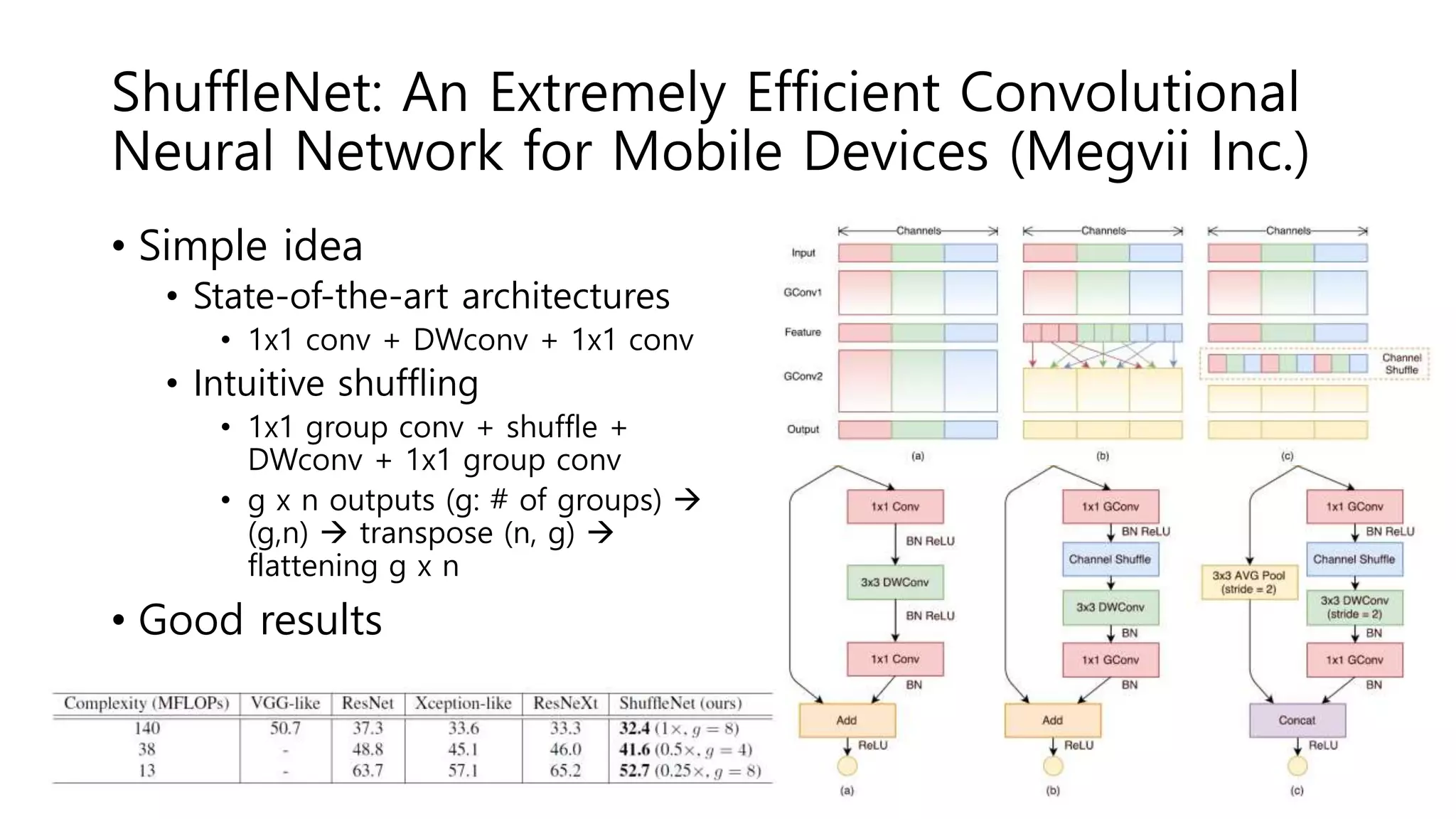
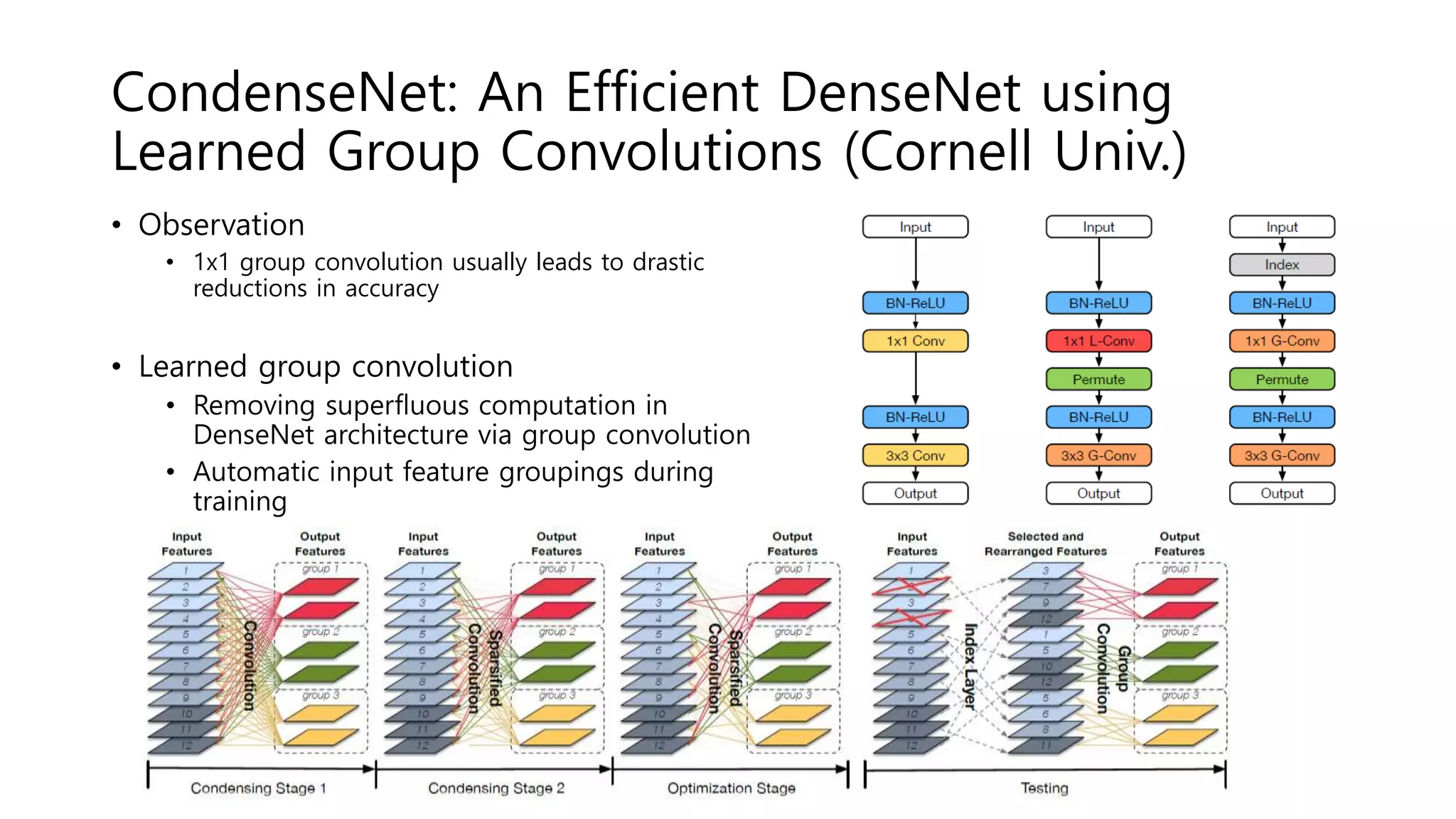
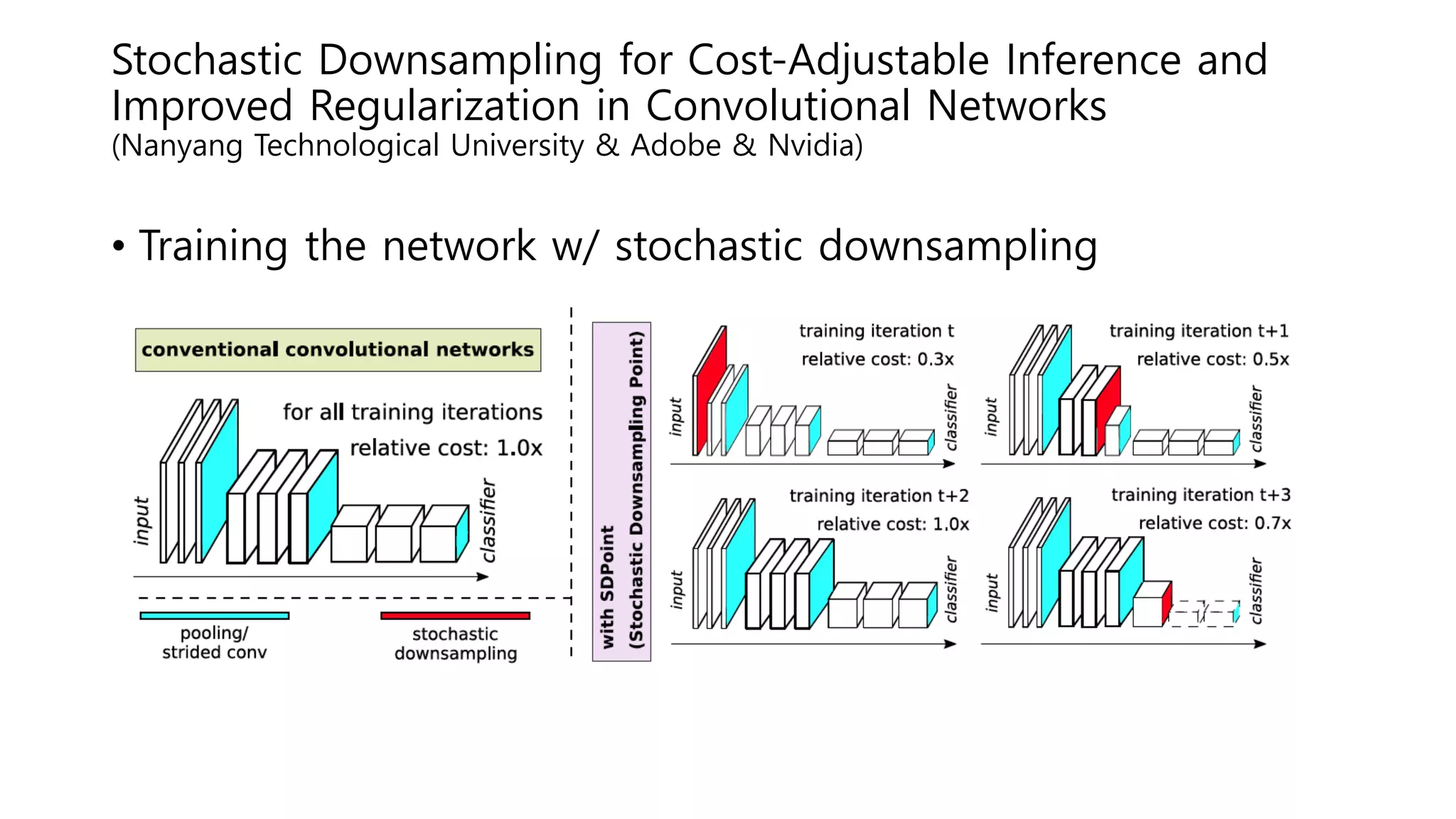
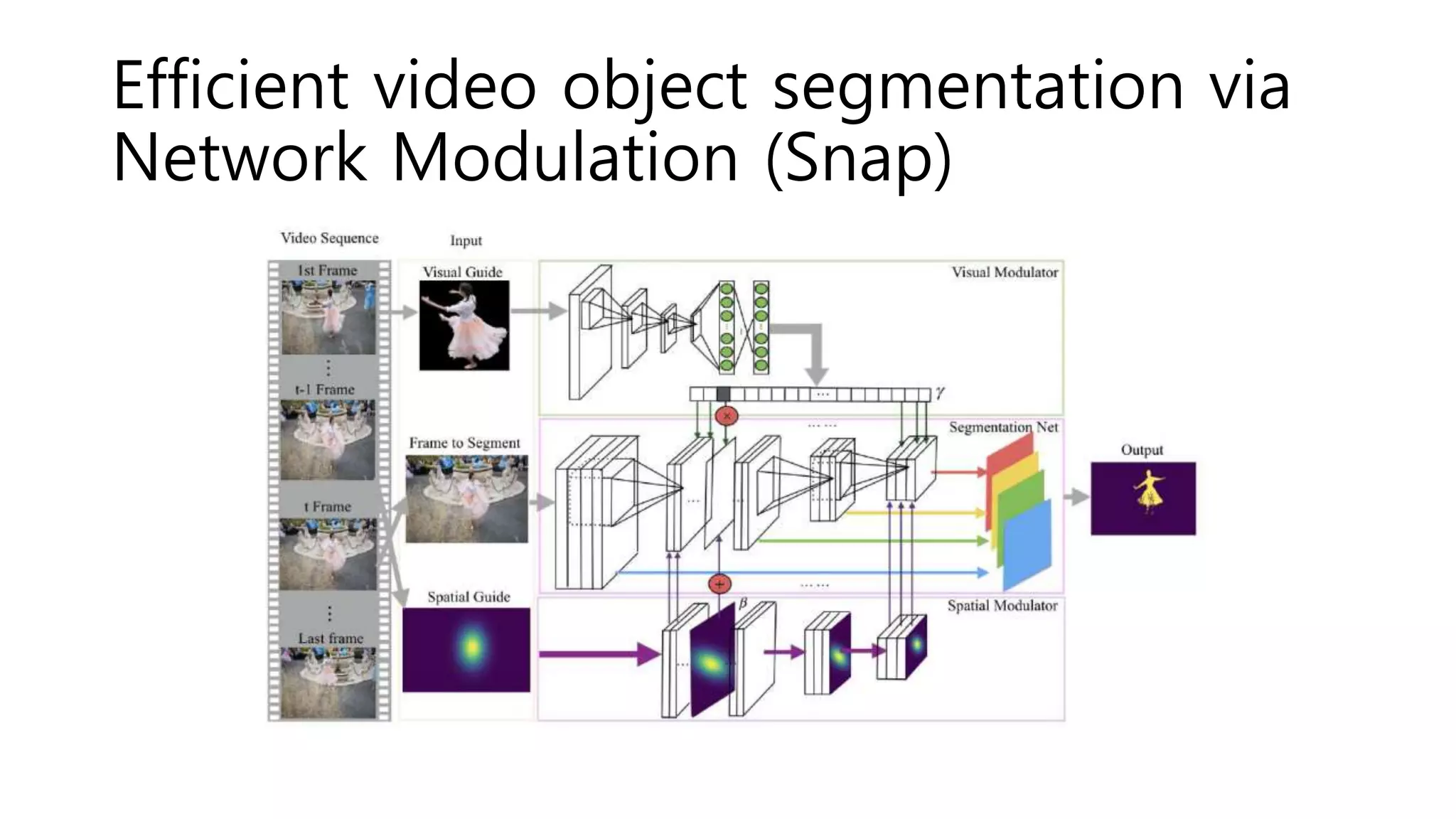
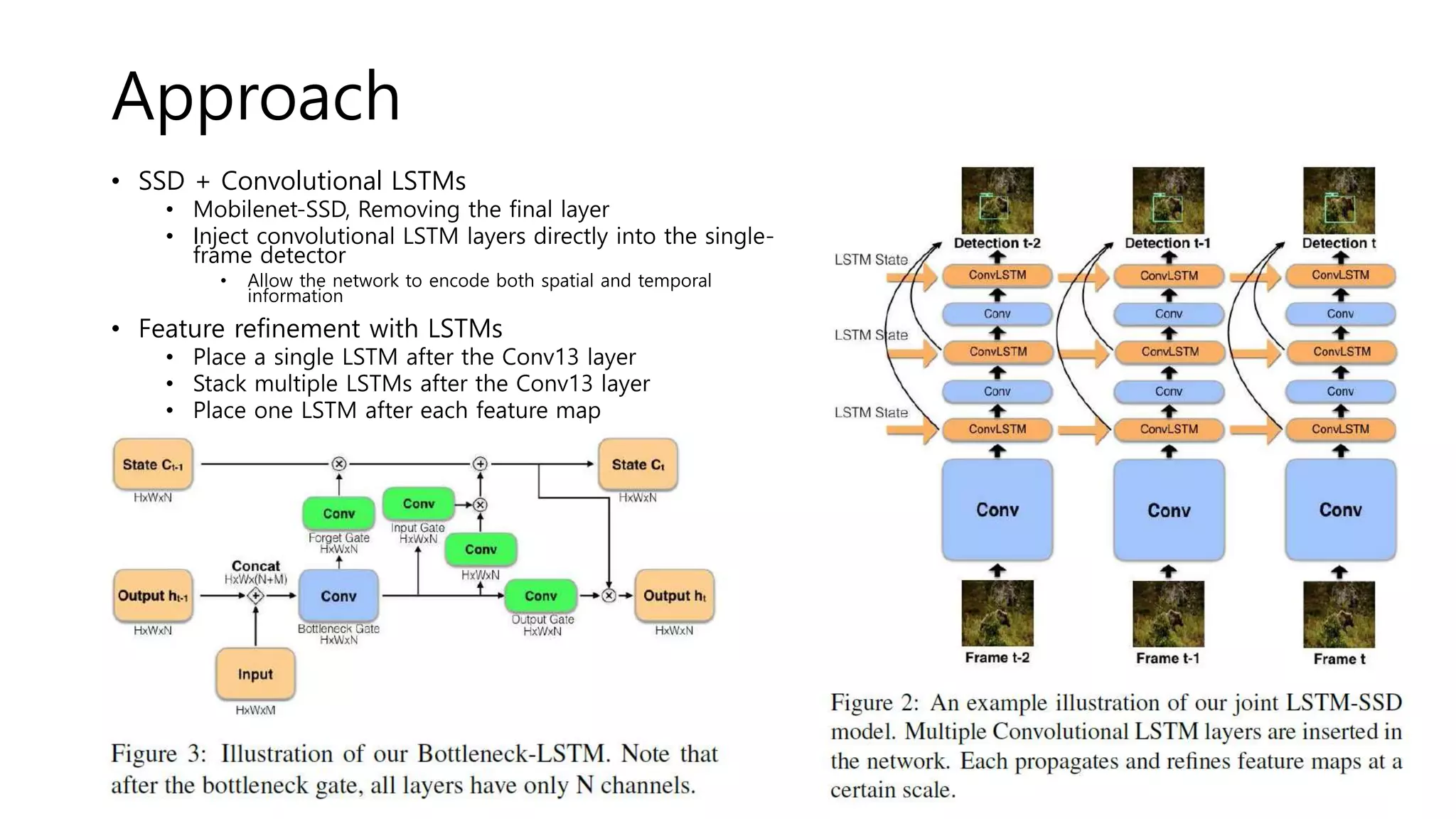
