Download free for 30 days
Sign in
Upload
Language (EN)
Support
Business
Mobile
Social Media
Marketing
Technology
Art & Photos
Career
Design
Education
Presentations & Public Speaking
Government & Nonprofit
Healthcare
Internet
Law
Leadership & Management
Automotive
Engineering
Software
Recruiting & HR
Retail
Sales
Services
Science
Small Business & Entrepreneurship
Food
Environment
Economy & Finance
Data & Analytics
Investor Relations
Sports
Spiritual
News & Politics
Travel
Self Improvement
Real Estate
Entertainment & Humor
Health & Medicine
Devices & Hardware
Lifestyle
Change Language
Language
English
Español
Português
Français
Deutsche
Cancel
Save
EN
Uploaded by
Katsuhiro Morishita
PDF, PPTX
2,811 views
シリーズML-07 ニューラルネットワークによる非線形回帰
機械学習シリーズスライドです。このスライドでは、ニューラルネットワークによる非線形回帰について説明しました。
Data & Analytics
◦
Read more
0
Save
Share
Embed
Embed presentation
Download
Download as PDF, PPTX
1
/ 28
2
/ 28
3
/ 28
4
/ 28
5
/ 28
6
/ 28
7
/ 28
8
/ 28
9
/ 28
10
/ 28
11
/ 28
12
/ 28
13
/ 28
14
/ 28
15
/ 28
16
/ 28
17
/ 28
18
/ 28
19
/ 28
20
/ 28
21
/ 28
22
/ 28
23
/ 28
24
/ 28
25
/ 28
26
/ 28
27
/ 28
28
/ 28
More Related Content
PDF
第39回日本基礎心理学会シンポジウム発表資料
by
Masanori Kobayashi
PPTX
SuperGlue; Learning Feature Matching with Graph Neural Networks (CVPR'20)
by
Yusuke Uchida
PPTX
5分でわかるベイズ確率
by
hoxo_m
PDF
深層学習による非滑らかな関数の推定
by
Masaaki Imaizumi
PPTX
ベイズ最適化によるハイパラーパラメータ探索
by
西岡 賢一郎
PDF
【DL輪読会】"Secrets of RLHF in Large Language Models Part I: PPO"
by
Deep Learning JP
PDF
最適輸送入門
by
joisino
PDF
渡辺澄夫著「ベイズ統計の理論と方法」5.1 マルコフ連鎖モンテカルロ法
by
Kenichi Hironaka
第39回日本基礎心理学会シンポジウム発表資料
by
Masanori Kobayashi
SuperGlue; Learning Feature Matching with Graph Neural Networks (CVPR'20)
by
Yusuke Uchida
5分でわかるベイズ確率
by
hoxo_m
深層学習による非滑らかな関数の推定
by
Masaaki Imaizumi
ベイズ最適化によるハイパラーパラメータ探索
by
西岡 賢一郎
【DL輪読会】"Secrets of RLHF in Large Language Models Part I: PPO"
by
Deep Learning JP
最適輸送入門
by
joisino
渡辺澄夫著「ベイズ統計の理論と方法」5.1 マルコフ連鎖モンテカルロ法
by
Kenichi Hironaka
What's hot
PPTX
You Only Look One-level Featureの解説と見せかけた物体検出のよもやま話
by
Yusuke Uchida
PDF
【基調講演】『深層学習の原理の理解に向けた理論の試み』 今泉 允聡(東大)
by
MLSE
PPTX
Curriculum Learning (関東CV勉強会)
by
Yoshitaka Ushiku
PPTX
ベイズ統計学の概論的紹介
by
Naoki Hayashi
PPTX
【LT資料】 Neural Network 素人なんだけど何とかご機嫌取りをしたい
by
Takuji Tahara
PDF
変分推論と Normalizing Flow
by
Akihiro Nitta
PDF
[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision
by
Deep Learning JP
PDF
統計的因果推論勉強会 第1回
by
Hikaru GOTO
PDF
[DL輪読会]近年のエネルギーベースモデルの進展
by
Deep Learning JP
PPTX
[DL輪読会]GQNと関連研究,世界モデルとの関係について
by
Deep Learning JP
PDF
Disentanglement Survey:Can You Explain How Much Are Generative models Disenta...
