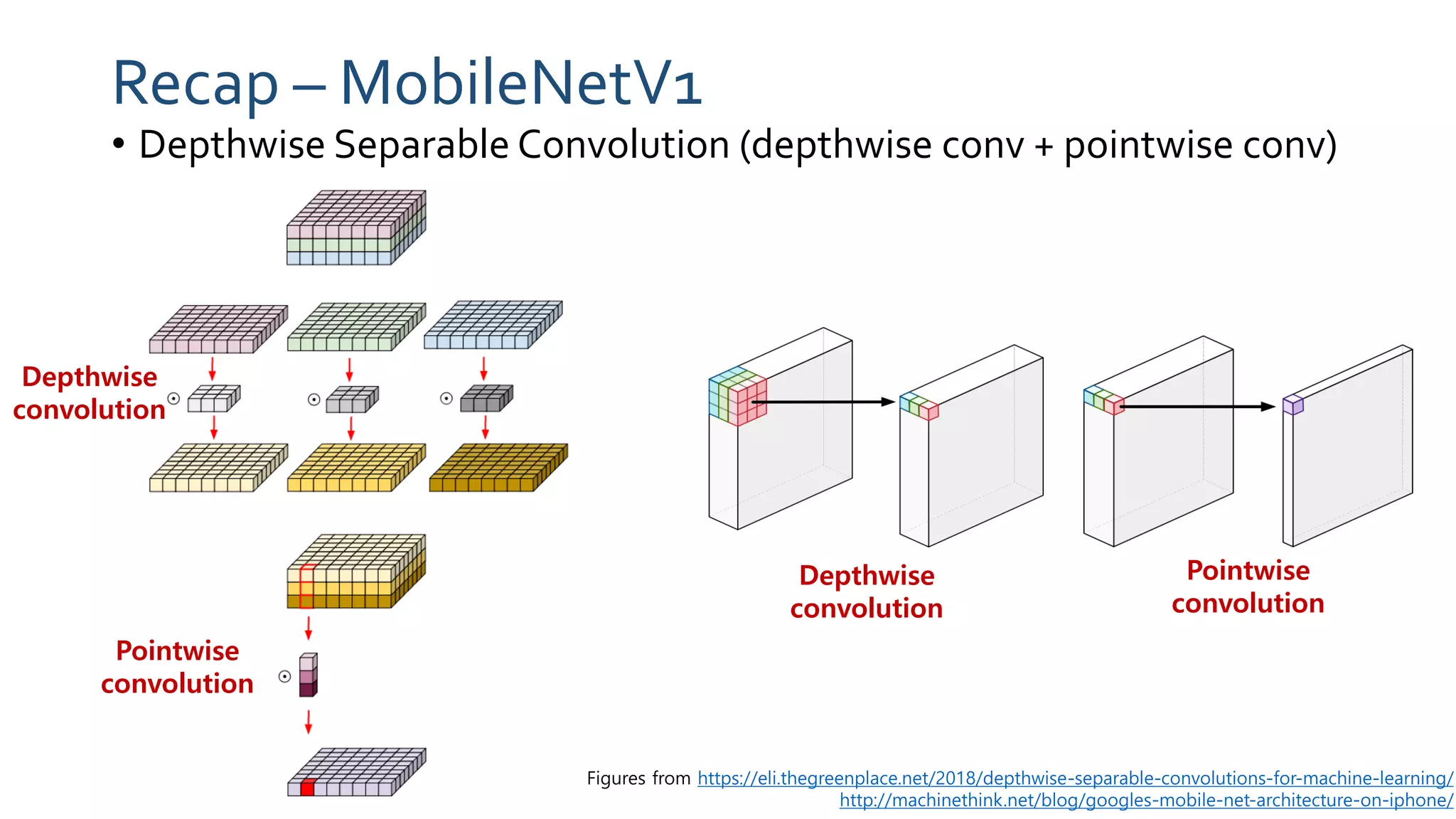
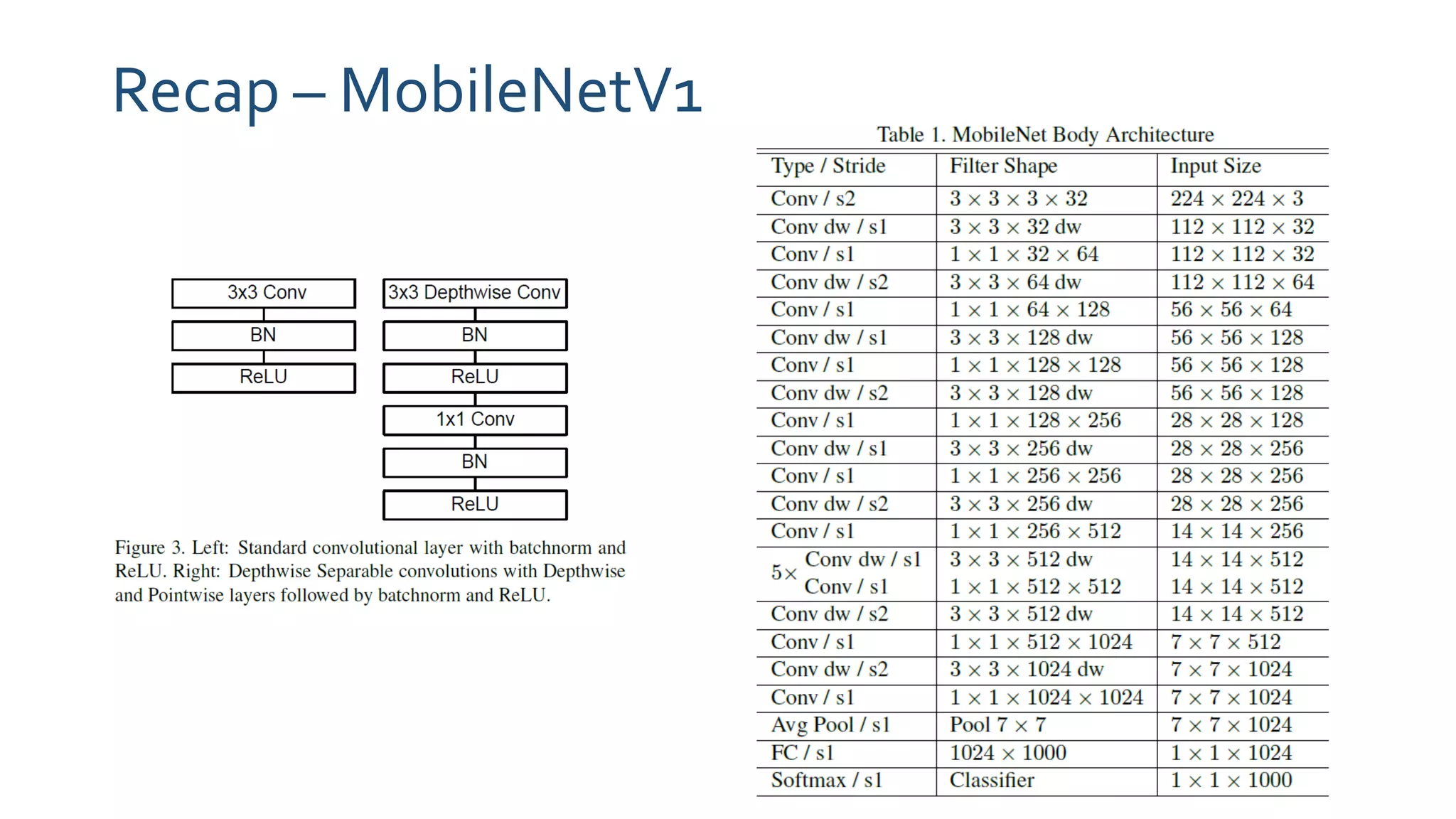
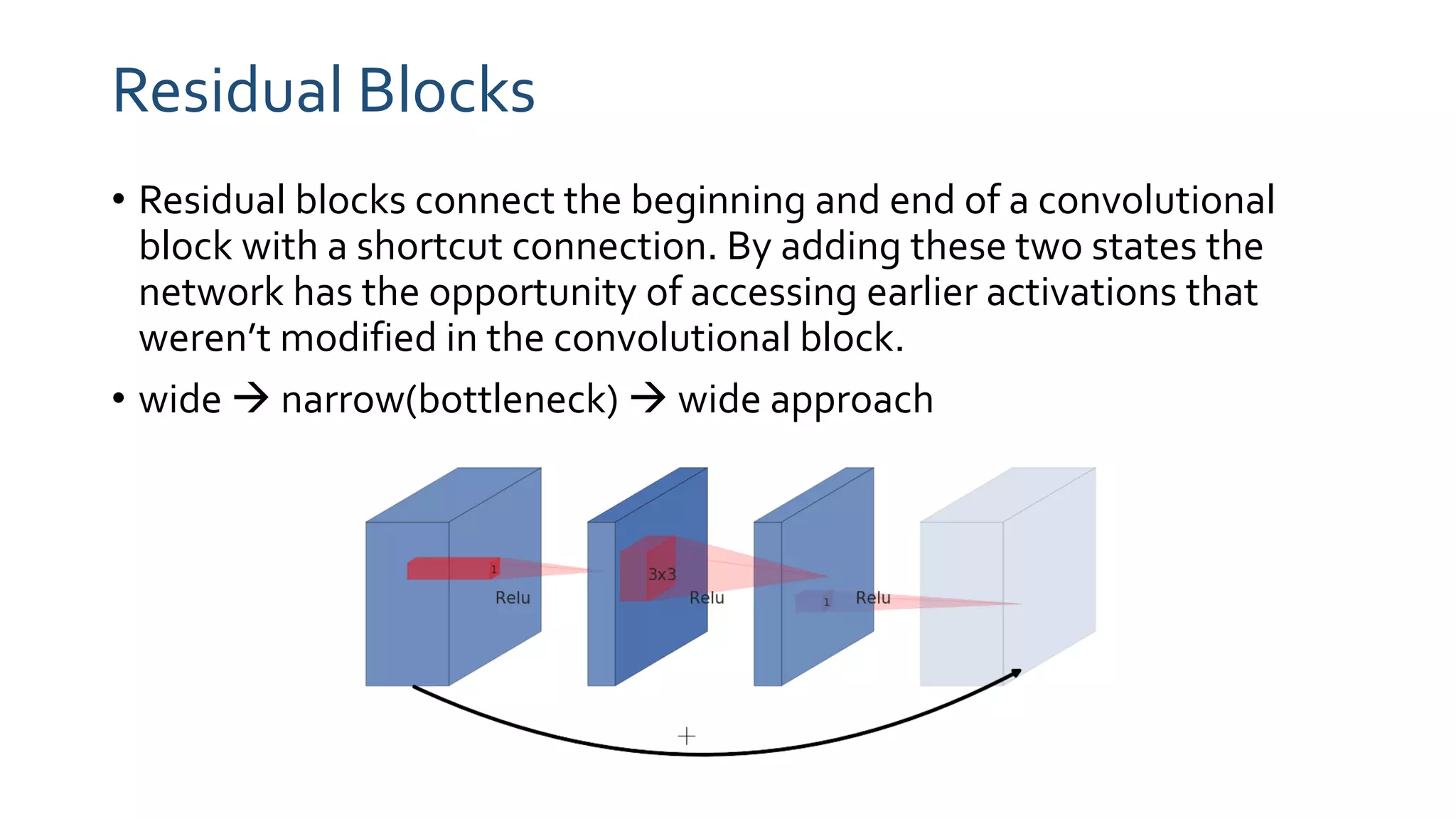
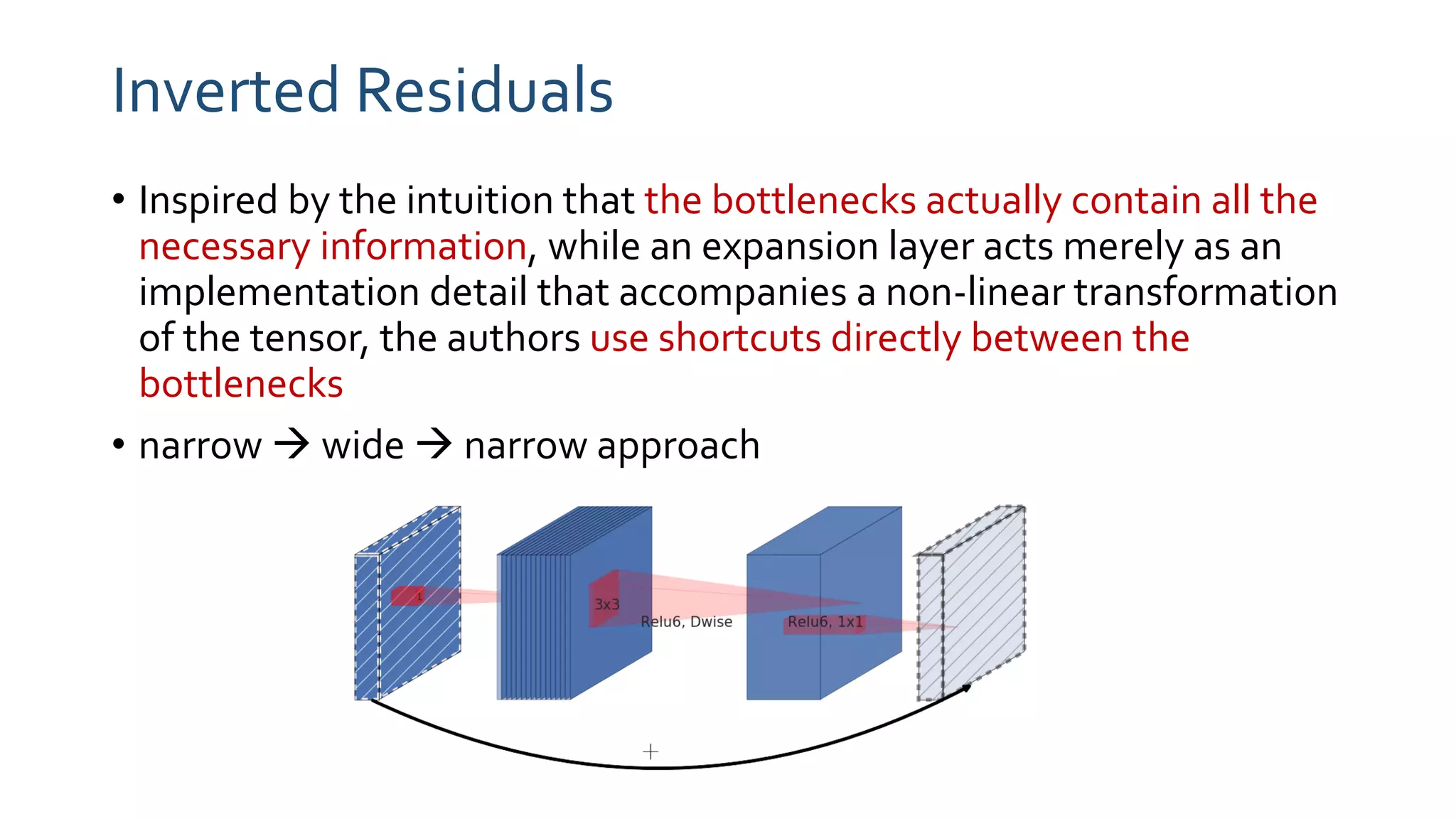
