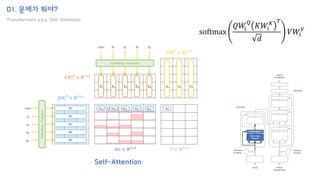
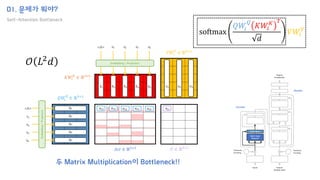
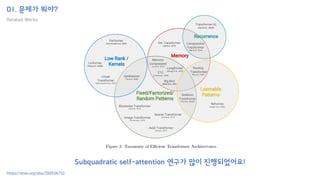
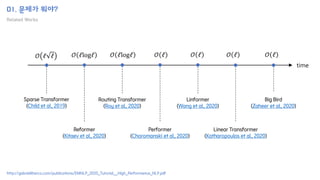
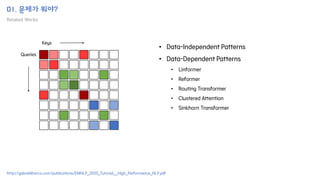
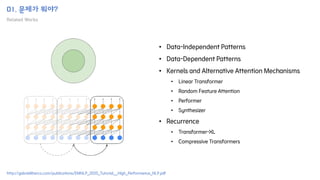
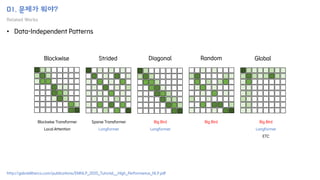
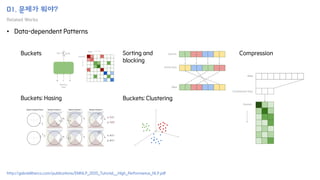
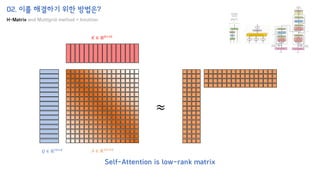
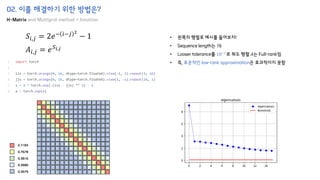
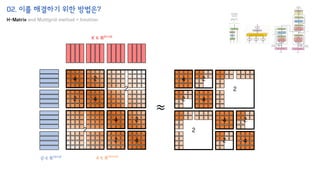
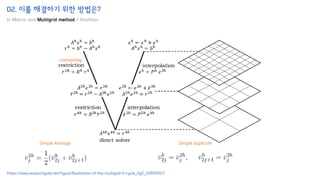
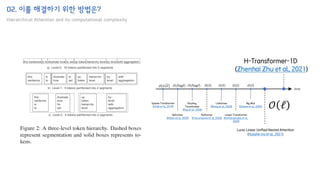
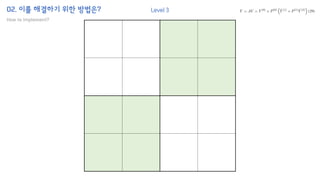
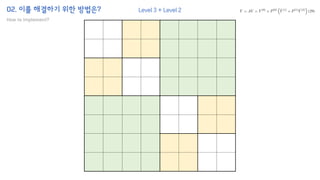
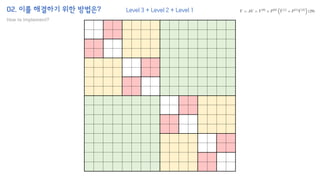
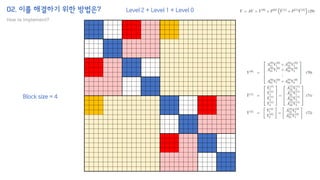
The document introduces the H-Transformer-1D model for fast one dimensional hierarchical attention on sequences. It begins by discussing the self-attention mechanism in Transformers and how it has achieved state-of-the-art results across many tasks. However, self-attention has a computational complexity of O(n2) due to the quadratic matrix operations, which becomes a bottleneck for long sequences. The document then reviews related works that aim to reduce this complexity through techniques like sparse attention. It proposes using H-matrix and multigrid methods from numerical analysis to hierarchically decompose the attention matrix and make it sparse. The following sections will explain how this is applied in H-Transformer-1D and how it can be implemented
