by
Hideki Tsunashima
PDF
強化学習と逆強化学習を組み合わせた模倣学習
by
Eiji Uchibe
PDF
「ランダムフォレスト回帰」のハイパーパラメーター
by
Jun Umezawa
PPTX
[DL輪読会]MetaFormer is Actually What You Need for Vision
by
Deep Learning JP
PDF
[DL輪読会]A Bayesian Perspective on Generalization and Stochastic Gradient Descent
by
Deep Learning JP
PDF
グラフデータ分析 入門編
by
順也 山口
PDF
【DL輪読会】How Much Can CLIP Benefit Vision-and-Language Tasks?
by
Deep Learning JP
PDF
深層学習入門
by
Danushka Bollegala
PPTX
【DL輪読会】Hopfield network 関連研究について
by
Deep Learning JP
PPTX
Sliced Wasserstein距離と生成モデル
by
ohken
You Only Look One-level Featureの解説と見せかけた物体検出のよもやま話
by
Yusuke Uchida
【基調講演】『深層学習の原理の理解に向けた理論の試み』 今泉 允聡(東大)
by
MLSE
Curriculum Learning (関東CV勉強会)
by
Yoshitaka Ushiku
ベイズ統計学の概論的紹介
by
Naoki Hayashi
【LT資料】 Neural Network 素人なんだけど何とかご機嫌取りをしたい
by
Takuji Tahara
変分推論と Normalizing Flow
by
Akihiro Nitta
[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision
by
Deep Learning JP
統計的因果推論勉強会 第1回
by
Hikaru GOTO
[DL輪読会]近年のエネルギーベースモデルの進展
by
Deep Learning JP
[DL輪読会]GQNと関連研究,世界モデルとの関係について
by
Deep Learning JP
Disentanglement Survey:Can You Explain How Much Are Generative models Disenta...
by
Hideki Tsunashima
強化学習と逆強化学習を組み合わせた模倣学習
by
Eiji Uchibe
「ランダムフォレスト回帰」のハイパーパラメーター
by
Jun Umezawa
[DL輪読会]MetaFormer is Actually What You Need for Vision
by
Deep Learning JP
[DL輪読会]A Bayesian Perspective on Generalization and Stochastic Gradient Descent
by
Deep Learning JP
グラフデータ分析 入門編
by
順也 山口
【DL輪読会】How Much Can CLIP Benefit Vision-and-Language Tasks?
by
Deep Learning JP
深層学習入門
by
Danushka Bollegala
【DL輪読会】Hopfield network 関連研究について
by
Deep Learning JP
Sliced Wasserstein距離と生成モデル
by
ohken
Similar to シリーズML-07 ニューラルネットワークによる非線形回帰
PDF
東京都市大学 データ解析入門 10 ニューラルネットワークと深層学習 1
by
hirokazutanaka
DOCX
深層学習 Day1レポート
by
taishimotoda
PDF
PRML5
by
Hidekazu Oiwa
PPTX
PRML Chapter 5
by
Masahito Ohue
PDF
PRML_from5.1to5.3.1
by
禎晃 山崎
PPTX
Back propagation
by
T2C_
PDF
ディープラーニング入門 ~ 画像処理・自然言語処理について ~
by
Kensuke Otsuki
PDF
[DL輪読会]Scalable Training of Inference Networks for Gaussian-Process Models
by
Deep Learning JP
PDF
TensorflowとKerasによる深層学習のプログラム実装実践講座
by
Ruo Ando
PDF
[DL Hacks] Deterministic Variational Inference for RobustBayesian Neural Netw...
by
Deep Learning JP
PPTX
W8PRML5.1-5.3
by
Masahito Ohue
PDF
PRML復々習レーン#9 前回までのあらすじ
by
sleepy_yoshi
PPTX
深層学習の数理
by
Taiji Suzuki
PPTX
ラビットチャレンジレポート 深層学習 Day1
by
ssuserf4860b
PPTX
深層学習の数理:カーネル法, スパース推定との接点
by
Taiji Suzuki
PDF
深層学習(岡本孝之 著)Deep learning chap.4_1
by
Masayoshi Kondo
PPTX
深層学習入門 スライド
by
swamp Sawa
PPTX
深層学習とTensorFlow入門
by
tak9029
PPT
Deep Learningの技術と未来
by
Seiya Tokui
PDF
"Playing Atari with Deep Reinforcement Learning"
by
mooopan
東京都市大学 データ解析入門 10 ニューラルネットワークと深層学習 1
by
hirokazutanaka
深層学習 Day1レポート
by
taishimotoda
PRML5
by
Hidekazu Oiwa
PRML Chapter 5
by
Masahito Ohue
PRML_from5.1to5.3.1
by
禎晃 山崎
Back propagation
by
T2C_
ディープラーニング入門 ~ 画像処理・自然言語処理について ~
by
Kensuke Otsuki
[DL輪読会]Scalable Training of Inference Networks for Gaussian-Process Models
by
Deep Learning JP
TensorflowとKerasによる深層学習のプログラム実装実践講座
by
Ruo Ando
[DL Hacks] Deterministic Variational Inference for RobustBayesian Neural Netw...