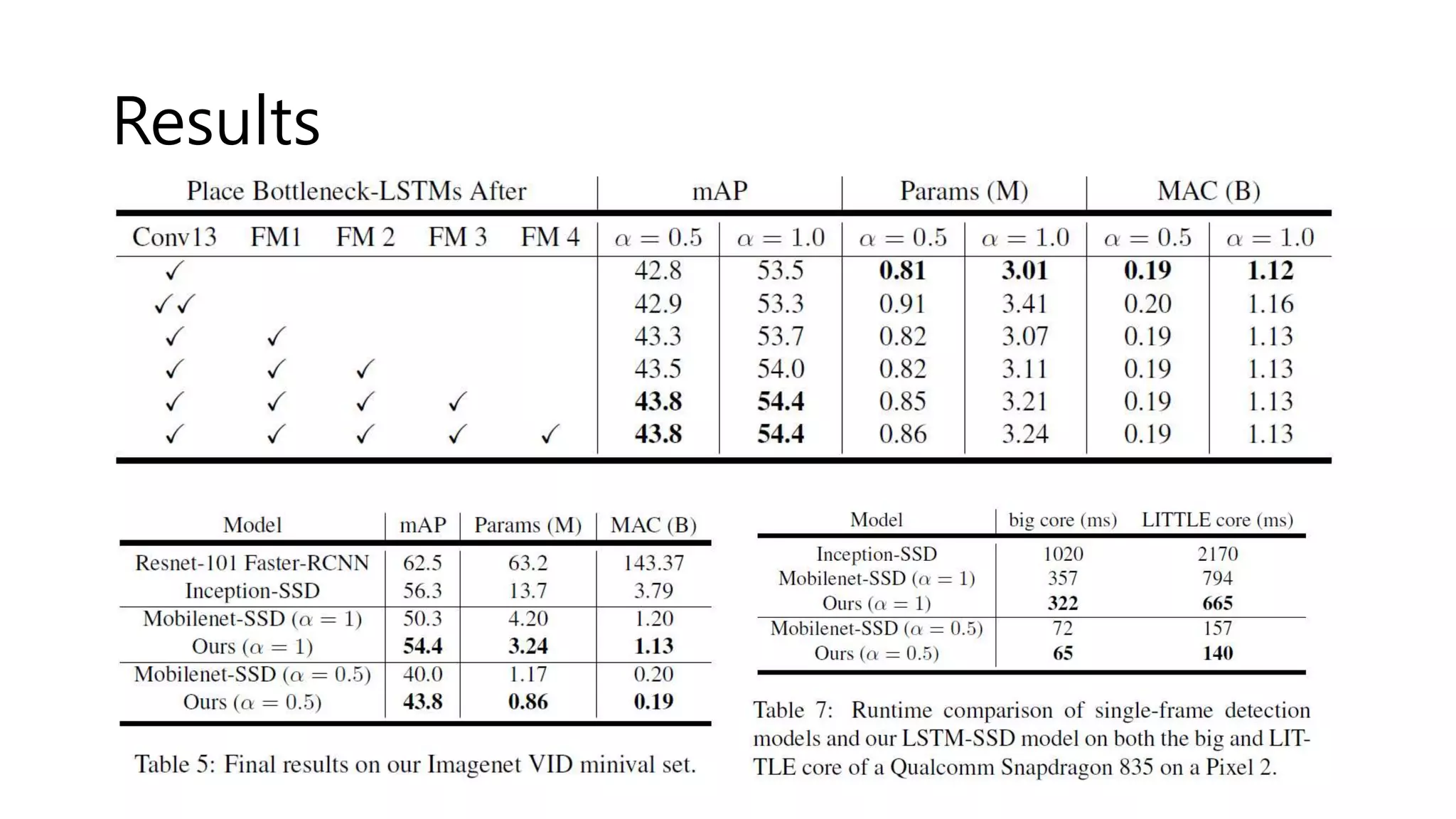
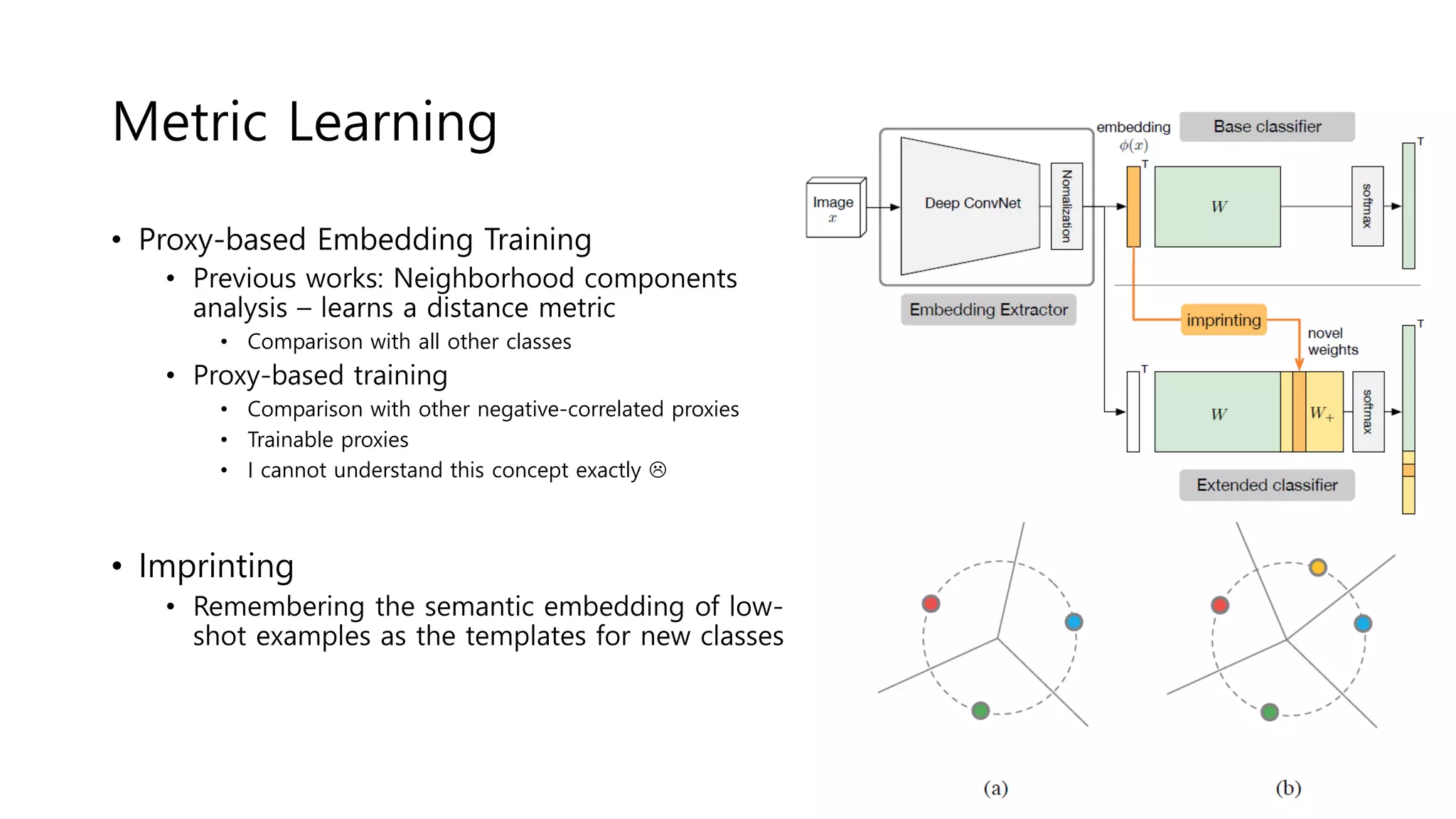
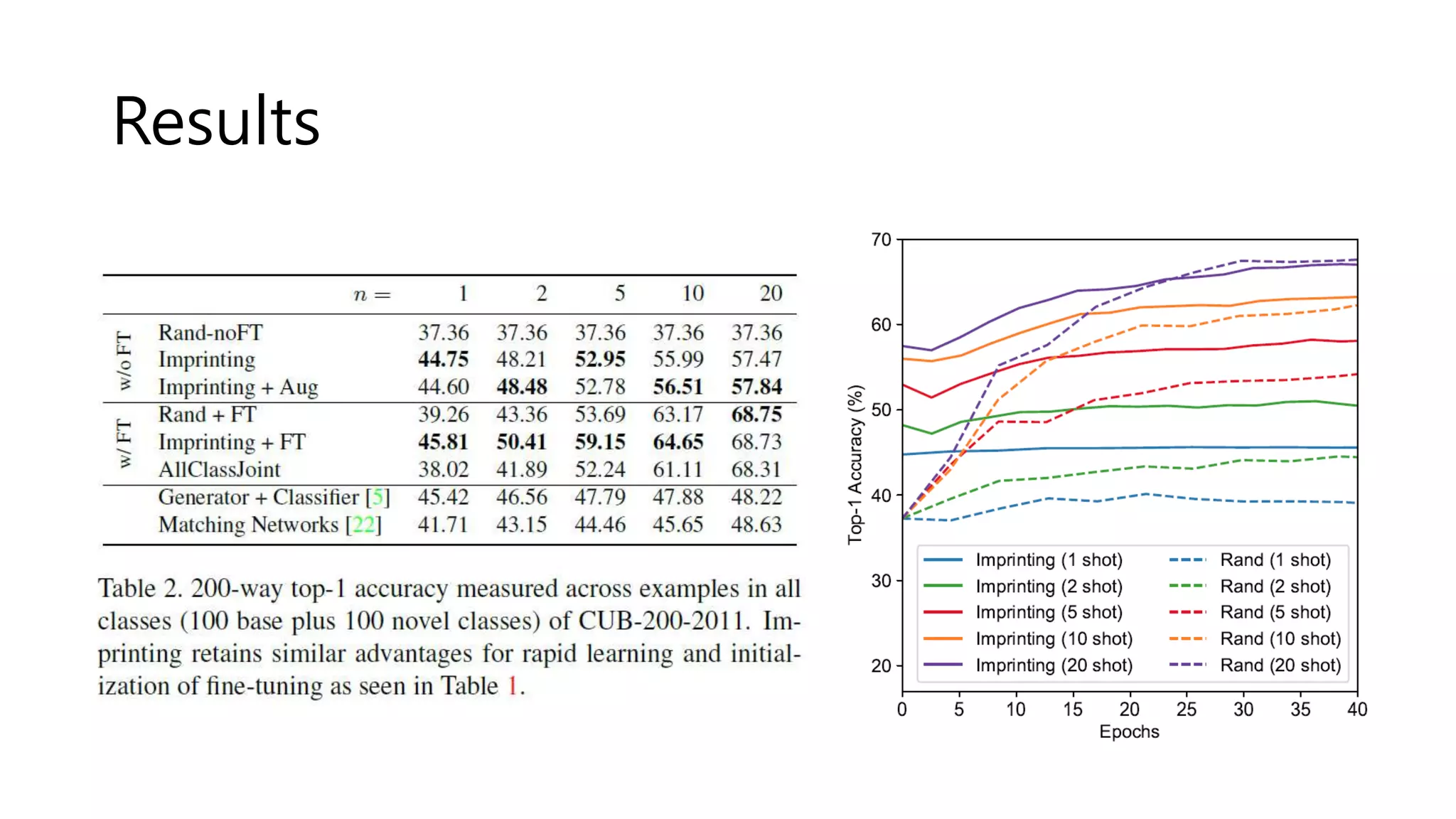
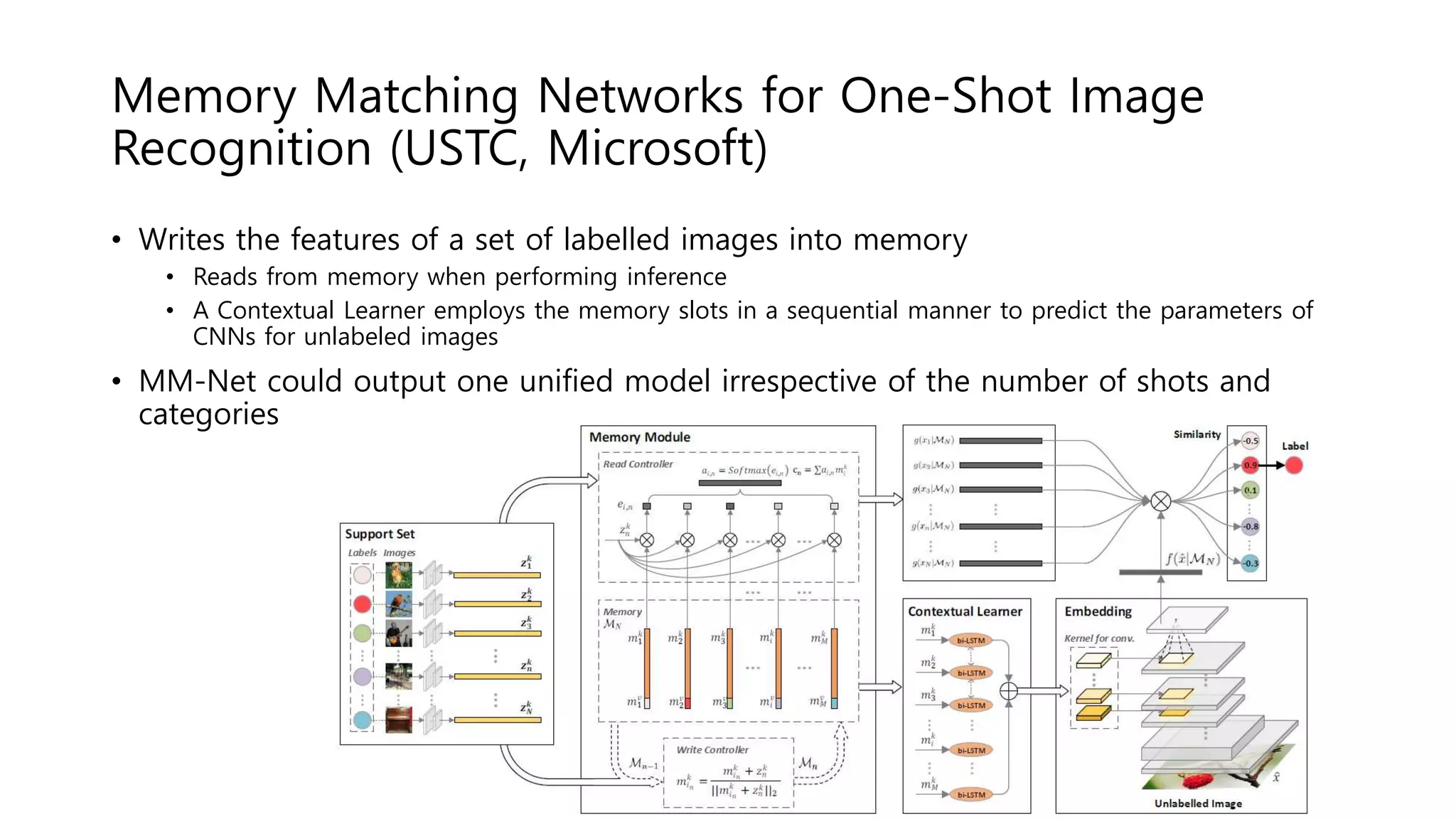
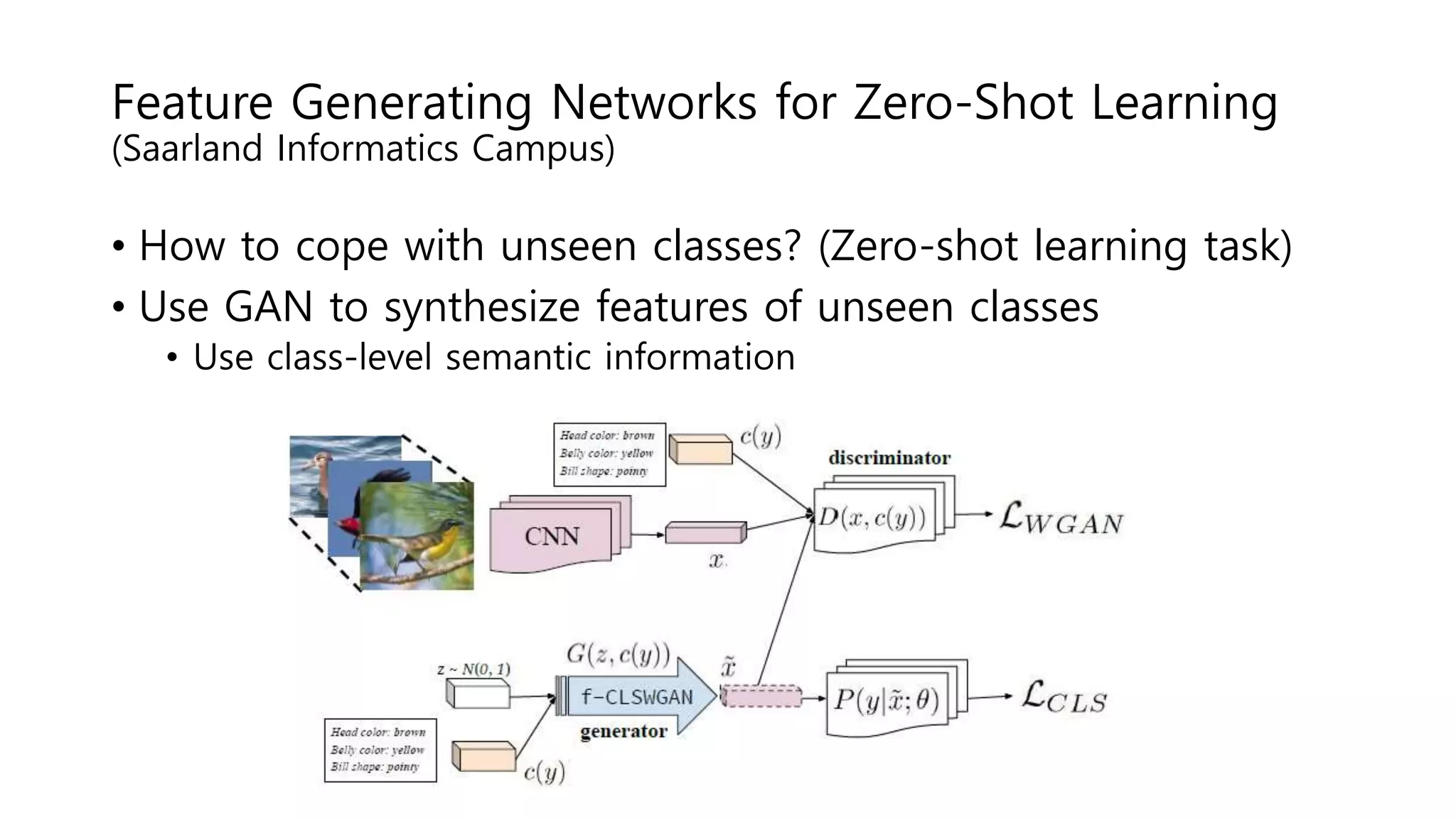