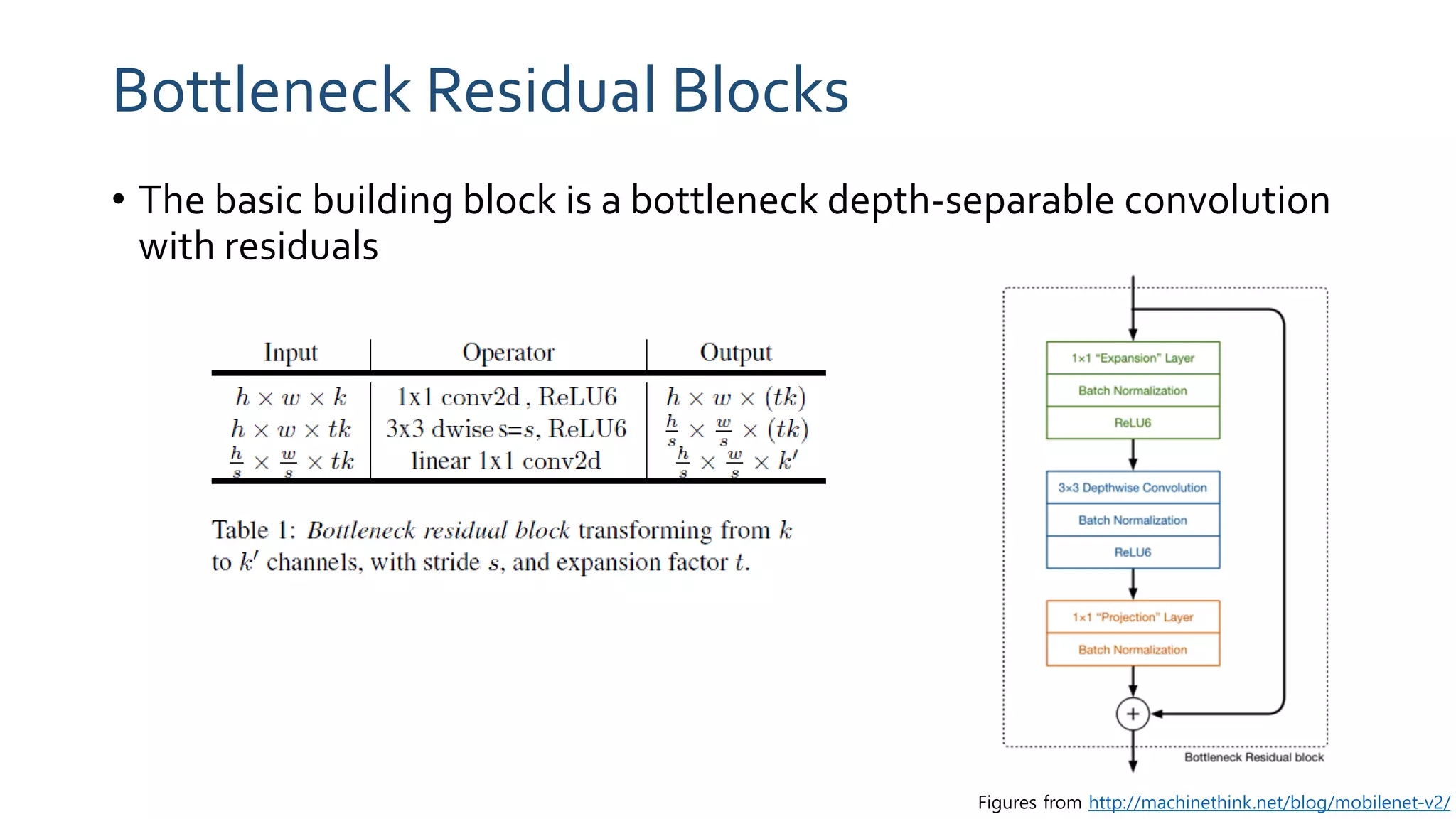
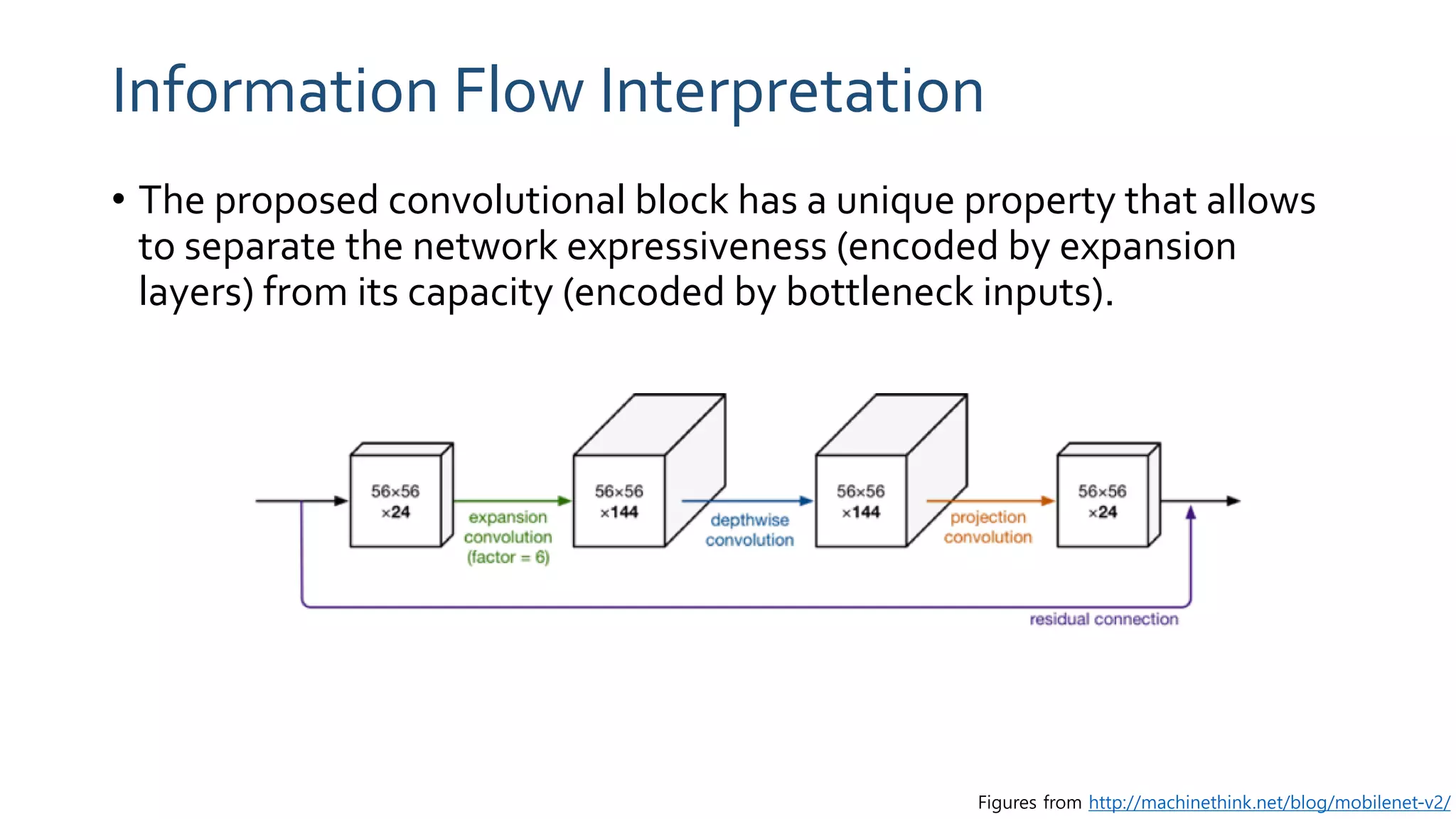
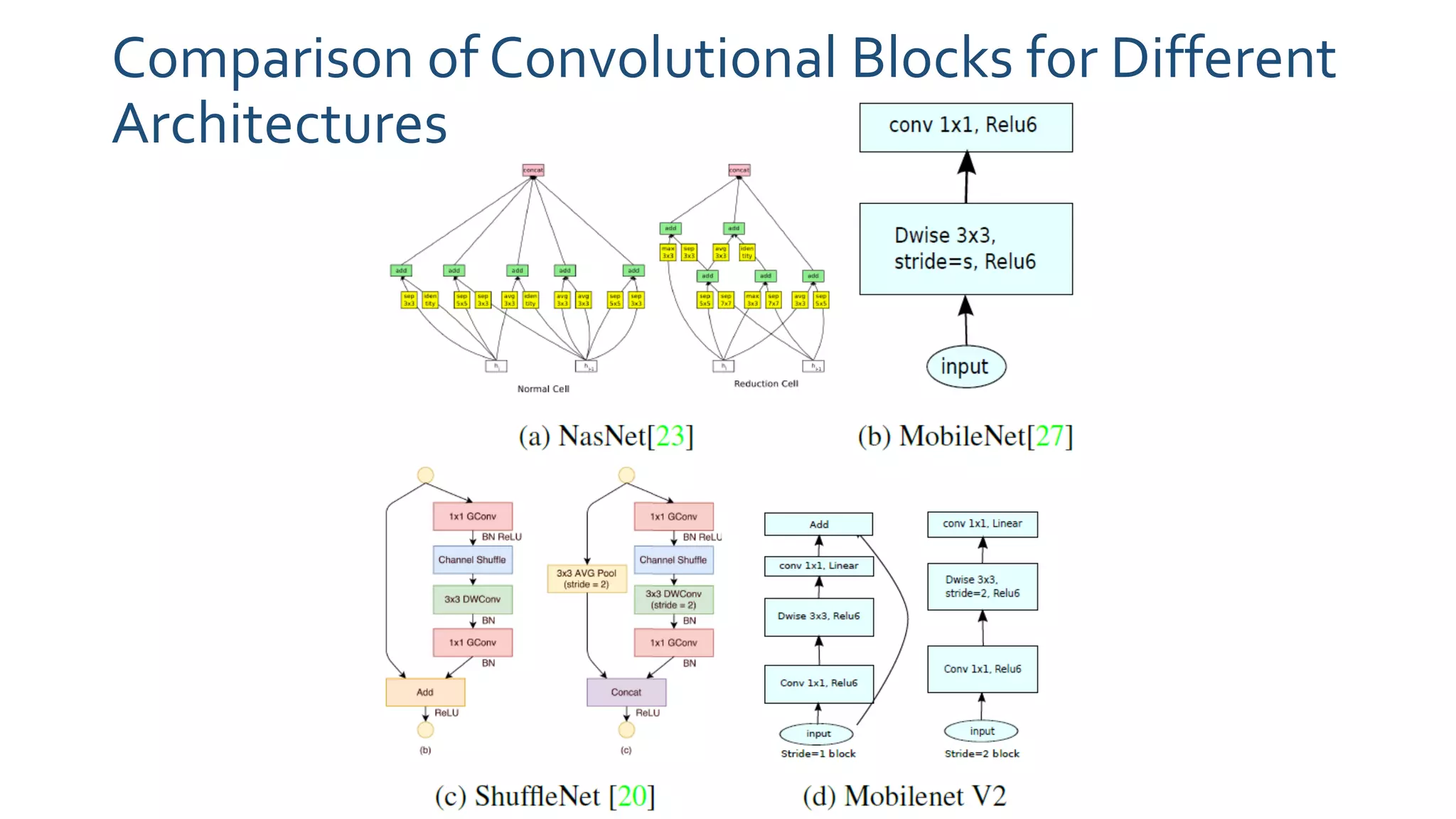
