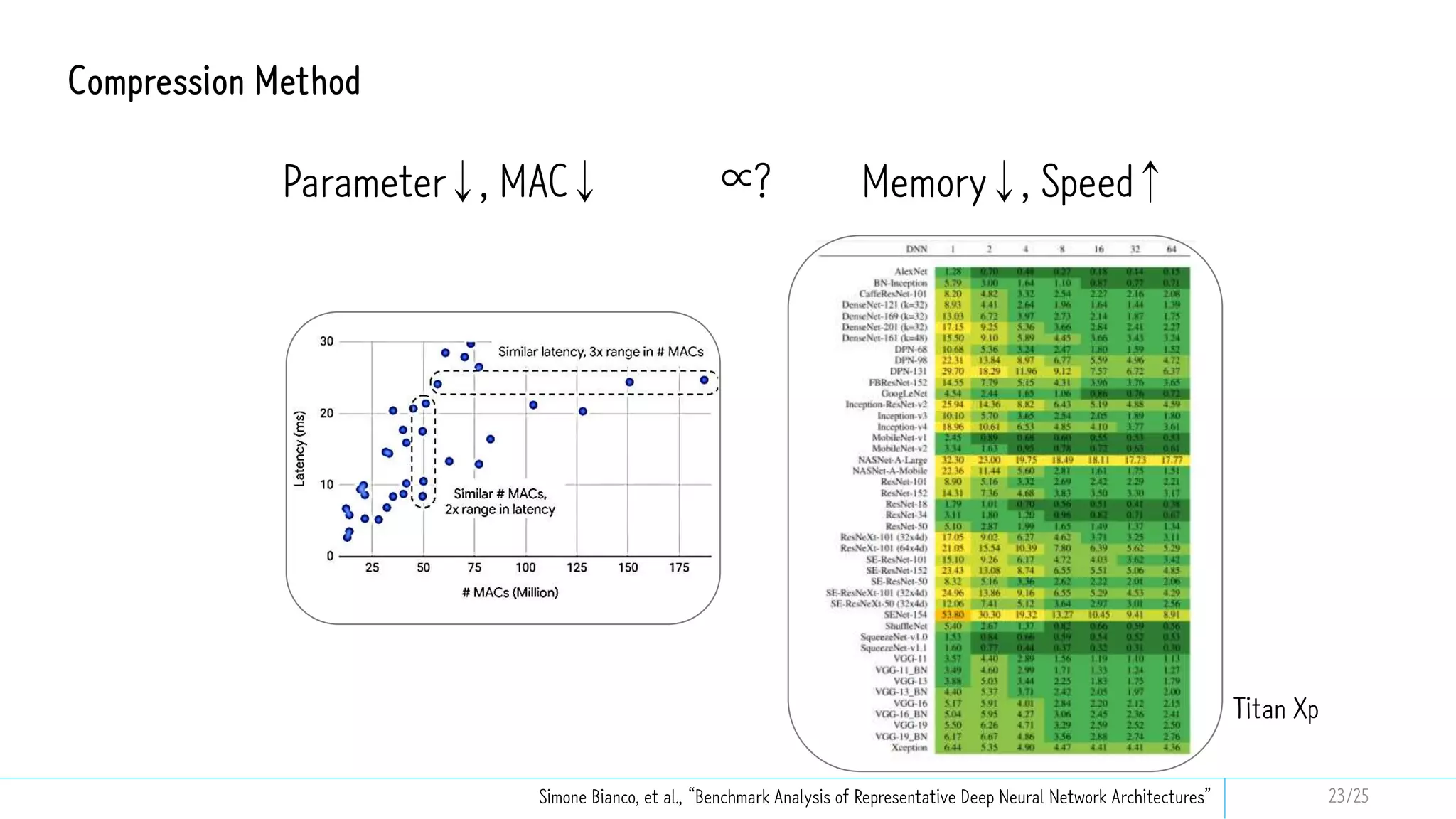
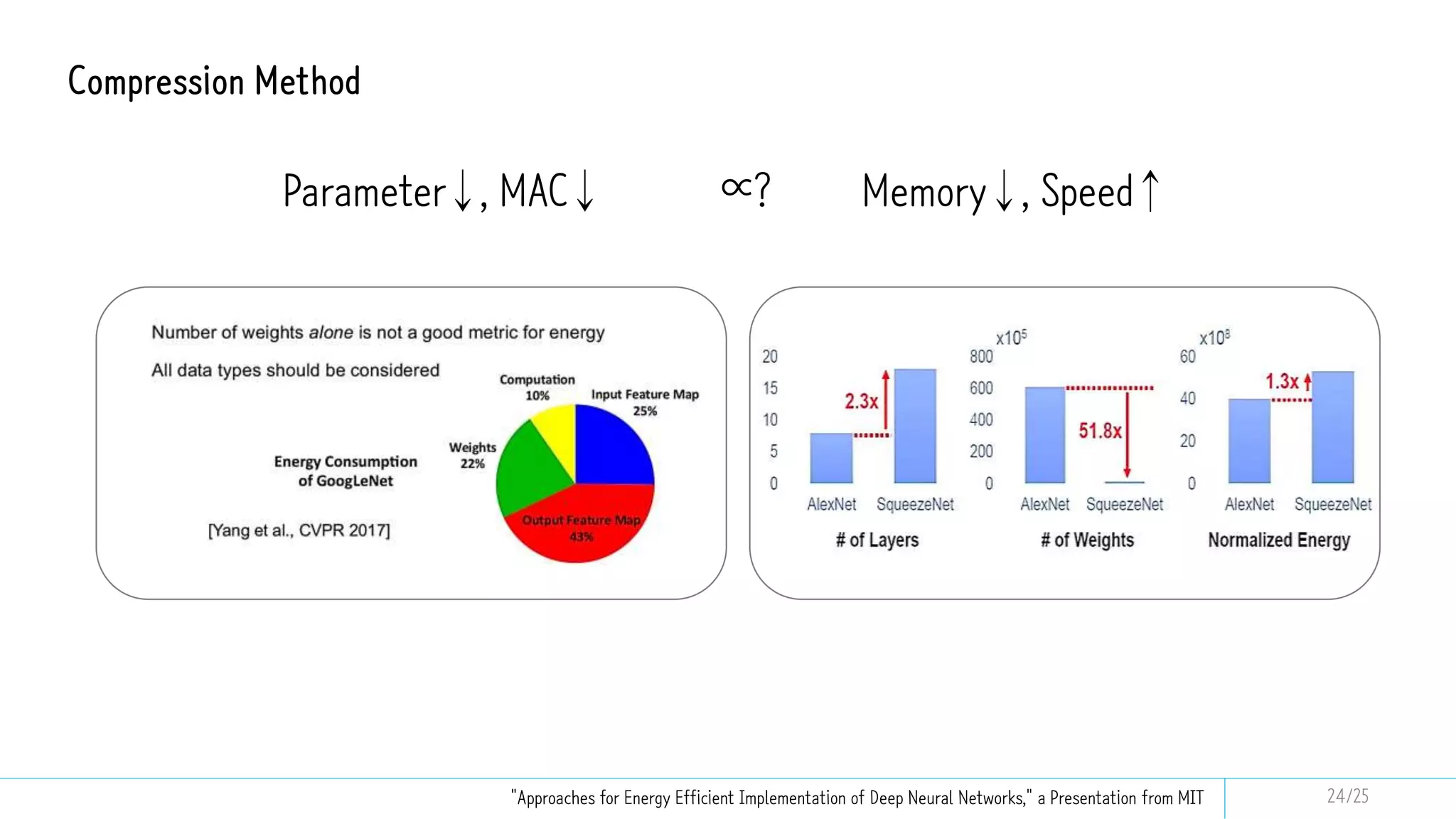
This document discusses model compression techniques to create efficient deep learning models with fewer parameters and operations while maintaining performance. It covers various methods such as neural architecture search, knowledge distillation, network pruning, and quantization, alongside their deployment steps and evaluation metrics. The content aims to address the need for energy efficiency, latency reduction, and improved model deployment across devices.





![Compression Method
NAS
① Hyper-Parameter Optimization(HPO)
② Feature Learning
③ Neural Architecture Search(NAS)
AutoML
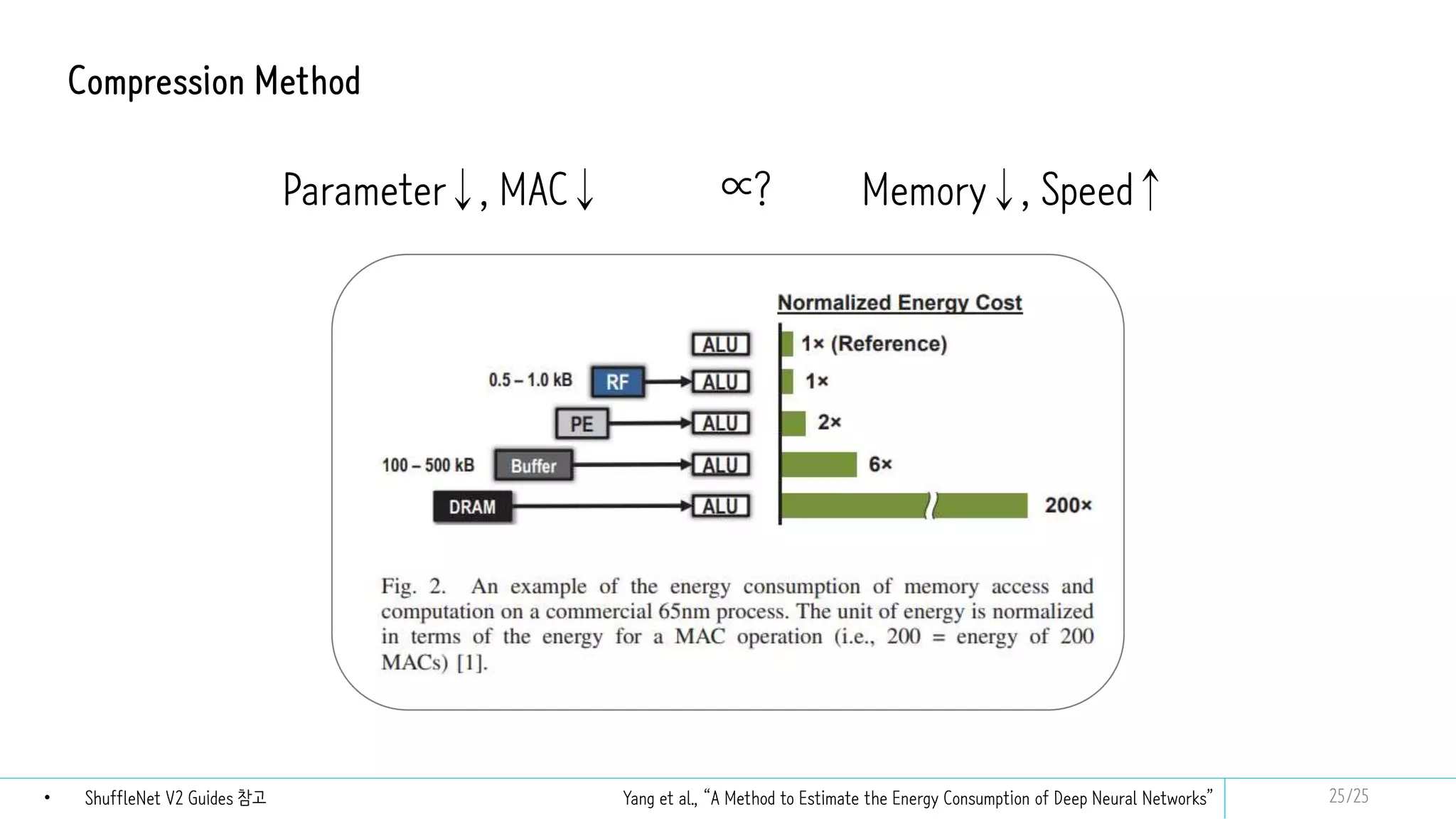
Barret Zoph et al., “NEURAL ARCHITECTURE SEARCH WITH REINFORCEMENT LEARNING”