by
Deep Learning JP
W8PRML5.1-5.3
by
Masahito Ohue
PRML復々習レーン#9 前回までのあらすじ
by
sleepy_yoshi
深層学習の数理
by
Taiji Suzuki
ラビットチャレンジレポート 深層学習 Day1
by
ssuserf4860b
深層学習の数理:カーネル法, スパース推定との接点
by
Taiji Suzuki
深層学習(岡本孝之 著)Deep learning chap.4_1
by
Masayoshi Kondo
深層学習入門 スライド
by
swamp Sawa
深層学習とTensorFlow入門
by
tak9029
Deep Learningの技術と未来
by
Seiya Tokui
"Playing Atari with Deep Reinforcement Learning"
by
mooopan
More from Katsuhiro Morishita
PDF
数ページの卒業論文作成のためのwordの使い方
by
Katsuhiro Morishita
PDF
Pythonのパッケージ管理ツールの話@2020
by
Katsuhiro Morishita
PDF
オトナのpandas勉強会(資料)
by
Katsuhiro Morishita
PDF
SIgfox触ってみた in IoTLT in 熊本市 vol.3
by
Katsuhiro Morishita
PDF
Google Colaboratoryの使い方
by
Katsuhiro Morishita
PDF
Excelでのグラフの作成方法re
by
Katsuhiro Morishita
PDF
Pythonのmain関数
by
Katsuhiro Morishita
PDF
Pythonスクリプトの実行方法@2018
by
Katsuhiro Morishita
PDF
機械学習と主成分分析
by
Katsuhiro Morishita
PDF
Pythonで始めた数値計算の授業@わんくま勉強会2018-04
by
Katsuhiro Morishita
PDF
マークシート読み込みプログラムを作ってみた@2018-04-04
by
Katsuhiro Morishita
PDF
オトナの画像認識 2018年3月21日実施
by
Katsuhiro Morishita
PDF
LoRa-WANで河川水位を計測してみた@IoTLT@熊本市 vol.001
by
Katsuhiro Morishita
PDF
シリーズML-08 ニューラルネットワークを用いた識別・分類ーシングルラベルー
by
Katsuhiro Morishita
PDF
シリーズML-06 ニューラルネットワークによる線形回帰
by
Katsuhiro Morishita
PDF
シリーズML-05 ニューラルネットワーク
by
Katsuhiro Morishita
PDF
シリーズML-03 ランダムフォレストによる自動識別
by
Katsuhiro Morishita
PDF
シリーズML-01 機械学習の概要
by
Katsuhiro Morishita
PDF
Pandas利用上のエラーとその対策
by
Katsuhiro Morishita
PDF
Pythonによる、デジタル通信のための ビタビ符号化・復号ライブラリの作成
by
Katsuhiro Morishita
数ページの卒業論文作成のためのwordの使い方
by
Katsuhiro Morishita
Pythonのパッケージ管理ツールの話@2020
by
Katsuhiro Morishita
オトナのpandas勉強会(資料)
by
Katsuhiro Morishita
SIgfox触ってみた in IoTLT in 熊本市 vol.3
by
Katsuhiro Morishita
Google Colaboratoryの使い方
by
Katsuhiro Morishita
Excelでのグラフの作成方法re
by
Katsuhiro Morishita
Pythonのmain関数
by
Katsuhiro Morishita
Pythonスクリプトの実行方法@2018
by
Katsuhiro Morishita
機械学習と主成分分析
by
Katsuhiro Morishita
Pythonで始めた数値計算の授業@わんくま勉強会2018-04
by
Katsuhiro Morishita
マークシート読み込みプログラムを作ってみた@2018-04-04
by
Katsuhiro Morishita
オトナの画像認識 2018年3月21日実施
by
Katsuhiro Morishita
LoRa-WANで河川水位を計測してみた@IoTLT@熊本市 vol.001
by
Katsuhiro Morishita
シリーズML-08 ニューラルネットワークを用いた識別・分類ーシングルラベルー
by
Katsuhiro Morishita
シリーズML-06 ニューラルネットワークによる線形回帰
by
Katsuhiro Morishita
シリーズML-05 ニューラルネットワーク
by
Katsuhiro Morishita
シリーズML-03 ランダムフォレストによる自動識別
by
Katsuhiro Morishita
シリーズML-01 機械学習の概要
by
Katsuhiro Morishita
Pandas利用上のエラーとその対策
by
Katsuhiro Morishita
Pythonによる、デジタル通信のための ビタビ符号化・復号ライブラリの作成
by
Katsuhiro Morishita
シリーズML-07 ニューラルネットワークによる非線形回帰
1.