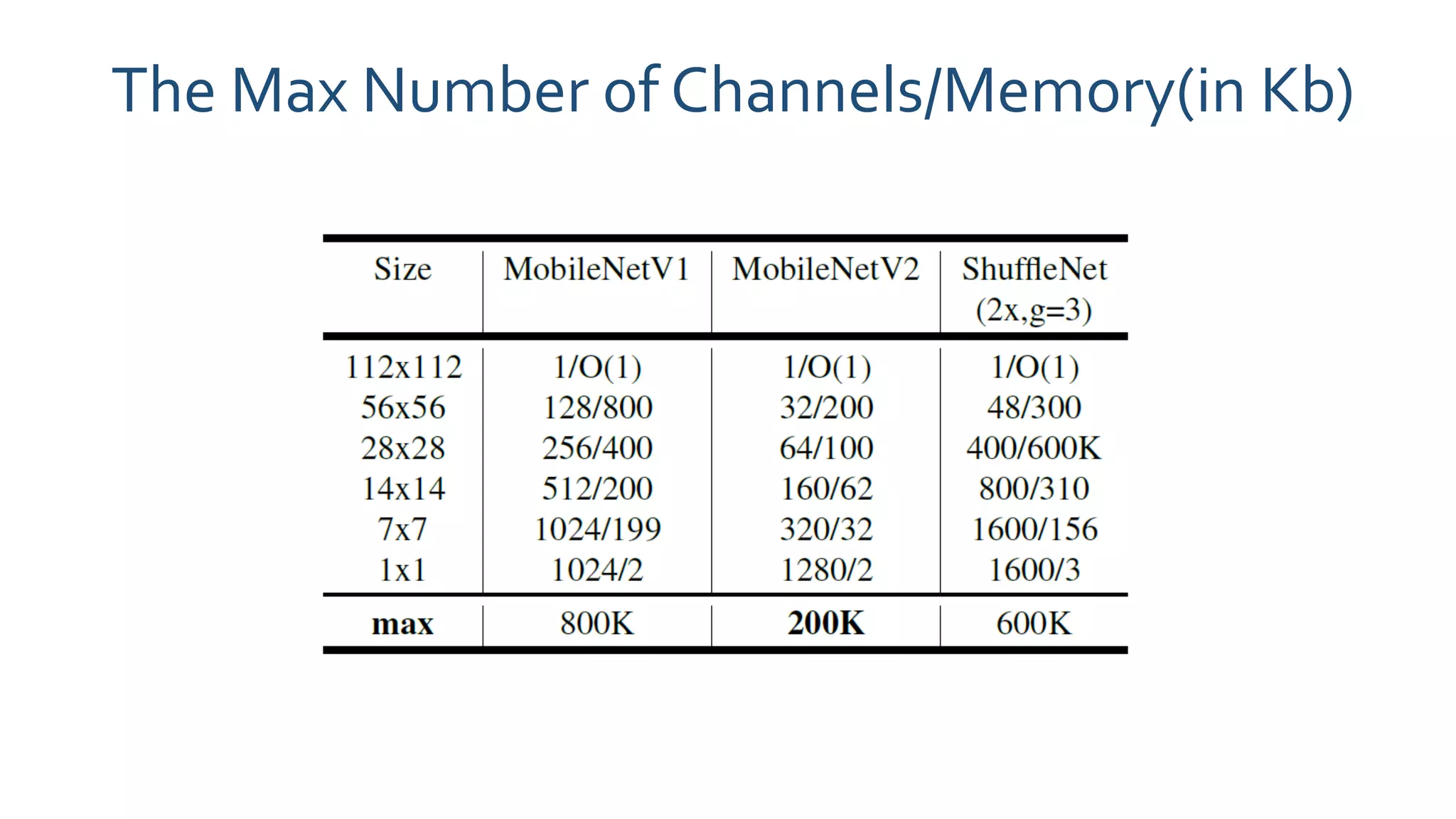
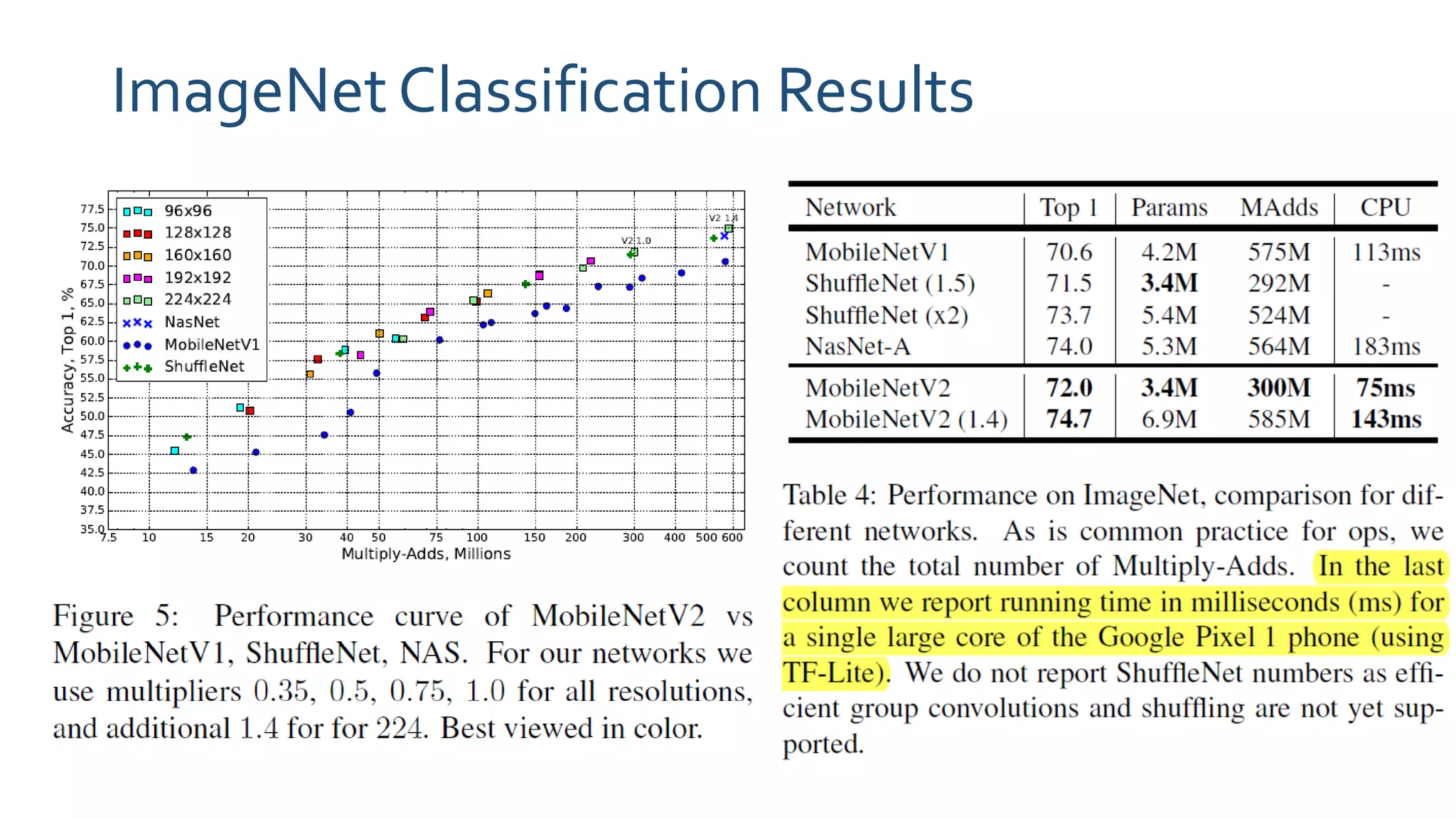
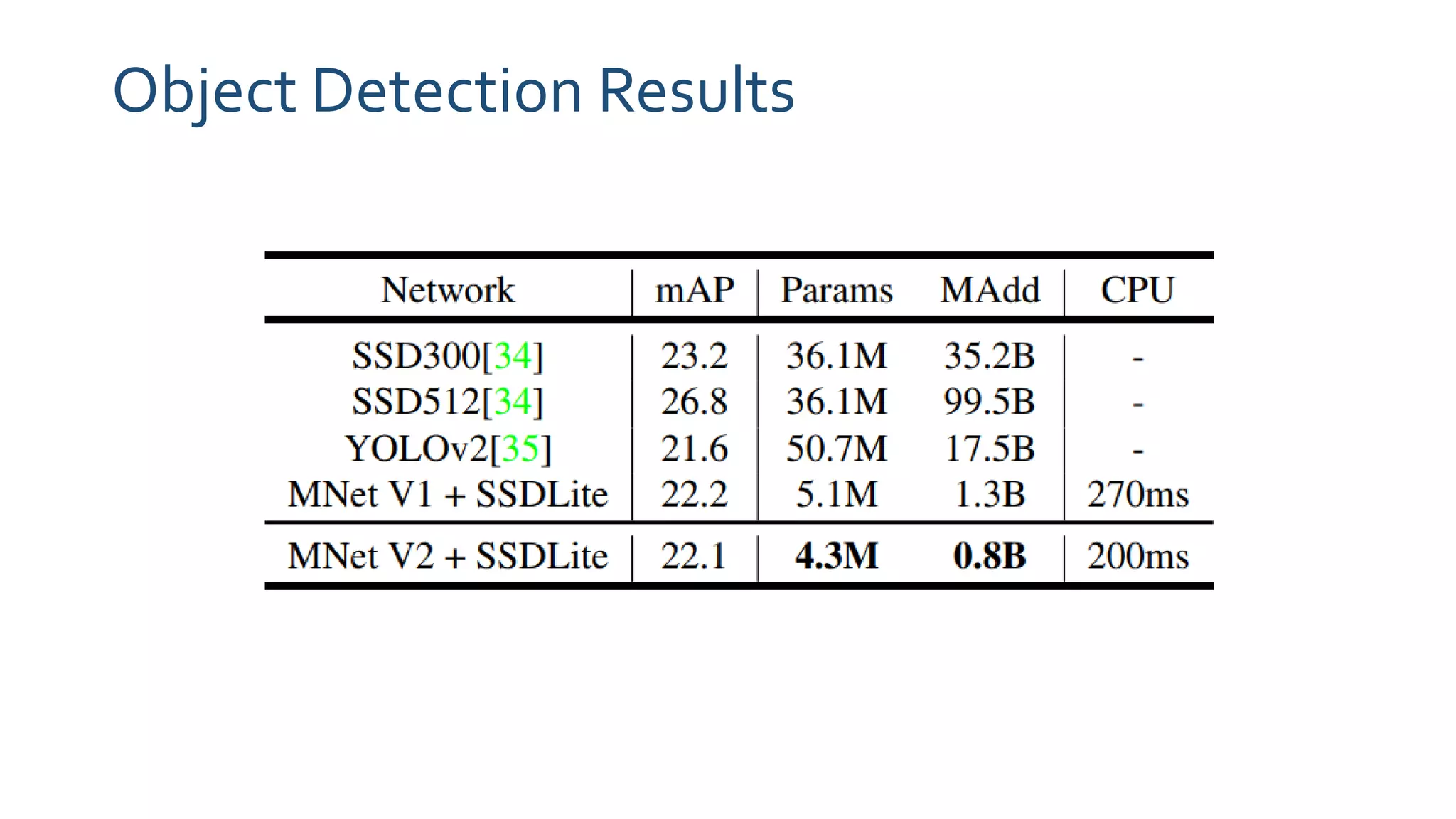
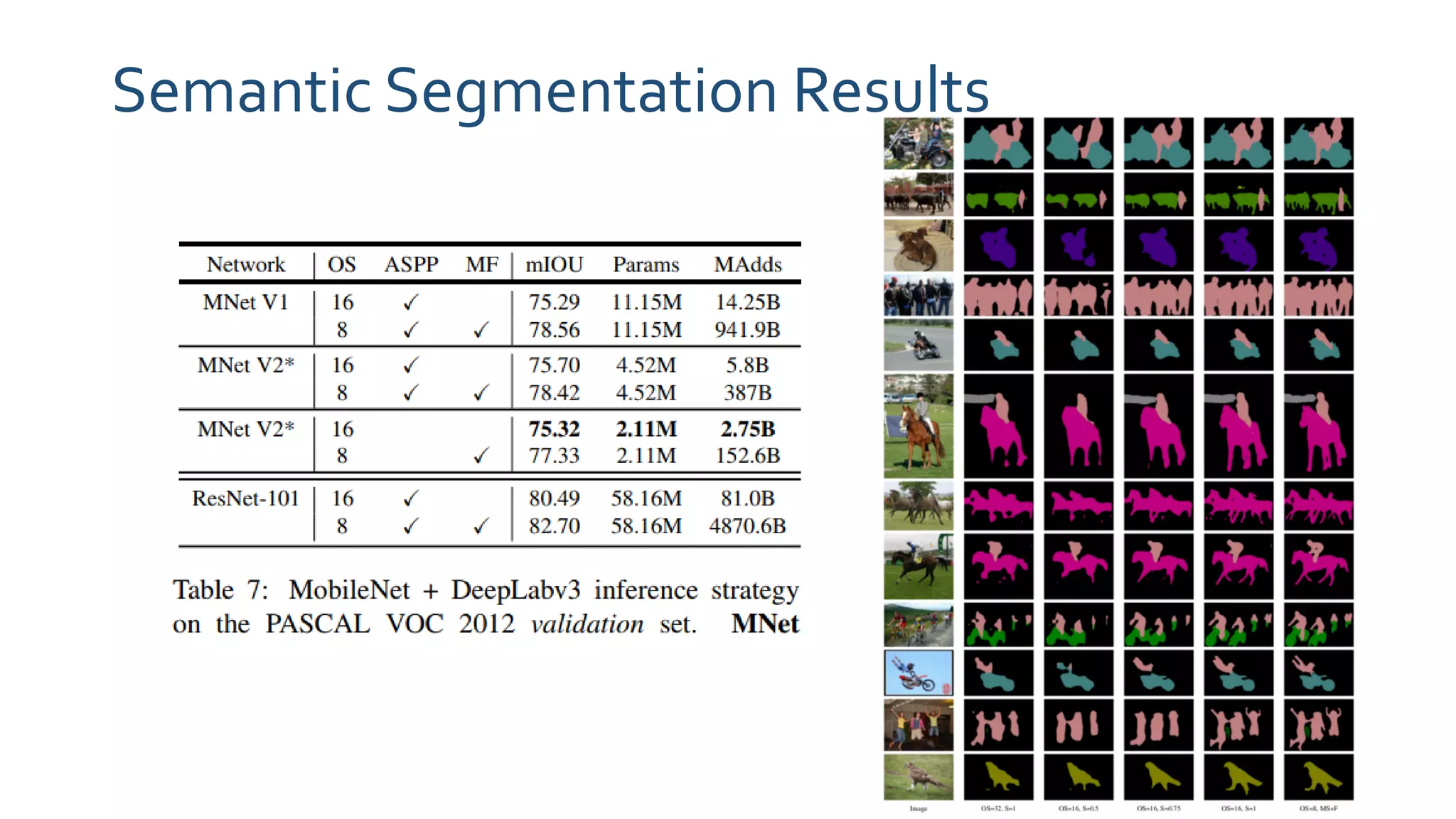
