Downloaded 17 times


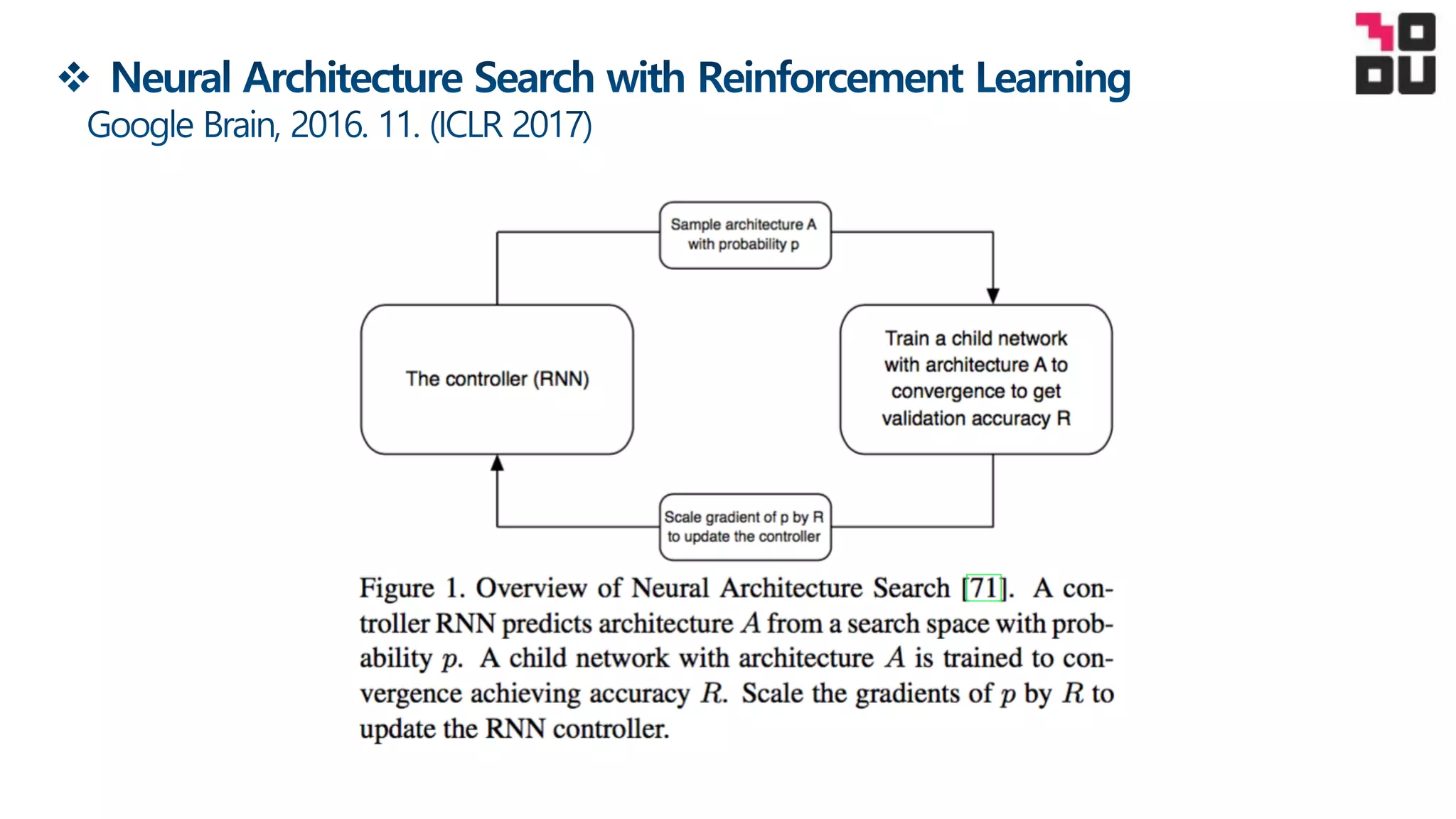

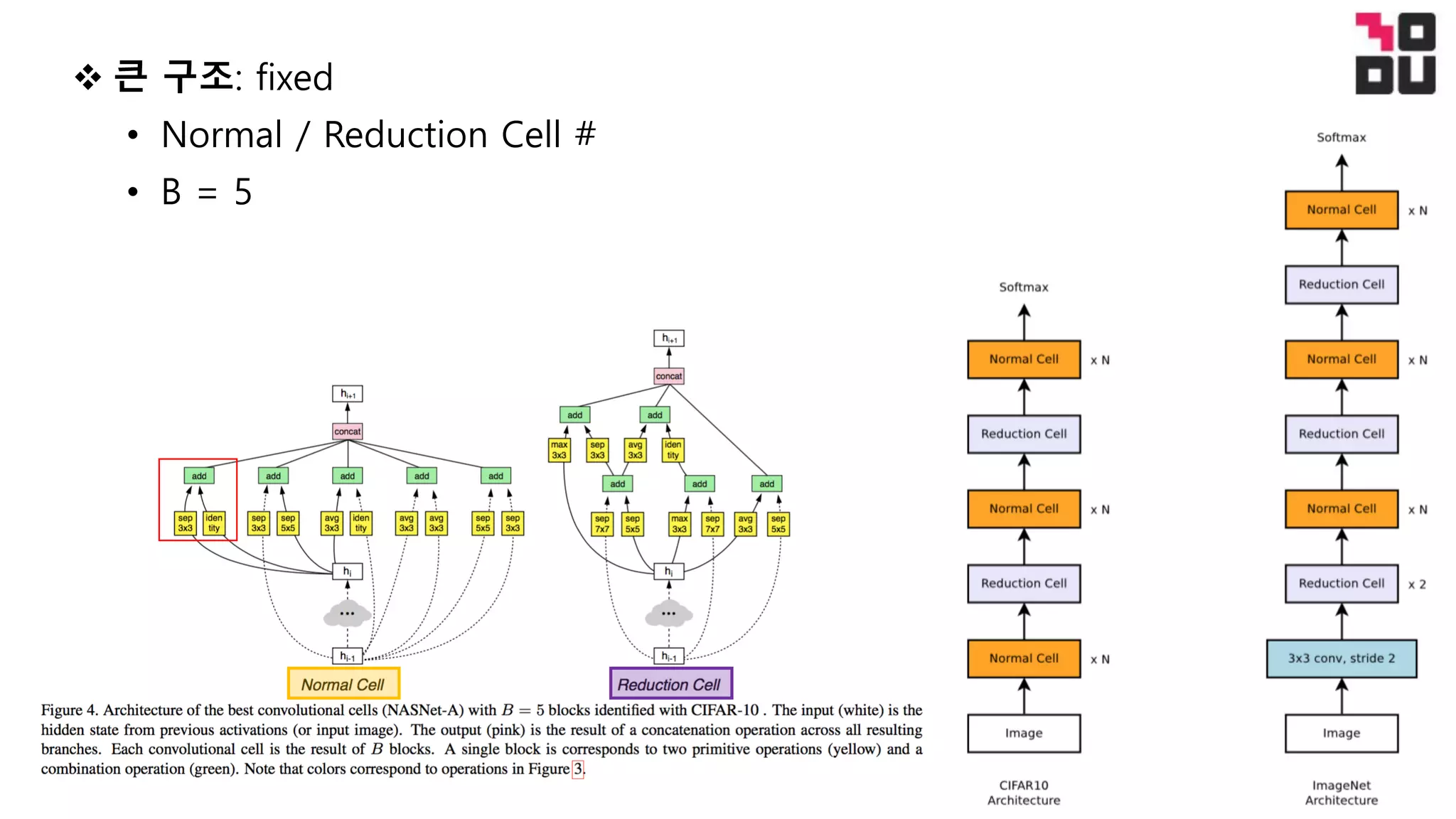
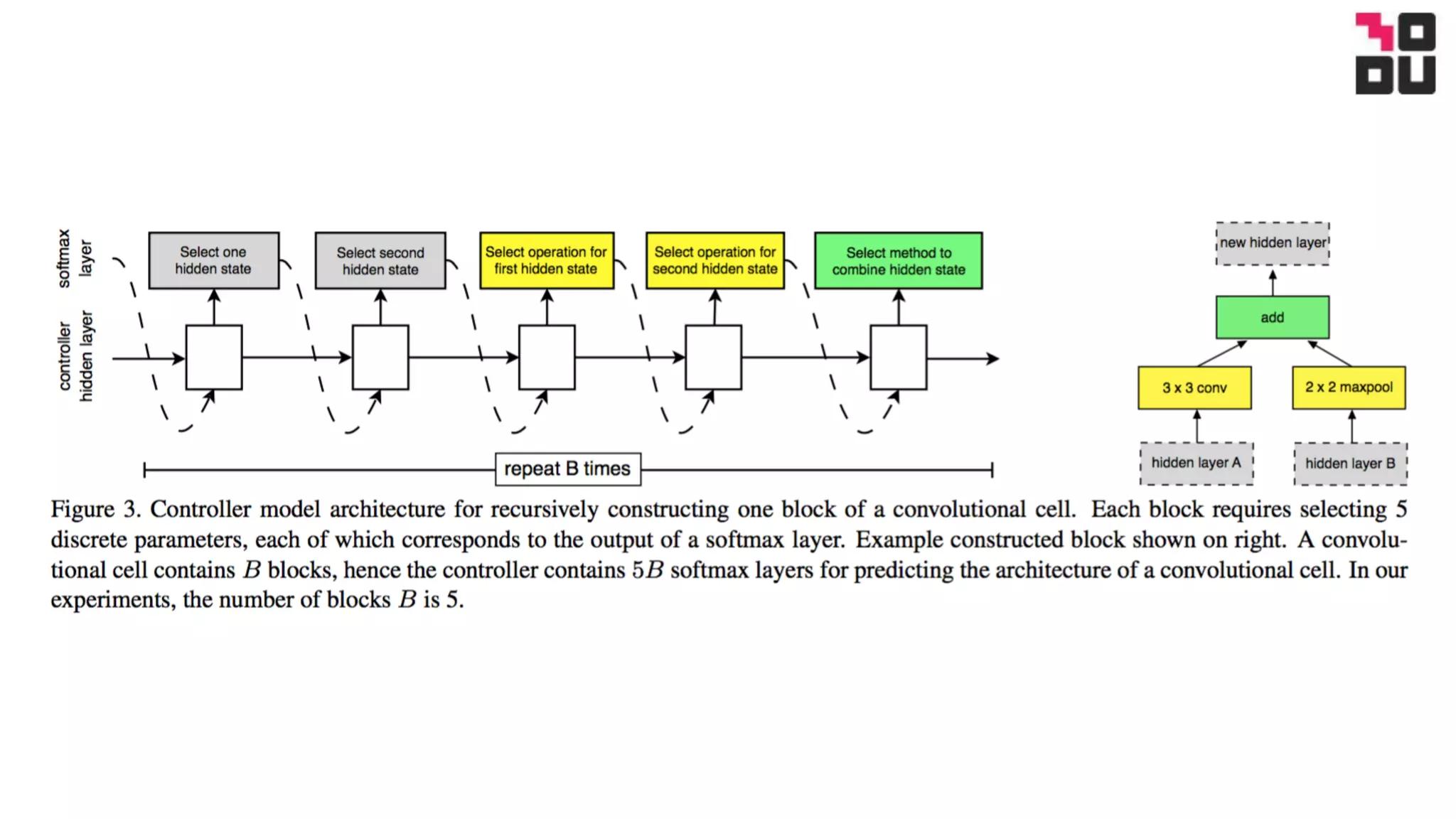
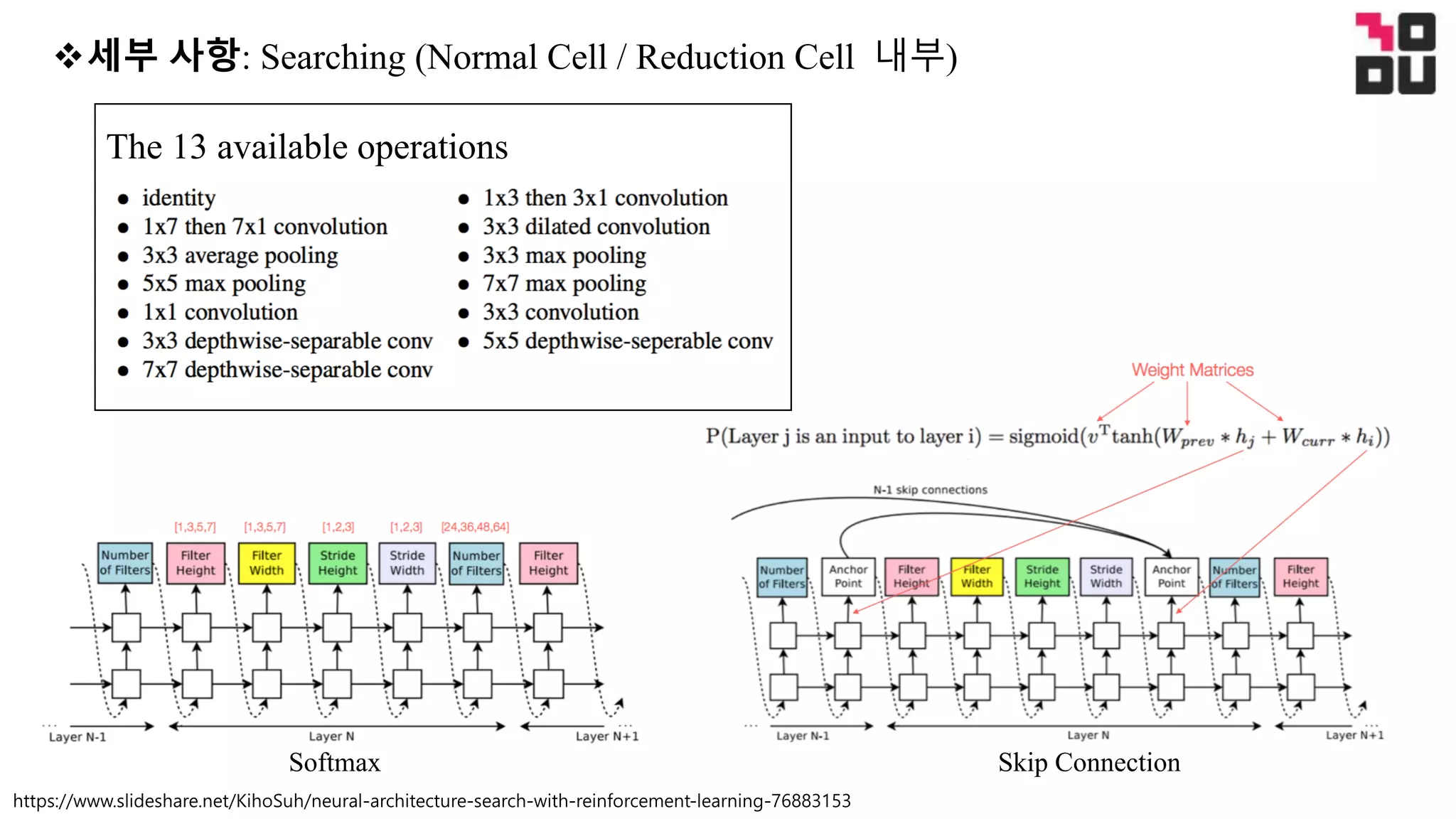

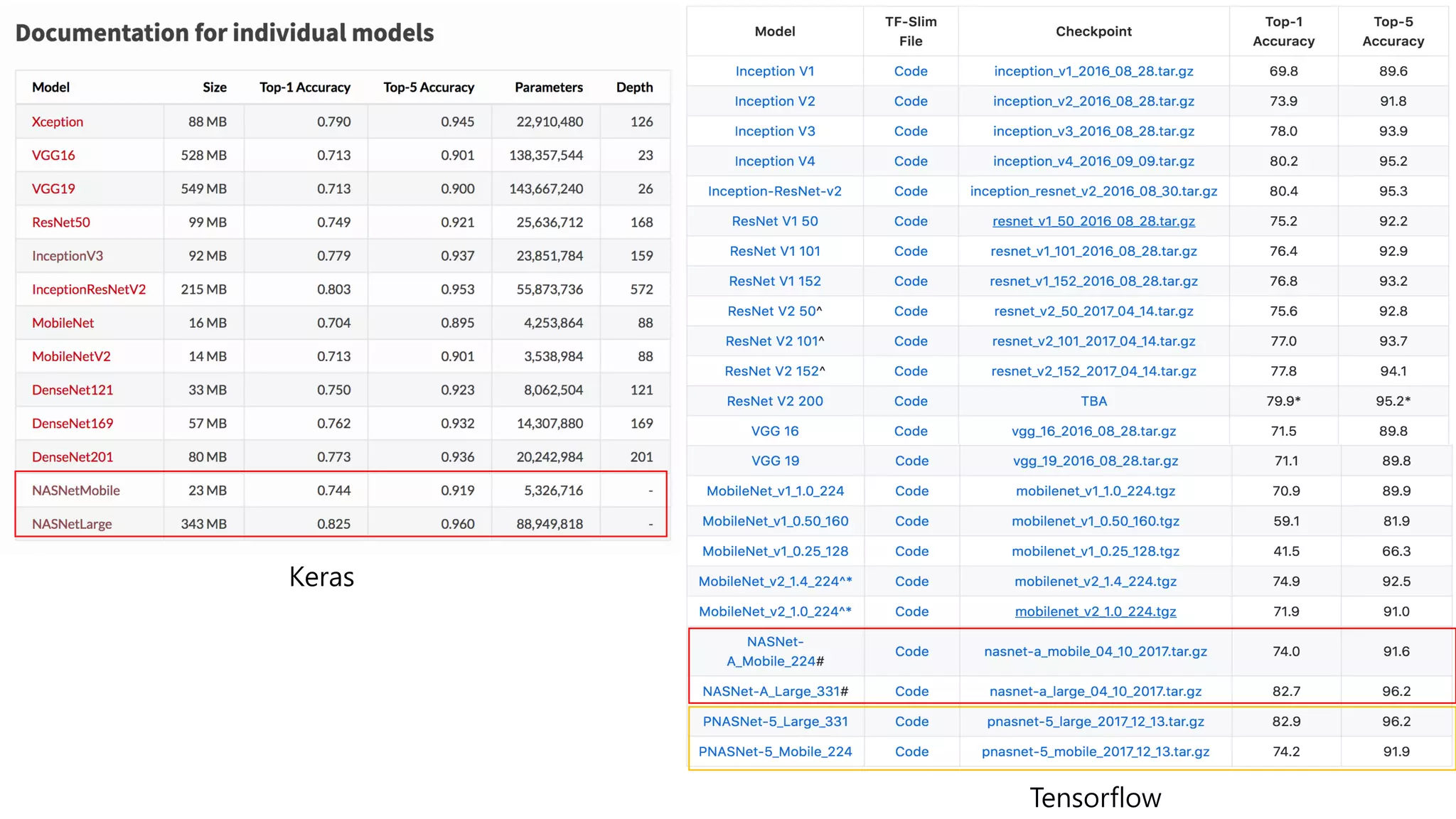