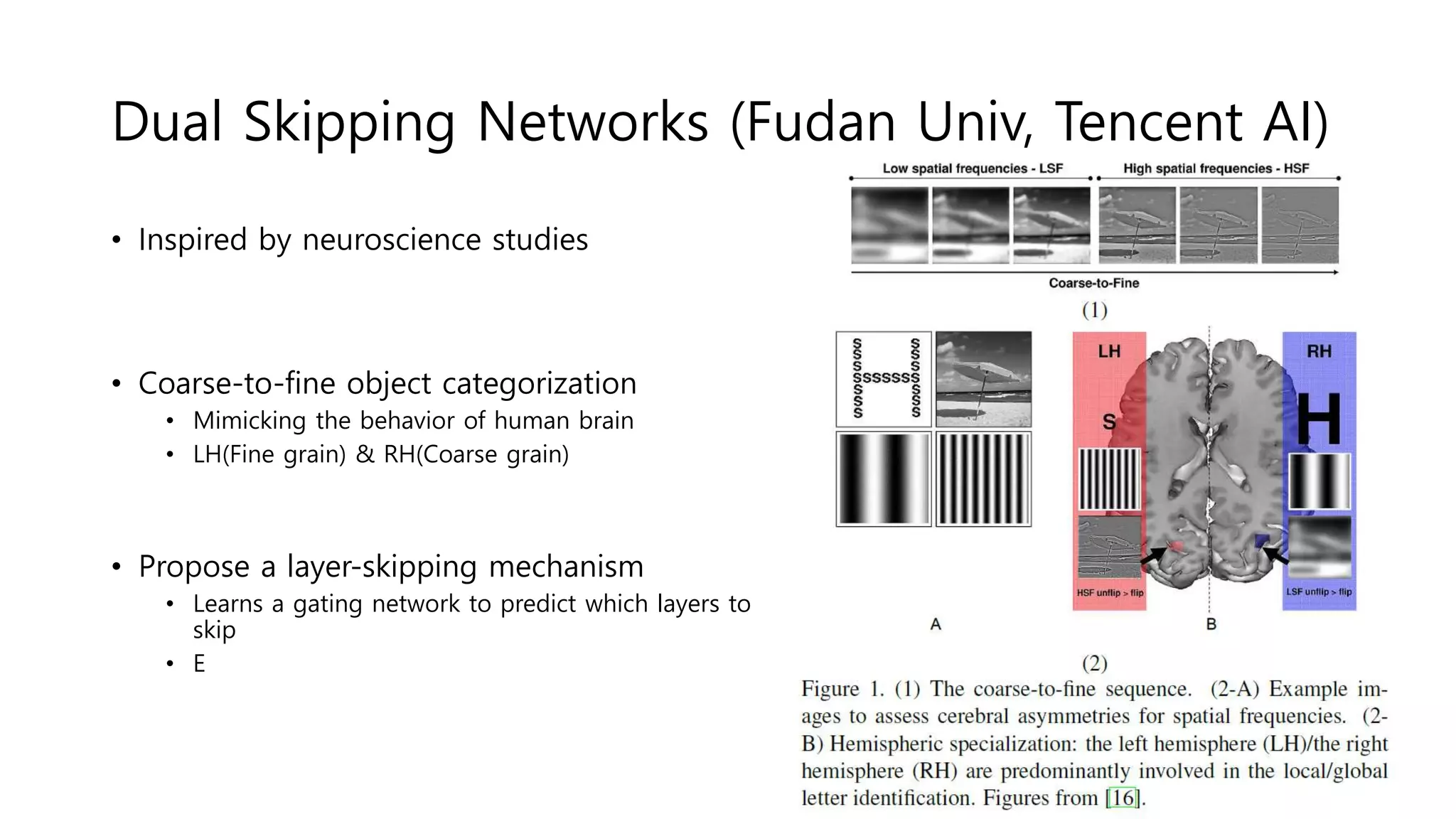
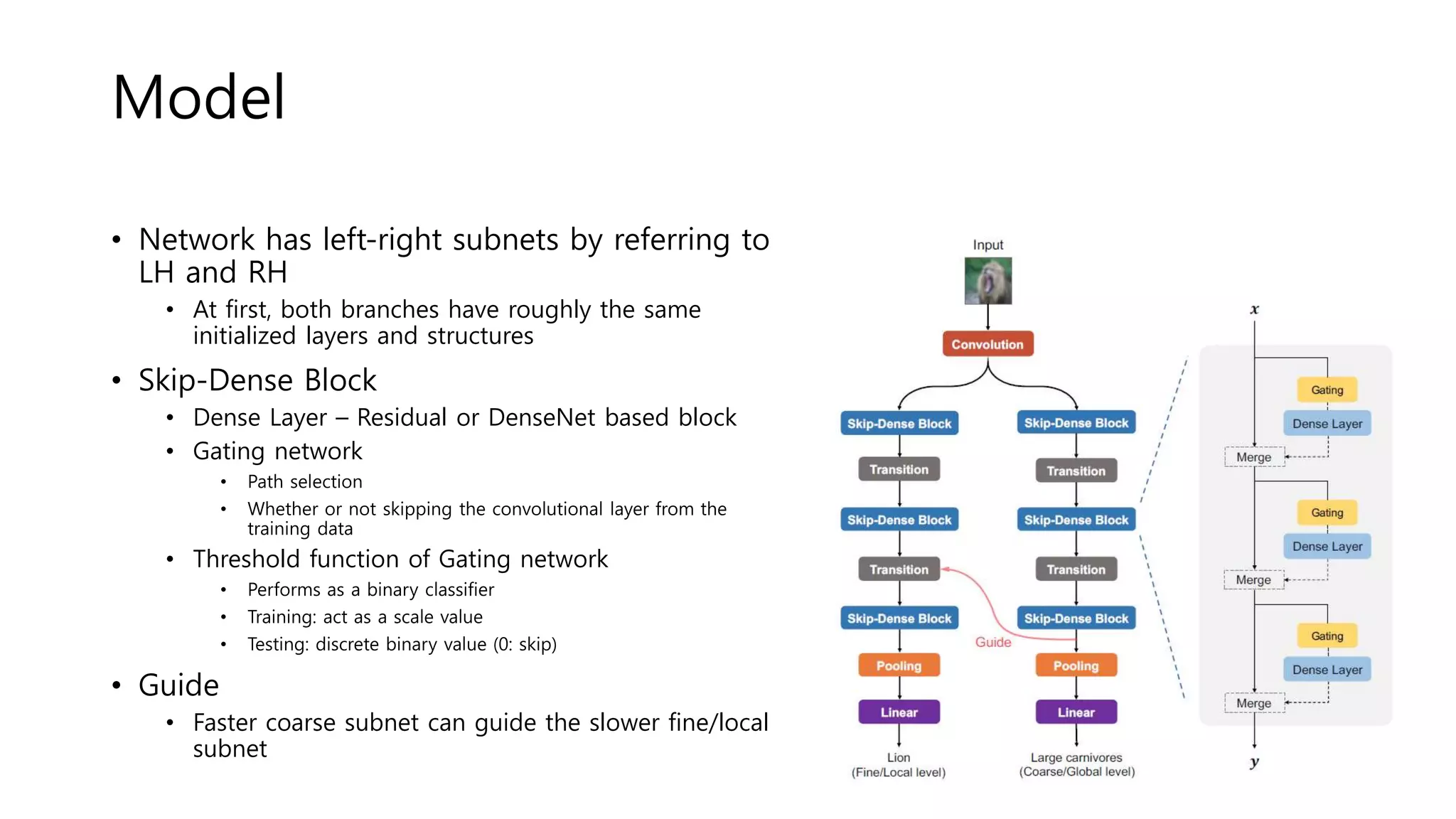
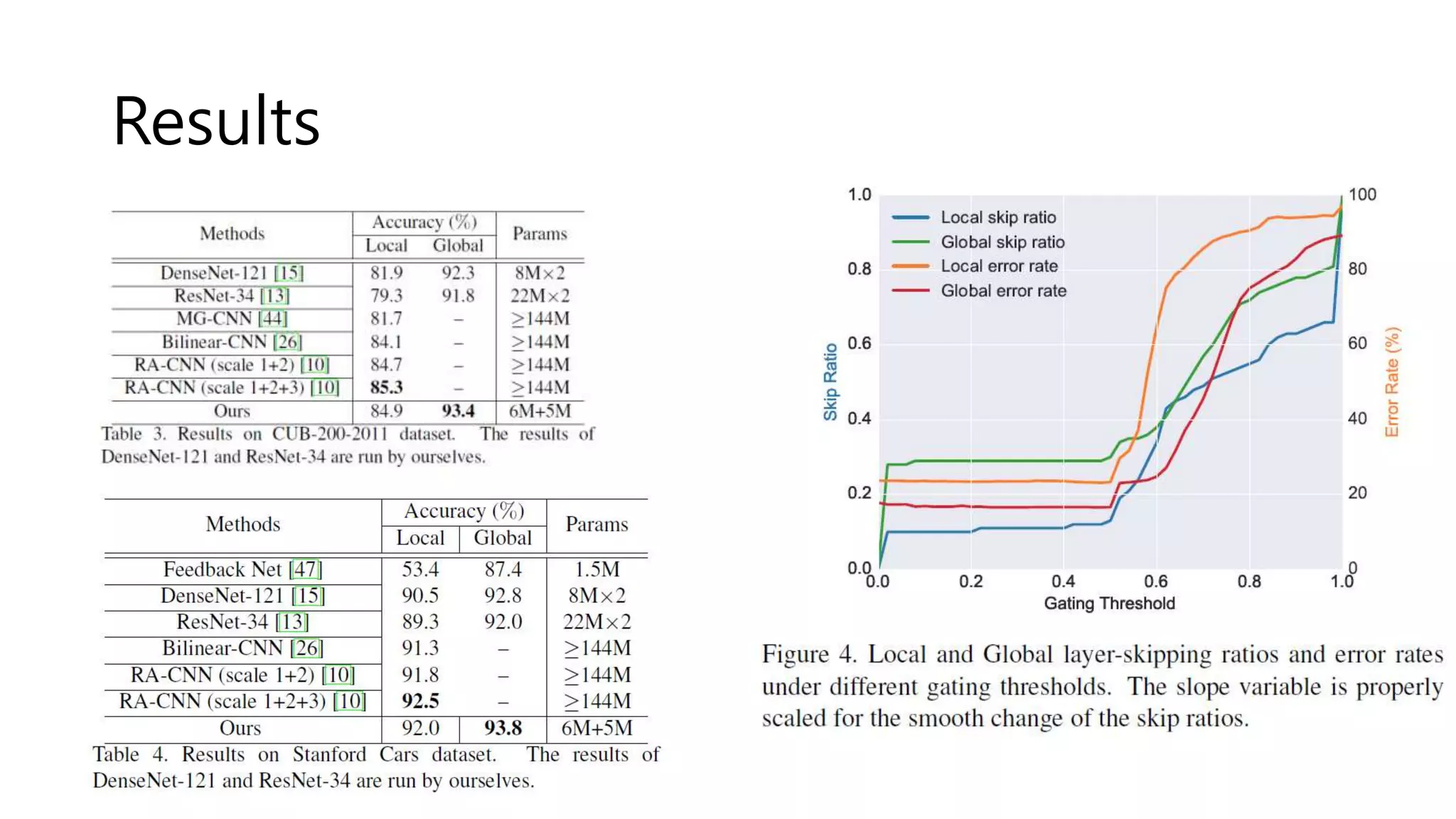
The document reviews various papers presented at CVPR 2018, focusing on neural network optimization for mobile applications and efficiency improvements through different algorithms. Key topics include platform-aware neural network adaptation, automated compression methods, quantization techniques, and innovative architectures for video object segmentation. It highlights contributions from various studies aimed at enhancing accuracy, computational efficiency, and resource management in deep learning models.