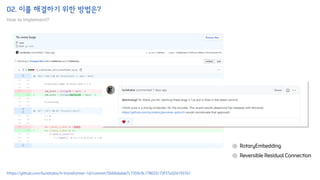
![02. 이를 해결하기 위한 방법은?
How to implement?
"안녕하세요 오늘 논문 읽기 모임에 참여한 여러분들 모두 환영합니다 Google의 논문인데 많이 아쉽네요"
['▁안녕', '하세요', '▁오늘', '▁논문', '▁읽', '기', '▁모임', '에', '▁참여한', '▁여러분', '들', '▁모두', '▁환영', '합', '니다', '▁G', 'oo', 'g', 'le', '의', '▁논문', '인데', '▁많이', '▁아쉽', '네요']
[22465, 23935, 14864, 24313, 15350, 9264, 19510, 11786, 19205, 18918, 9993, 14422, 20603, 13600, 20211, 15464, 24327, 302, 16203, 12024, 24313, 15094, 14605, 26180, 29221]
(bsz,) == (1,)
(bsz, seq_len) == (1, 25)
(bsz, seq_len) == (1, 25)](https://image.slidesharecdn.com/h-transformer-1d-210830061515/85/H-transformer-1d-paper-review-33-320.jpg)
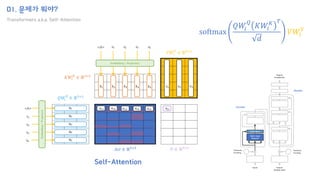
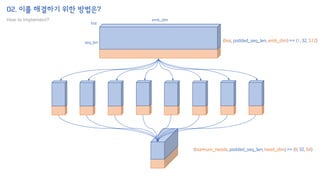
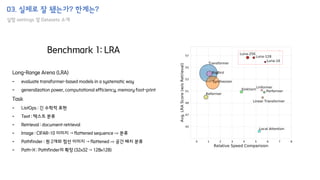
![02. 이를 해결하기 위한 방법은?
How to implement?
"안녕하세요 오늘 논문 읽기 모임에 참여한 여러분들 모두 환영합니다 Google의 논문인데 많이 아쉽네요"
['▁안녕', '하세요', '▁오늘', '▁논문', '▁읽', '기', '▁모임', '에', '▁참여한', '▁여러분', '들', '▁모두', '▁환영', '합', '니다', '▁G', 'oo', 'g', 'le', '의', '▁논문', '인데', '▁많이', '▁아쉽', '네요']
[22465, 23935, 14864, 24313, 15350, 9264, 19510, 11786, 19205, 18918, 9993, 14422, 20603, 13600, 20211, 15464, 24327, 302, 16203, 12024, 24313, 15094, 14605, 26180, 29221]
(bsz,) == (1,)
(bsz, seq_len) == (1, 25)
(bsz, seq_len) == (1, 25)
(bsz, seq_len, emb_dim) == (1, 25, 512)
bsz
seq_len
emb_dim](https://image.slidesharecdn.com/h-transformer-1d-210830061515/85/H-transformer-1d-paper-review-34-320.jpg)
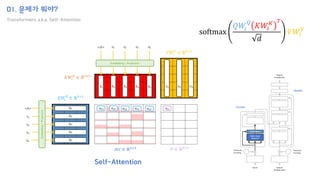
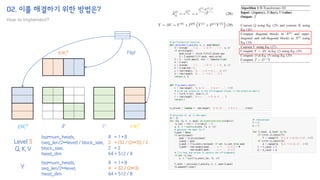
![02. 이를 해결하기 위한 방법은?
How to implement?
"안녕하세요 오늘 논문 읽기 모임에 참여한 여러분들 모두 환영합니다 Google의 논문인데 많이 아쉽네요"
['▁안녕', '하세요', '▁오늘', '▁논문', '▁읽', '기', '▁모임', '에', '▁참여한', '▁여러분', '들', '▁모두', '▁환영', '합', '니다', '▁G', 'oo', 'g', 'le', '의', '▁논문', '인데', '▁많이', '▁아쉽', '네요']
[22465, 23935, 14864, 24313, 15350, 9264, 19510, 11786, 19205, 18918, 9993, 14422, 20603, 13600, 20211, 15464, 24327, 302, 16203, 12024, 24313, 15094, 14605, 26180, 29221]
(bsz,) == (1,)
(bsz, seq_len) == (1, 25)
(bsz, seq_len) == (1, 25)
bsz
seq_len
(bsz, padded_seq_len, emb_dim) == (1, 32, 512)
emb_dim](https://image.slidesharecdn.com/h-transformer-1d-210830061515/85/H-transformer-1d-paper-review-35-320.jpg)
























![[IGC2015] 아라소판단 김성욱-게임 기획을 변경하게 되는 요인](https://cdn.slidesharecdn.com/ss_thumbnails/random-151005033642-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)






![[KGC 2012] Online Game Server Architecture Case Study Performance and Security](https://cdn.slidesharecdn.com/ss_thumbnails/kgc2012-20121009-new-18-f-sladeshare-130927202856-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)
![[IGC 2017] 펄어비스 민경인 - Mmorpg를 위한 voxel 기반 네비게이션 라이브러리 개발기](https://cdn.slidesharecdn.com/ss_thumbnails/mmorpgvoxel-170905061528-thumbnail.jpg?width=640&height=640&fit=bounds)















![[0114]hyun wook](https://cdn.slidesharecdn.com/ss_thumbnails/0114hyunwook-200316022403-thumbnail.jpg?width=640&height=640&fit=bounds)


![[2A4]DeepLearningAtNAVER](https://cdn.slidesharecdn.com/ss_thumbnails/2a4deeplearningatnaver-140929210707-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)









































