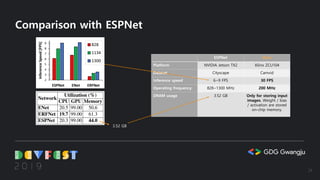
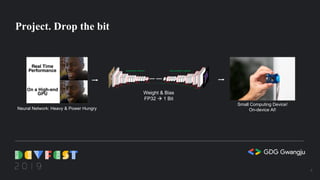
This document summarizes a presentation on 1-bit semantic segmentation. It discusses quantizing neural networks to 1-bit to enable on-device AI with small, low-power processors. It describes building and training binarized neural networks, comparing their performance to FP32 networks, and implementing a hardware architecture for real-time 1-bit semantic segmentation on an FPGA board. The results show the potential for low-cost, embedded semantic segmentation through neural network quantization and specialized hardware design.





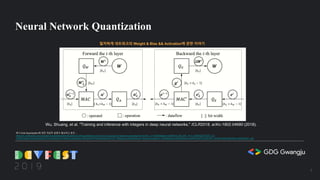


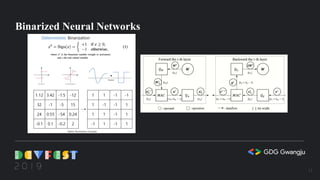



![class SignumActivation(torch.autograd.Function):
def forward(self, input):
self.save_for_backward(input)
size = input.size()
mean = torch.mean(input.abs(), 1, keepdim=True)
output = input.sign().add(0.01).sign()
return output, mean
def backward(self, grad_output, grad_output_mean): #STE Part
input, = self.saved_tensors
grad_input = grad_output.clone()
grad_input=(2/torch.cosh(input))*(2/torch.cosh(input))*(grad_input)
#grad_input[input.ge(1)] = 0
#great or equal #grad_input[input.le(-1)] = 0 #less or equal
return grad_input
Code Example (PyTorch)
Straight Through Estimator for Gradient Propagation
15](https://image.slidesharecdn.com/devfestgwangju20191-bitsemanticsegmentation-191119140937/85/1-bit-semantic-segmentation-15-320.jpg)