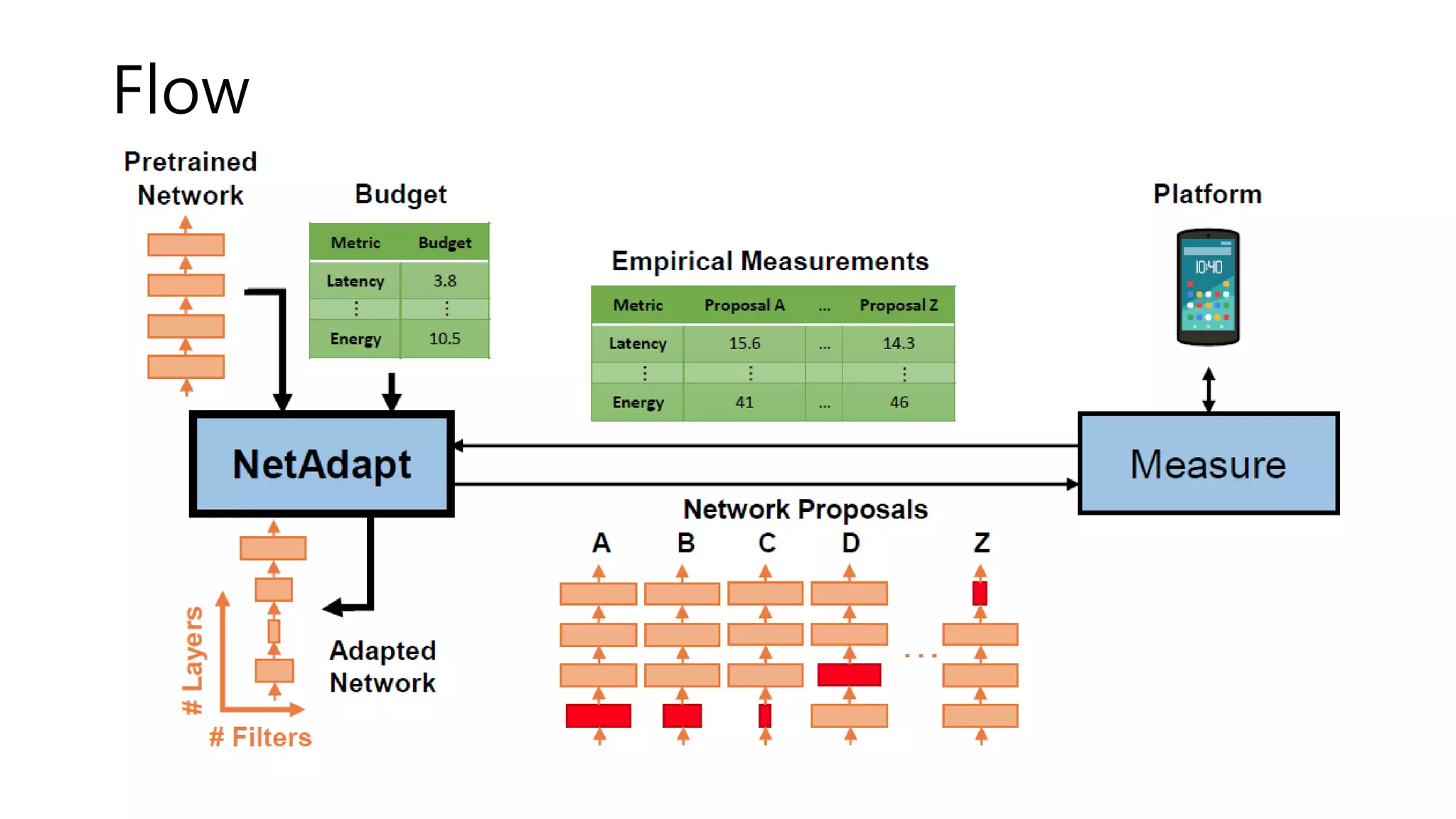
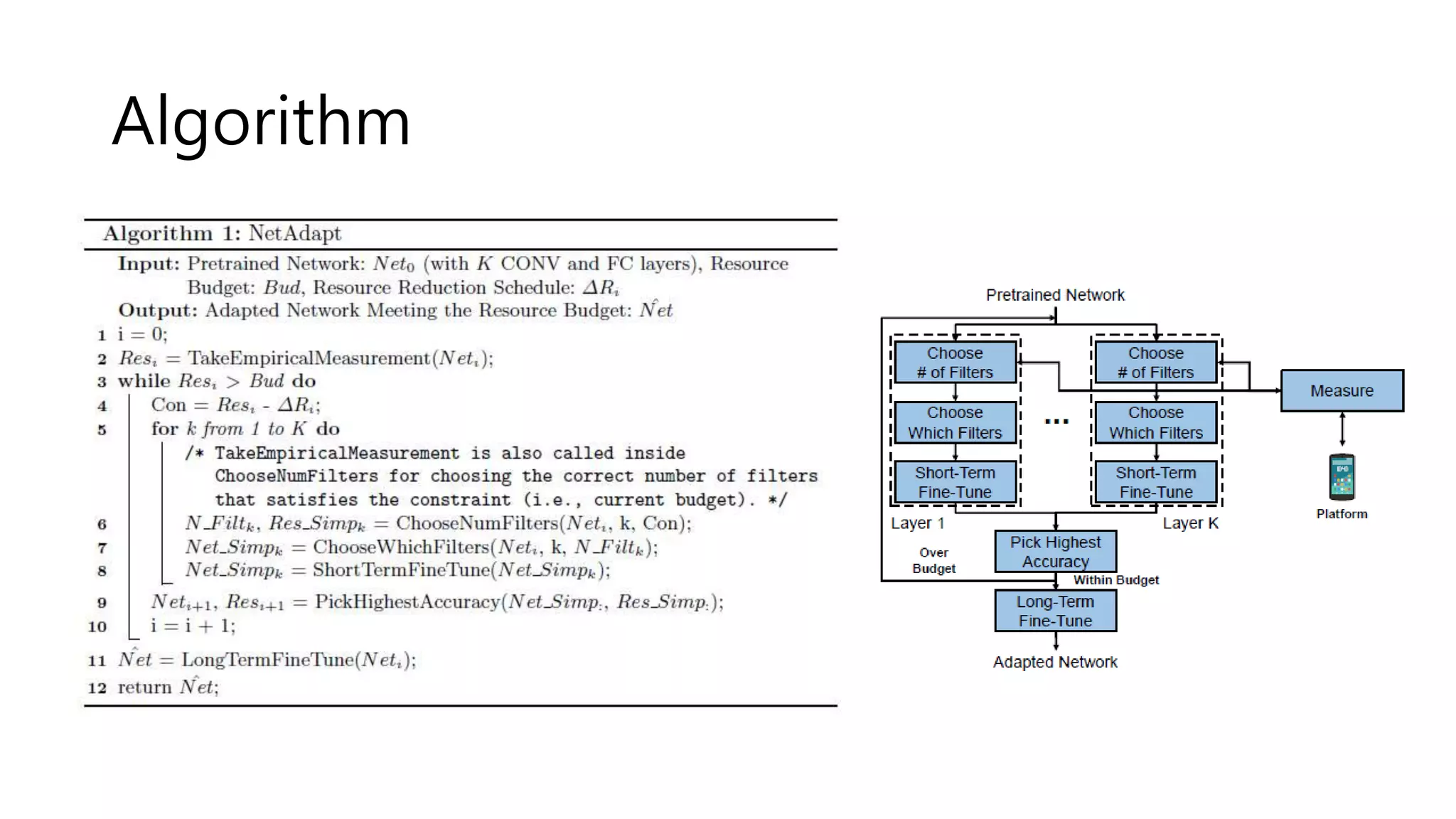

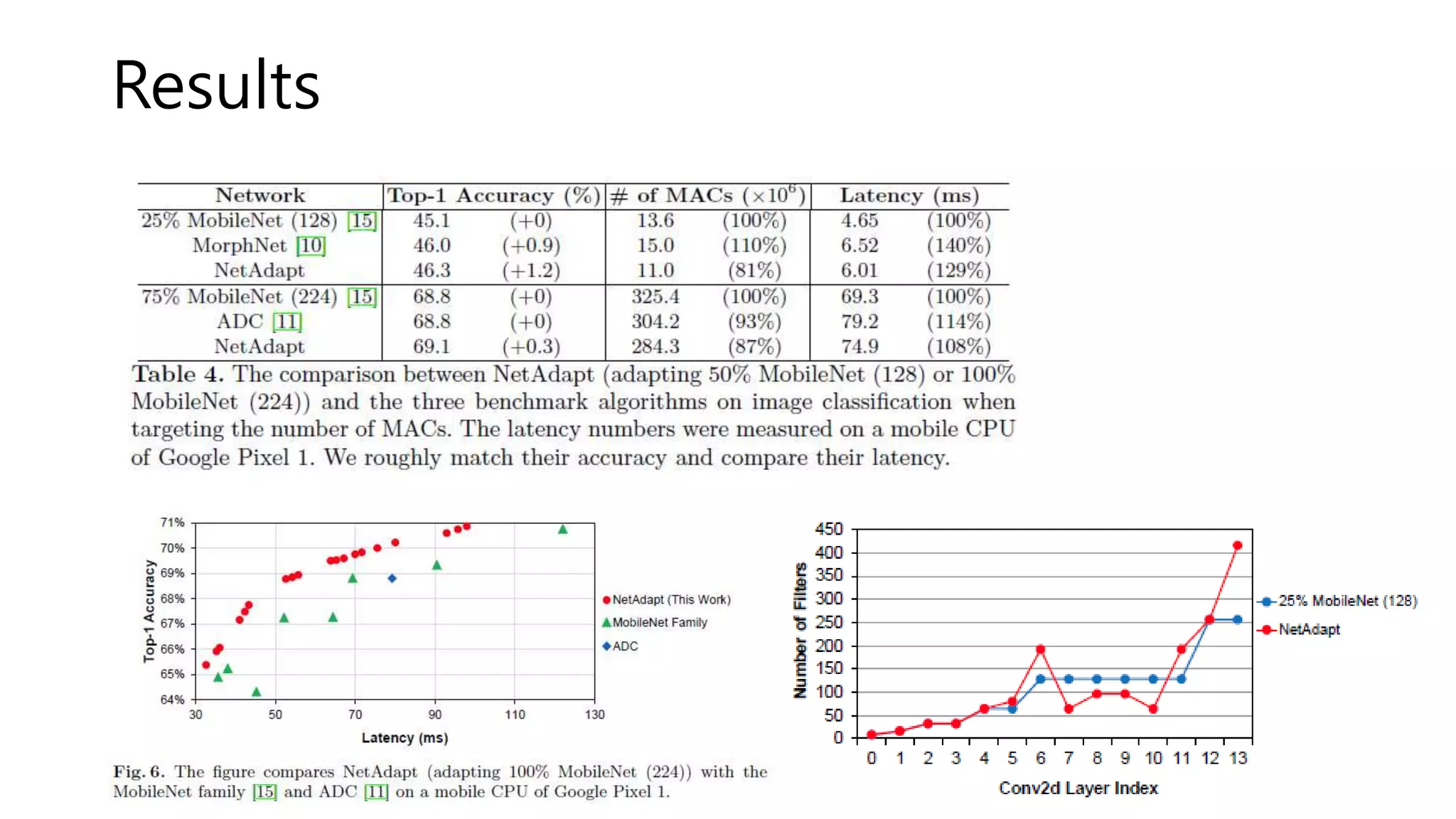

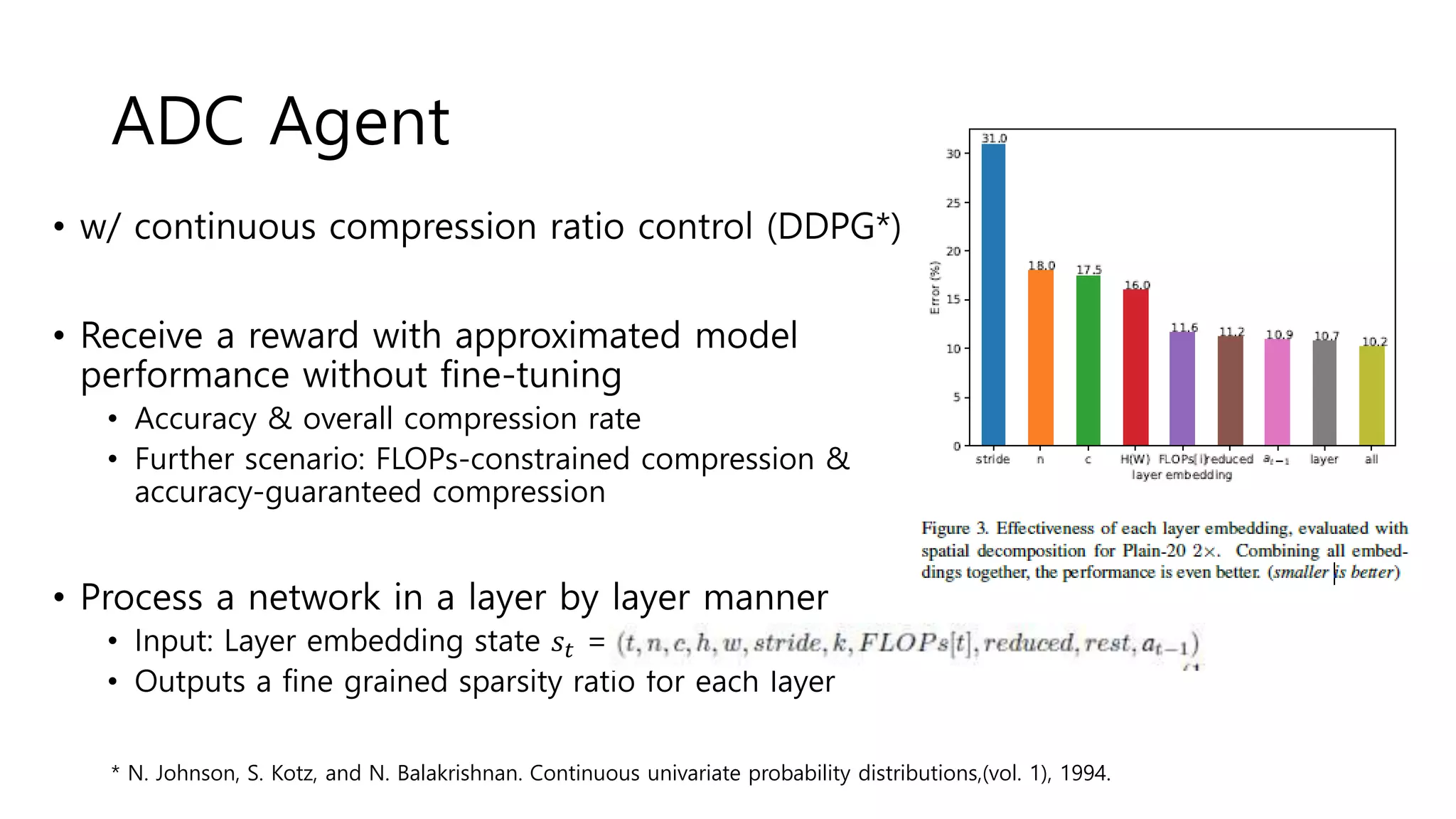
![Algorithm
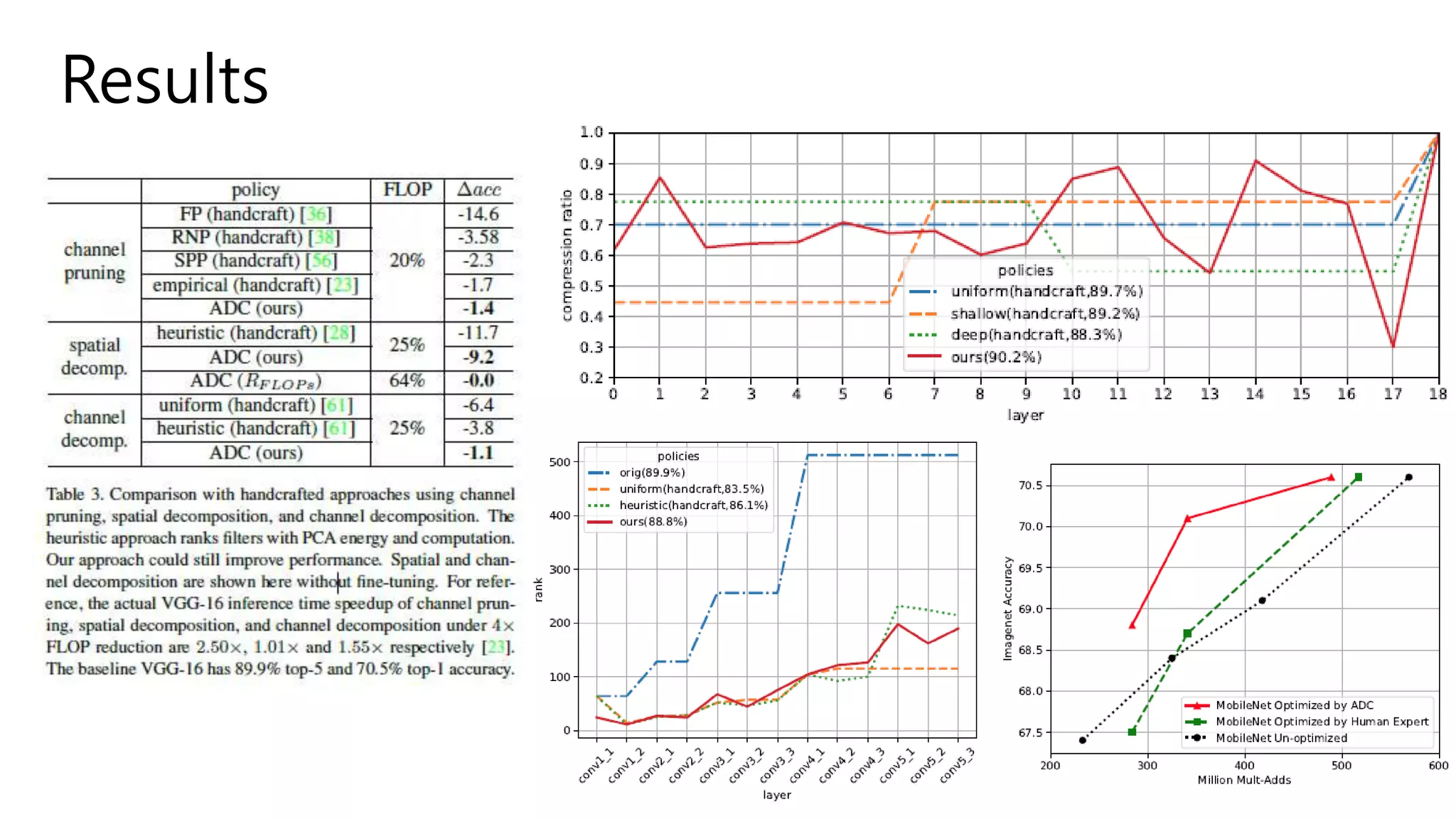
• Specified Compression algorithm (reducing channels to c’): n x c x k x k ?
• Spatial decomposition[1]: n x c’ x k x 1, c’ x c x 1 x k - Data independent reconstruction