Ver. 1.0, 2017-08-11 森下功啓 1
2.
2 線形回帰では、式(1)を用いて変数を予測する。 𝑦 = 𝛽0
+ 𝛽1 𝑥1 + 𝛽2 𝑥2 + ⋯ + 𝛽 𝑛 𝑥 𝑛 (1) しかしながら、1次式だけで予測できるものは少ない。 sin関数すら予測できない。 そこで、ニューラルネットワークを用いて非線形な回帰問題に 対応する方法をこのスライドでは解説しよう。
3.
対応ポイント • 非線形活性化関数を用いることが肝 • 一次関数はいくら足しても一次関数 •
故に、活性化関数は非線形である必要がある • ∴非線形活性化関数を持つ中間層が必要 • 中間層のユニット数と中間層数は、結果を見ながら調整 • 少ないと近似精度が悪い • 多すぎると過学習を起こしやすい 3
4.
サンプルプログラムのダウンロード 4 1 2 Download: https://github.com/KatsuhiroMorishita/machine_leaning_samples
5.
sin関数の近似 5
6.
6 • 以降のスライドでは、下記のプログラムを使った解説を行います • sin関数を学習するサンプルです
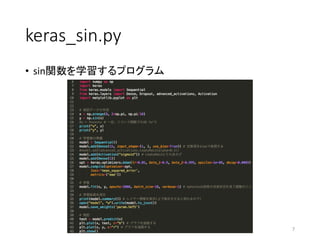
7.
keras_sin.py • sin関数を学習するプログラム 7
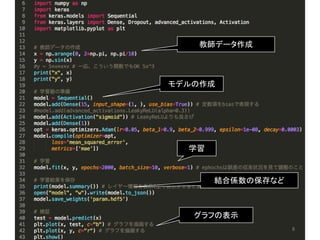
8.
8 モデルの作成 教師データ作成 学習 結合係数の保存など グラフの表示
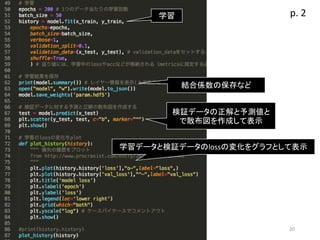
9.
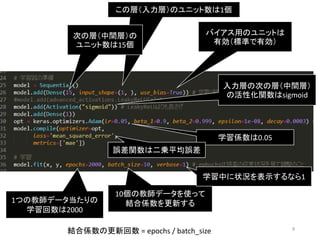
9 入力層の次の層(中間層) の活性化関数はsigmoid この層(入力層)のユニット数は1個 学習係数は0.05 1つの教師データ当たりの 学習回数は2000 10個の教師データを使って 結合係数を更新する 次の層(中間層)の ユニット数は15個 バイアス用のユニットは 有効(標準で有効) 誤差関数は二乗平均誤差 学習中に状況を表示するなら1 結合係数の更新回数 = epochs
/ batch_size
10.
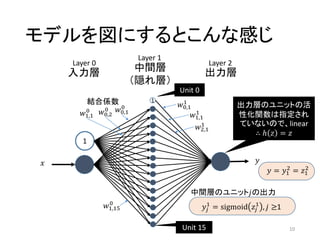
モデルを図にするとこんな感じ 10 中間層 (隠れ層) 出力層入力層 𝑥 𝑦 1 1 Unit 0 Unit
15 𝑤0,1 0 𝑤0,2 0 𝑤0,1 1 𝑤1,1 1 𝑤2,1 1 𝑤1,15 0 𝑤1,1 0 結合係数 Layer 0 Layer 1 Layer 2 出力層のユニットの活 性化関数は指定され ていないので、linear ∴ ℎ 𝑧 = 𝑧 𝑦𝑗 1 = sigmoid 𝑧𝑗 1 , 𝑗 ≥1 中間層のユニット𝑗の出力 𝑦 = 𝑦1 2 = 𝑧1 2
11.