• Ex. Configuration String: [“Filter Width: 5”, “Filter Height:3”, “Num Filters:24”]
• Controller(RNN)을 수렴하게 강화학습
• Child Network의 정확도(Reword Signal)를 기반으로 Controller(RNN)의 파라미터들을 업데이트
• Child Network 구조에서 기대하는 Validation Accuracy를 최대화하기 위해 Controller(RNN)의
파라미터인 𝜃𝑐
가 최적화
• Policy gradient를 써서 파라미터 업데이트
8/25](https://image.slidesharecdn.com/modelcompression-210501093756/75/Model-compression-8-2048.jpg)


![Next!
• Detail: Compression Method
• Exercise: Pruning, …
• Compression model paper
Reference, 도움받은 곳!
Youtube
• On device AI를 위한 모델 경량화[MODUCON 2019]
• [Techtonic 2020] Track 2. 딥러닝 모델을 Production 현장에 배포하고 Serving하
기 - 최효근 프로
• PR-017: Neural Architecture Search with Reinforcement Learning
• [풀영상] 모바일 ML을 위한 비전모델을 쥐어짜보즈아! (백수콘 June 2018)
Blog
• AutoML
• https://medium.com/daria-blog/automl-%EC%9D%B4%EB%9E%80-
%EB%AC%B4%EC%97%87%EC%9D%BC%EA%B9%8C-1af227af2075
• Knowledge distillation
• https://towardsdatascience.com/knowledge-distillation-simplified-
dd4973dbc764
• Convolution 경량화 기법들
• https://eehoeskrap.tistory.com/431
Tech Talk
• Nota 국제인공지능대전
• Nota 딥러닝 경량화의 최신 동향 및 경량화 플랫폼 넷츠프레소의 소개
• Hyperconnect 회사 소개
26](https://image.slidesharecdn.com/modelcompression-210501093756/75/Model-compression-26-2048.jpg)










![[Paper] Multiscale Vision Transformers(MVit)](https://cdn.slidesharecdn.com/ss_thumbnails/papermultiscalevisiontransformers-210808092058-thumbnail.jpg?width=640&height=640&fit=bounds)











![ViT (Vision Transformer) Review [CDM]](https://cdn.slidesharecdn.com/ss_thumbnails/vitreviewcdm-201012184226-thumbnail.jpg?width=640&height=640&fit=bounds)



























