• Channel decomposition[2]: n x c’ x k x k, c’ x c x 1 x 1
• Channel pruning[3]: n x c’ x k x k - L2-norm(magnitude) based pruning
• Agent
• Each transition in an episode is 𝑠𝑡, 𝑎 𝑡, 𝑅, 𝑠𝑡+1
• Action Error[4]에 비례한 Reward를 통해 Agent 학습
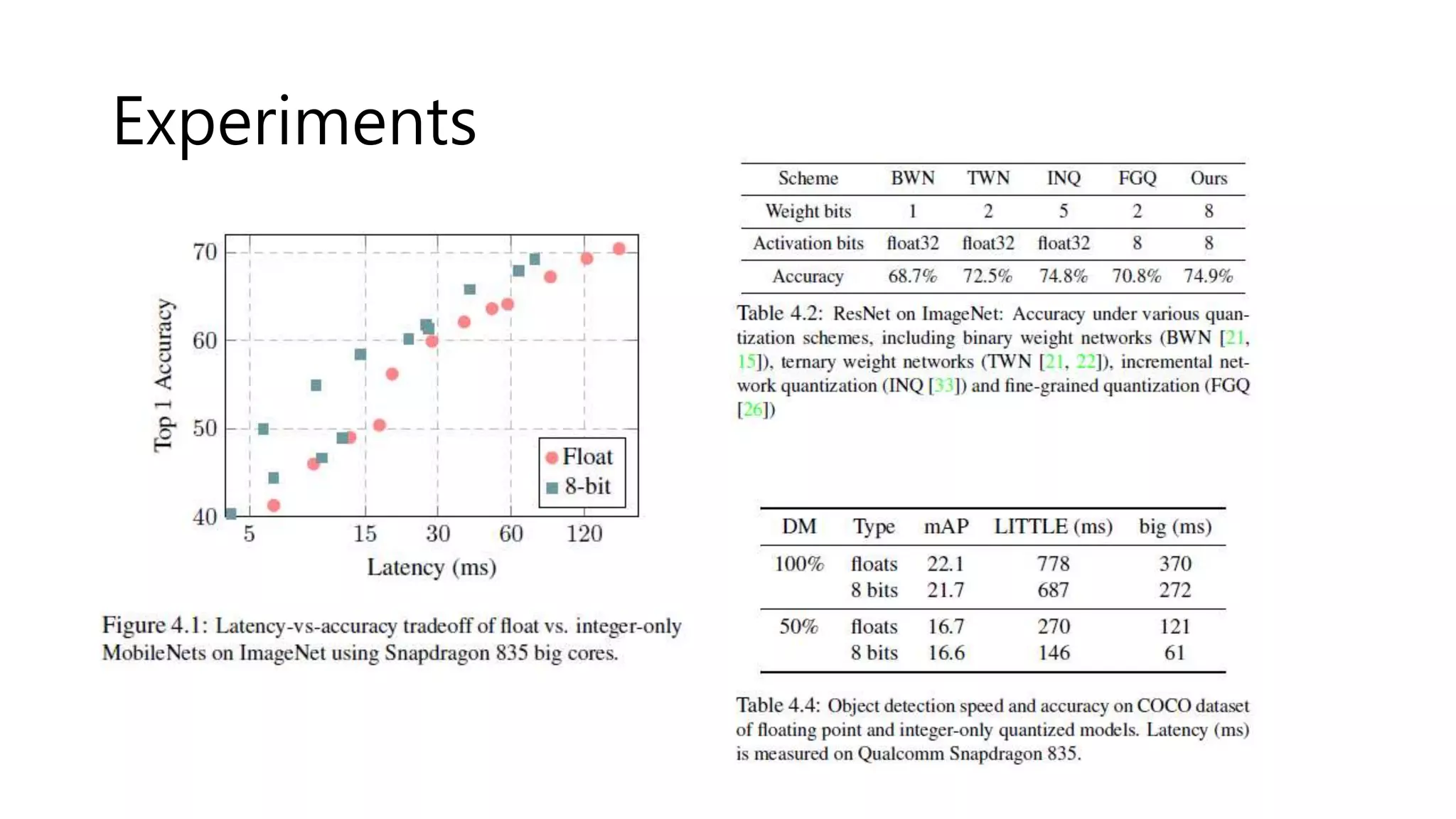
• FLOPs-Constrained Compression
• R = -Error
• 일단 1차로 네트워크 압축 후, 휴리스틱을 통해 점차 주어진 budget 아래로 압축되도록 만든다.