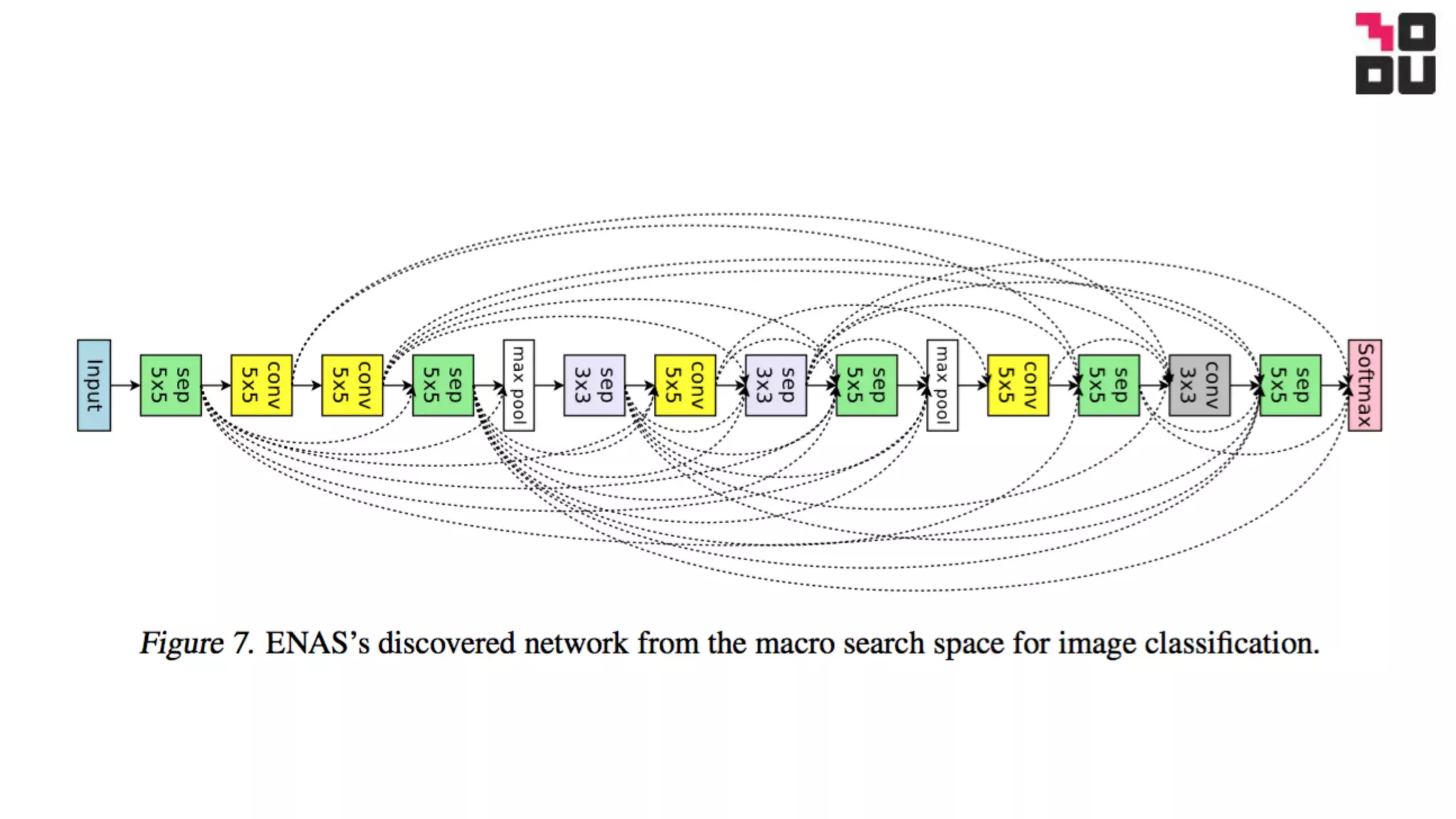

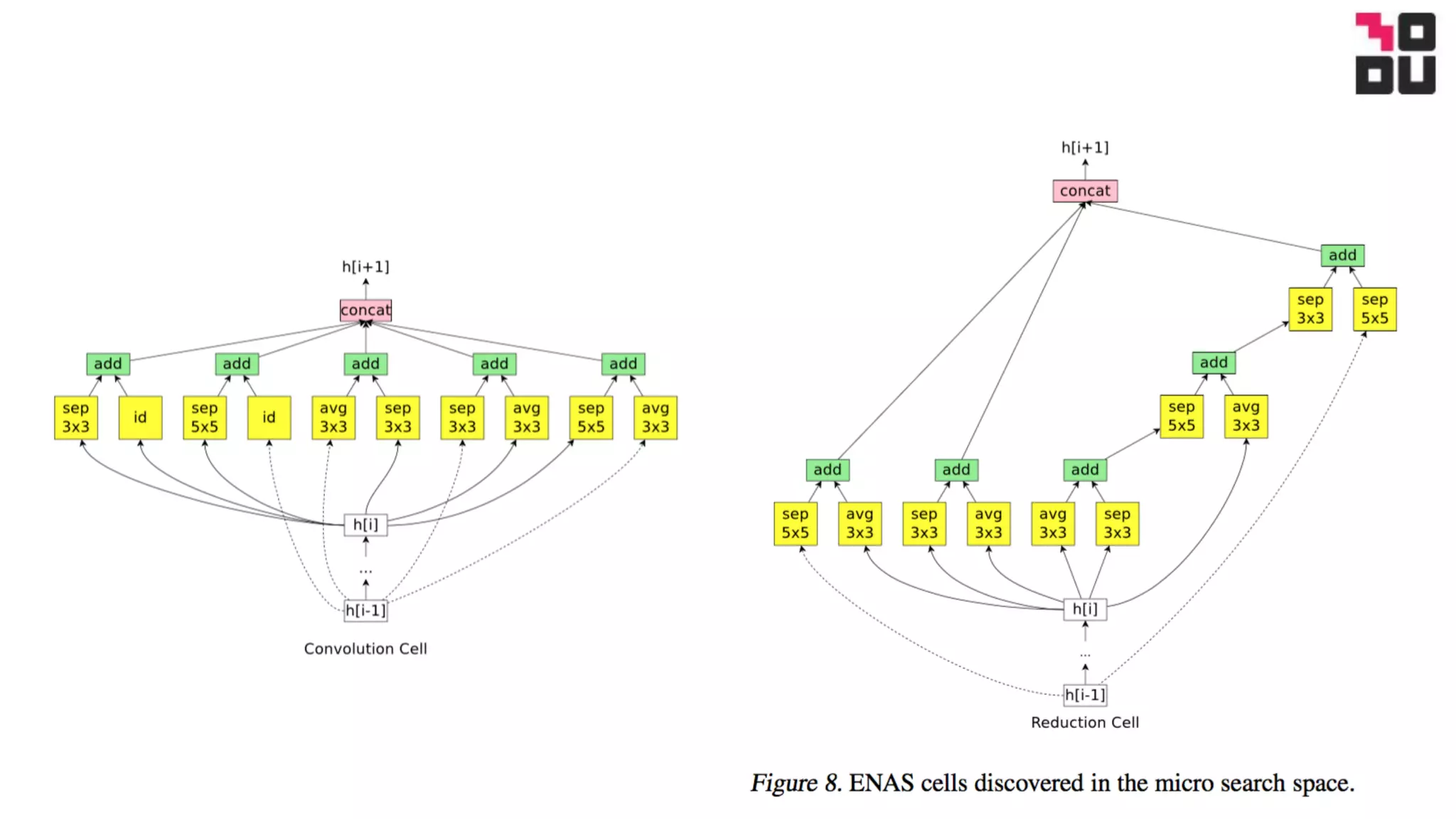







This document summarizes a neural architecture search technique using parameter sharing between child models. Specifically: - It improves efficiency over traditional NAS by forcing all child models to share weights, avoiding training each from scratch to convergence. This reduces GPU hours needed for search from tens of thousands to less than 16 hours on a single GPU. - The search is done in two stages: first a macro search over 7 hours to determine the overall structure, then a micro search over 11.5 hours to determine the operations within each cell block. - It uses a directed acyclic graph to represent the neural network, with nodes representing local computations and edges determining information flow. The controller searches over the space of possible child models within





![[243] turning data into value](https://cdn.slidesharecdn.com/ss_thumbnails/234turningdataintovalue-150915052705-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)










![[251] implementing deep learning using cu dnn](https://cdn.slidesharecdn.com/ss_thumbnails/215implementingdeeplearningusingcudnn-150915052020-lva1-app6892-thumbnail.jpg?width=640&height=640&fit=bounds)























