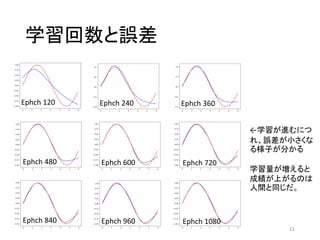
学習回数と誤差 11 Ephch 120 Ephch
240 Ephch 360 Ephch 480 Ephch 600 Ephch 720 Ephch 840 Ephch 960 Ephch 1080 ←学習が進むにつ れ、誤差が小さくな る様子が分かる 学習量が増えると 成績が上がるのは 人間と同じだ。
12.
より一般的な 非線形回帰モデル 12
13.
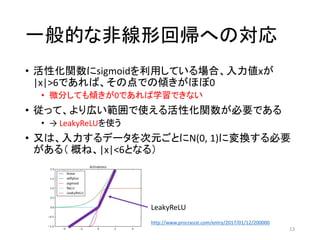
一般的な非線形回帰への対応 • 活性化関数にsigmoidを利用している場合、入力値xが |x|>6であれば、その点での傾きがほぼ0 • 微分しても傾きが0であれば学習できない •
従って、より広い範囲で使える活性化関数が必要である • → LeakyReLUを使う • 又は、入力するデータを次元ごとにN(0, 1)に変換する必要 がある( 概ね、|x|<6となる) 13 http://www.procrasist.com/entry/2017/01/12/200000 LeakyReLU
14.
14 • 以降のスライドでは、下記のプログラムを使った解説を行います • 一般的に拡張した非線形回帰用のサンプルです
15.
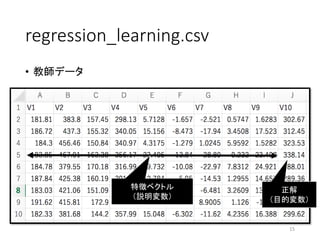
regression_learning.csv • 教師データ 15 特徴ベクトル (説明変数) 正解 (目的変数)
16.
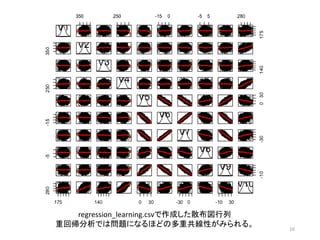
16 regression_learning.csvで作成した散布図行列 重回帰分析では問題になるほどの多重共線性がみられる。
17.
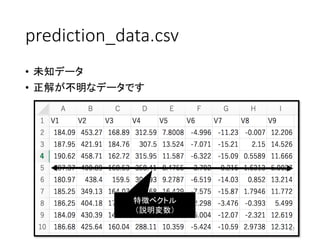
prediction_data.csv • 未知データ • 正解が不明なデータです 17 特徴ベクトル (説明変数)
18.
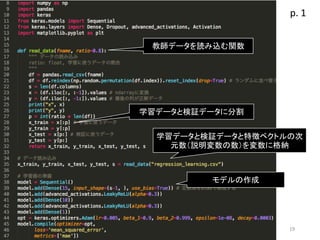
non_linear_regression.py • 学習を実行するプログラム • 読み込んだ教師データを自動的に学習データと検証デー タに分けて、過学習の判定と未知データに対する予測精度 の評価ができる 18
19.
19 教師データを読み込む関数 モデルの作成 学習データと検証データに分割 学習データと検証データと特徴ベクトルの次 元数(説明変数の数)を変数に格納 p. 1
20.
20 学習 結合係数の保存など 学習データと検証データのlossの変化をグラフとして表示 検証データの正解と予測値と で散布図を作成して表示 p. 2
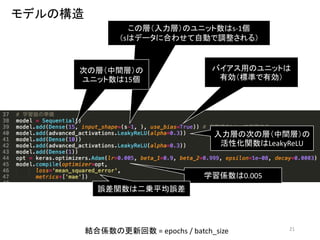
21.