• Accuracy-Guaranteed Compression
• Observe that accuracy error is inversely-proportional to log(FLOPs)
• R = - Error * log(FLOPs)
[1] M. Jaderberg, A. Vedaldi, and A. Zisserman. Speeding up convolutional neural networks with low rank expansions. arXiv preprint arXiv:1405.3866, 2014
[2] X. Zhang, J. Zou, K. He, and J. Sun. Accelerating very deep convolutional networks for classification and detection. IEEE transactions on pattern analysis and
machine intelligence, 38(10):1943–1955, 2016.
[3] Y. He, X. Zhang, and J. Sun. Channel pruning for accelerating very deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern
Recognition, pages 1389–1397, 2017
[4]B. Baker, O. Gupta, N. Naik, and R. Raskar. Designing neural network architectures using reinforcement learning](https://image.slidesharecdn.com/cvpr2018papersreviewefficientcomputing-180907045500/75/Cvpr-2018-papers-review-efficient-computing-10-2048.jpg)















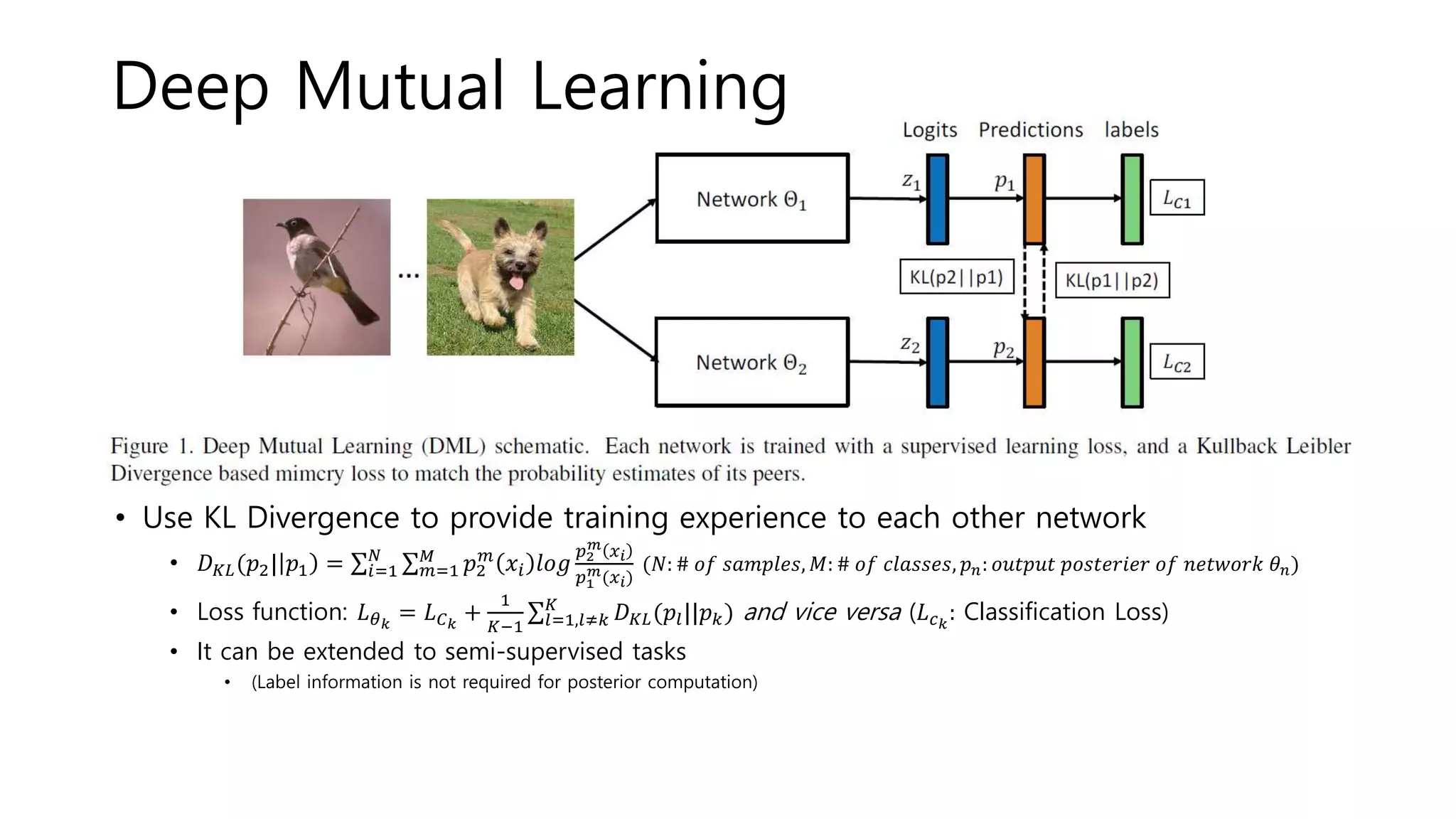
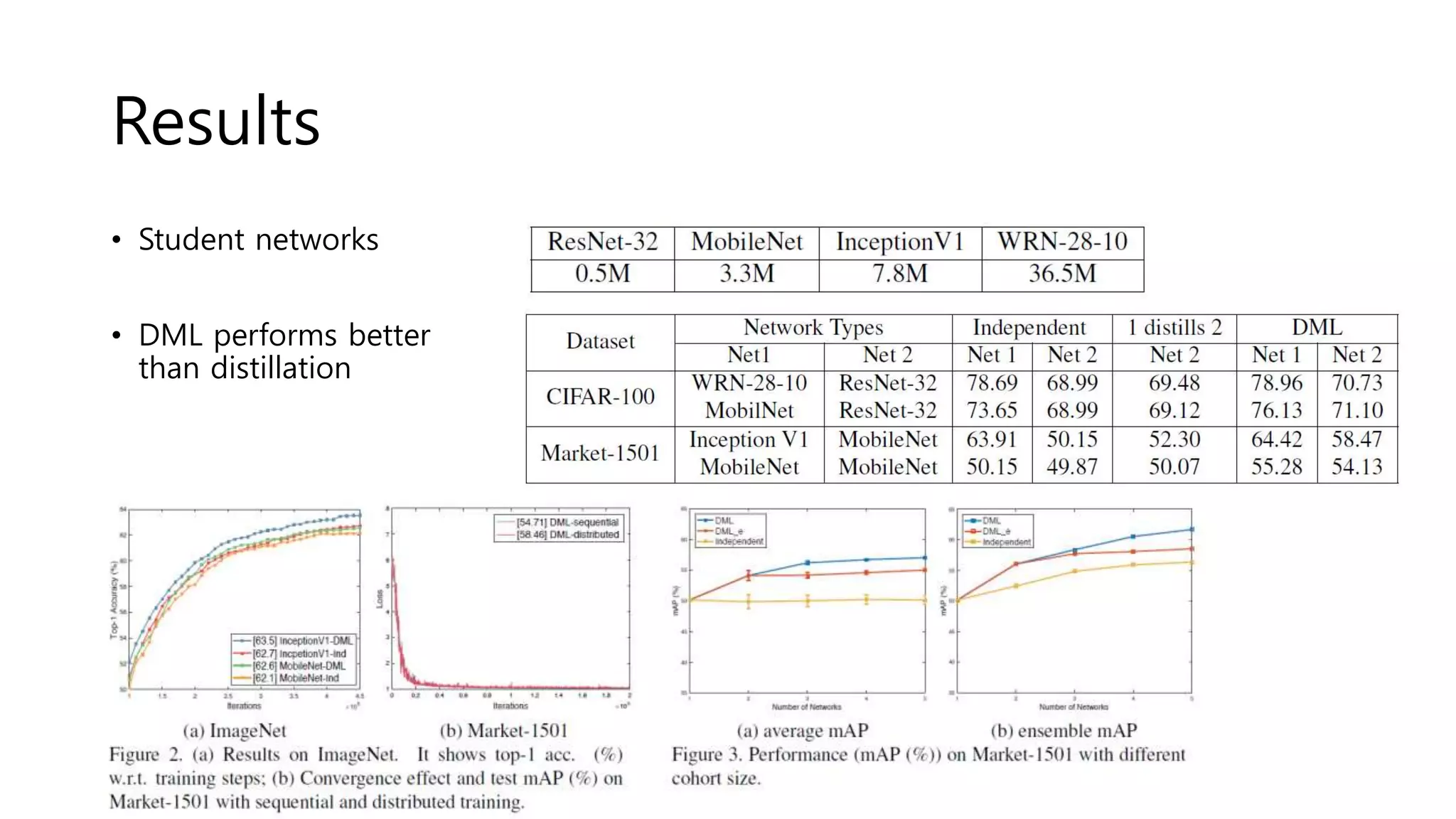
![Deep Mutual Learning
(Dalian University of Technology, China)
• Model distillation
• A powerful large network teaches a small network
• Deep Mutual learning
• An ensemble of students learn collaboratively & teach each other
• Collaborative learning
• Dual learning[1]: two cross-lingual translation models teach each other
• Cooperative Learning[2]: Recognizing the same set of object categories but with
different inputs (ex: RGB + depth)
• This work: different models, but the same input and task
• No priori powerful teacher network is necessary!
[1] D. He, Y. Xia, T. Qin, L. Wang, N. Yu, T. Liu, and W. Ma. Dual learning for machine translation. In NIPS, pages 820– 828, 2016.
[2] T. Batra and D. Parikh. Cooperative learning with visual attributes. arXiv: 1705.05512, 2017.](https://image.slidesharecdn.com/cvpr2018papersreviewefficientcomputing-180907045500/75/Cvpr-2018-papers-review-efficient-computing-48-2048.jpg)















![[PR12] Inception and Xception - Jaejun Yoo](https://cdn.slidesharecdn.com/ss_thumbnails/pr12inceptionandxception-jaejunyoo-170910140157-thumbnail.jpg?width=640&height=640&fit=bounds)





![[PR12] PR-050: Convolutional LSTM Network: A Machine Learning Approach for Pr...](https://cdn.slidesharecdn.com/ss_thumbnails/pr12-convlstm-171126135417-thumbnail.jpg?width=640&height=640&fit=bounds)




















































