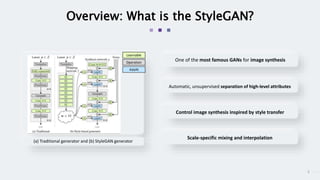
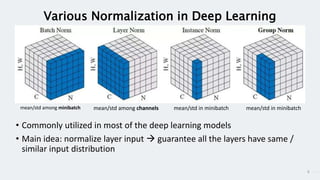
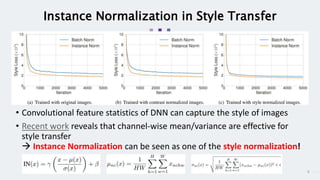
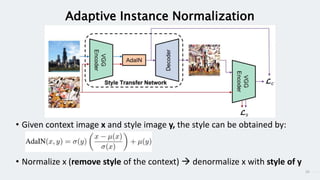
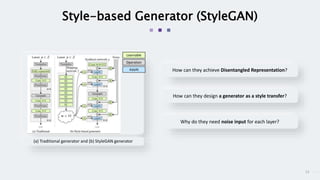
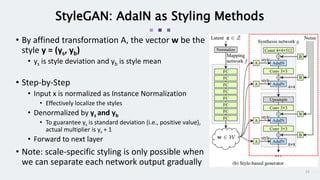
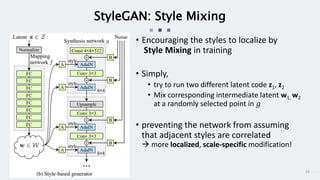
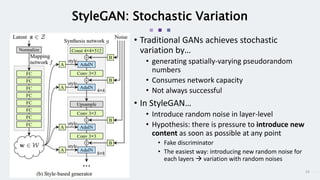
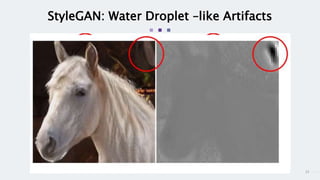
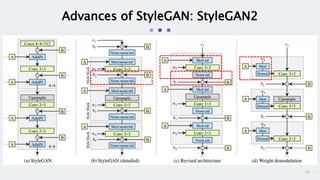
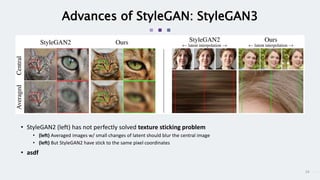
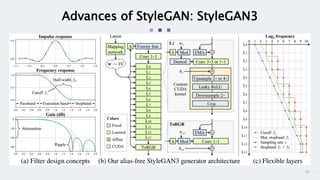
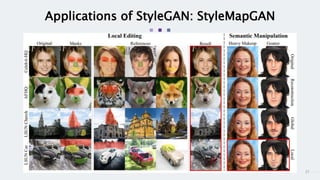
StyleGAN is a generative adversarial network that achieves disentangled and scalable image generation. It uses adaptive instance normalization (AdaIN) to modify feature statistics at different scales, allowing scale-specific image stylization. The generator is designed as a learned mapping from latent space to image space. Latent codes are fed into each layer and transformed through AdaIN to modify feature statistics. This disentangles high-level attributes like pose, hair, etc. and allows controllable image synthesis through interpolation in latent space.







































![[Paper Reading] Attention is All You Need](https://cdn.slidesharecdn.com/ss_thumbnails/reading20181228-190111054908-thumbnail.jpg?width=640&height=640&fit=bounds)




















































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)