21 入力層の次の層(中間層)の 活性化関数はLeakyReLU この層(入力層)のユニット数はs-1個 (sはデータに合わせて自動で調整される) 学習係数は0.005 次の層(中間層)の ユニット数は15個 バイアス用のユニットは 有効(標準で有効) 誤差関数は二乗平均誤差 モデルの構造 結合係数の更新回数 = epochs
/ batch_size
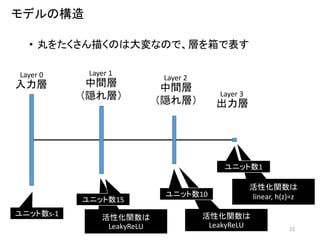
22.
活性化関数は linear, h(z)=z 活性化関数は LeakyReLU 活性化関数は LeakyReLU 22 •
丸をたくさん描くのは大変なので、層を箱で表す モデルの構造 ユニット数s-1 ユニット数15 ユニット数10 ユニット数1 中間層 (隠れ層) 出力層 入力層 Layer 0 Layer 1 Layer 3 中間層 (隠れ層) Layer 2
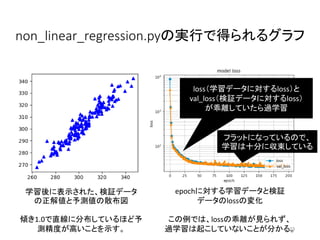
23.
non_linear_regression.pyの実行で得られるグラフ 23 epochに対する学習データと検証 データのlossの変化 この例では、lossの乖離が見られず、 過学習は起こしていないことが分かる。 学習後に表示された、検証データ の正解値と予測値の散布図 傾き1.0で直線に分布しているほど予 測精度が高いことを示す。 loss(学習データに対するloss)と val_loss(検証データに対するloss) が乖離していたら過学習 フラットになっているので、 学習は十分に収束している
24.
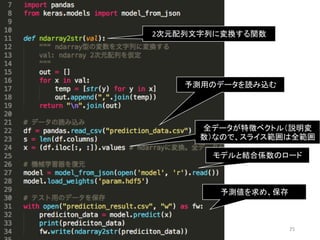
prediction.py • 正解の不明な未知データを予測する 24
25.
25 2次元配列文字列に変換する関数 モデルと結合係数のロード 予測用のデータを読み込む 予測値を求め、保存 全データが特徴ベクトル(説明変 数)なので、スライス範囲は全範囲
26.
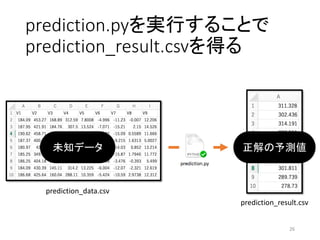
prediction.pyを実行することで prediction_result.csvを得る 26 prediction_result.csv prediction_data.csv 未知データ 正解の予測値
27.
27
28.
28 非線形近似をニューラルネットワーク(NN)で実現するには 非線形な活性化関数を持つ中間層を追加するだけという、 なんとも単純なお話でした。 さて、これでNNを使った線形回帰の基本は終了です 次はNNを使って識別問題にトライしてみましょう
Download


























![[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision](https://cdn.slidesharecdn.com/ss_thumbnails/dlkobayashi0115-210115012308-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]近年のエネルギーベースモデルの進展](https://cdn.slidesharecdn.com/ss_thumbnails/energybasedmodel-200124020855-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]GQNと関連研究,世界モデルとの関係について](https://cdn.slidesharecdn.com/ss_thumbnails/20180817-180827085537-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]MetaFormer is Actually What You Need for Vision](https://cdn.slidesharecdn.com/ss_thumbnails/20220121metaformer-220121085750-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]A Bayesian Perspective on Generalization and Stochastic Gradient Descent](https://cdn.slidesharecdn.com/ss_thumbnails/20171106dl2-171108033614-thumbnail.jpg?width=640&height=640&fit=bounds)












![[DL輪読会]Scalable Training of Inference Networks for Gaussian-Process Models](https://cdn.slidesharecdn.com/ss_thumbnails/mainslideshare1-190927025239-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL Hacks] Deterministic Variational Inference for RobustBayesian Neural Netw...](https://cdn.slidesharecdn.com/ss_thumbnails/adobepdffile2-190628001736-thumbnail.jpg?width=640&height=640&fit=bounds)





