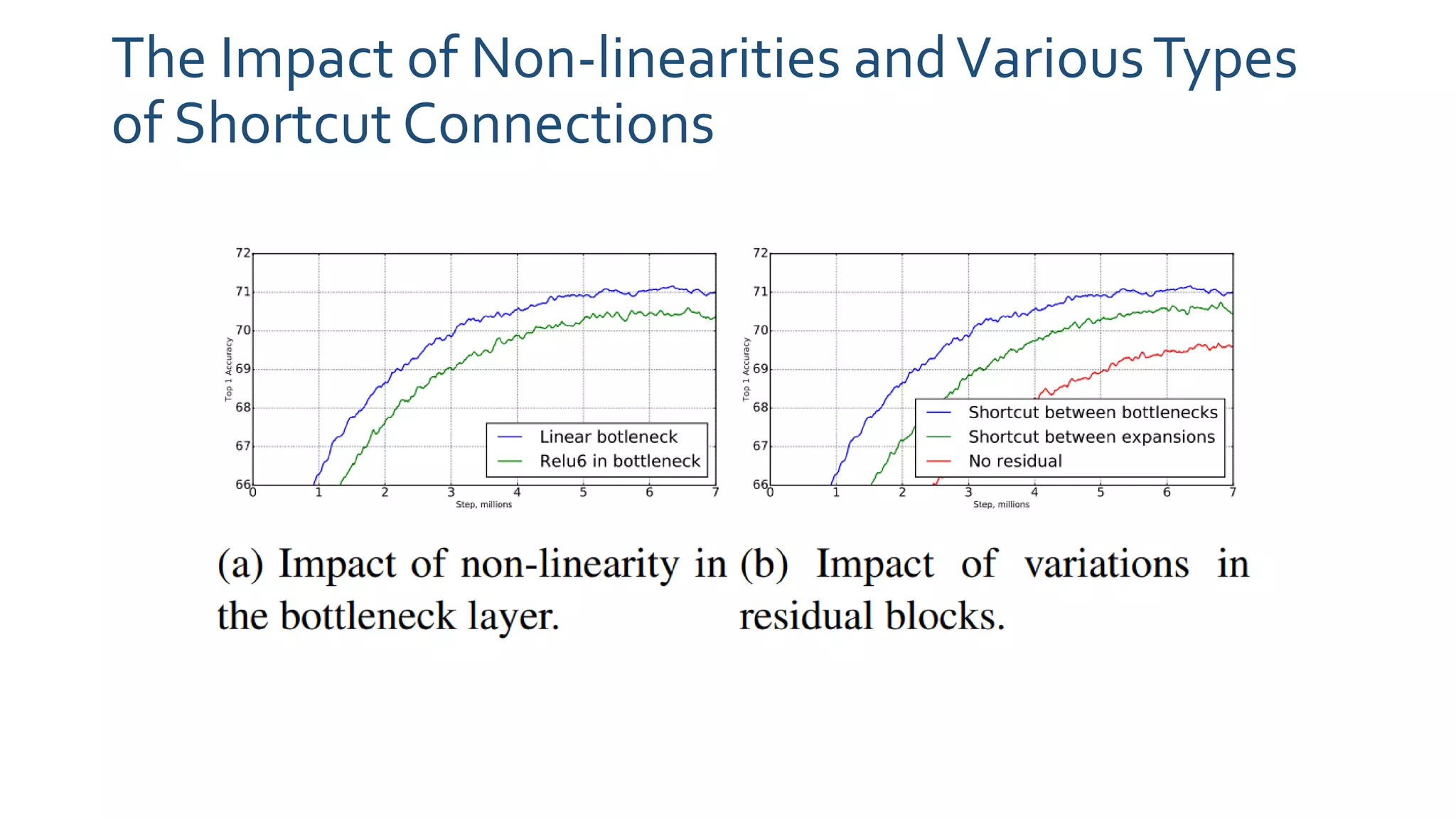
The paper 'MobileNetV2: Inverted Residuals and Linear Bottlenecks' discusses advancements in mobile neural networks, specifically emphasizing depthwise separable convolutions, linear bottlenecks, and inverted residuals to optimize computational efficiency. It introduces a novel architecture that maintains performance while significantly reducing computational costs, enhancing memory efficiency for mobile and embedded applications. The architecture includes 19 residual bottleneck layers following an initial fully convolutional layer, allowing for effective object detection and semantic segmentation.



























































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)










