研究の背景
• DNNを統計・学習理論で解析する論⽂
• Suzuki,T. (2018). Fast learning rate of deep learning via a
kernel perspective. JMLR W&CP (AISTATS).
• Schmidt-Hieber, J. (2017). Nonparametric regression using
deep neural networks with ReLU activation function. arXiv.
• Neyshabur, B., Tomioka, R., & Srebro, N. (2015). Norm-
based capacity control in neural networks. JMLR W&CP
(COLT).
• Sun, S., Chen, W., Wang, L., & Liu, T. Y. (2015). Large
margin deep neural networks: theory and algorithms, arXiv.
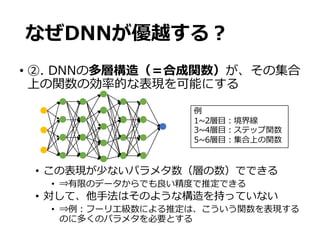
• ⾮滑らかな構造は主たる関⼼ではない
区分上で滑らかな関数の定式化
• 定式化の流れ
• 1. [0,1]-上の滑らかな関数
•2. [0,1]-に含まれる区分
• 1. [0,1]-
上の滑らかな関数
• 準備:ヘルダーノルム
• 定義:ヘルダー空間
G[✓`](x) = x(`)
,
where x` is defined inductively as
x(0)
:= x,
x(`0)
:= ⌘(A`0 x(`0 1)
+ b`0 ), for `0
= 1, ..., ` 1,
where ⌘ is an element-wise ReLU function, i.e., ⌘(x) = (max{0, x1}, ..., max{0, x
Here, we define that c(✓) denotes a number of non-zero parameters in ✓.
1.2. Characterization for True functions. We consider a piecewise smooth
functions for characterizing f⇤. To this end, we introduce a formation of
some set of functions.
Smooth Functions Secondly, a set for smooth functions is introduced.
With ↵ > 0, let us define the H¨older norm
kfkH := max
|a|b c
sup
x2[ 1,1]D
|@a
f(x)| + max
|a|=b c
sup
x,x02[ 1,1]D
|@af(x) @af(x0)|
|x x0| b c
,
and also H ([ 1, 1]d) be the H¨older space such that
H = H ([ 1, 1]D
) := f : [ 1, 1]D
! R |kfkH CH ,
where CH is some finite constant.
Date: January 13, 2018.
H = H ([0, 1]D
) = f : [0, 1]D
! R|kfkH < 1
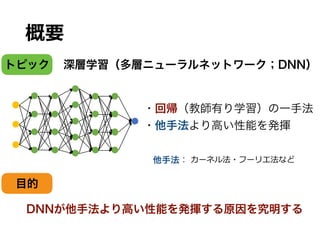
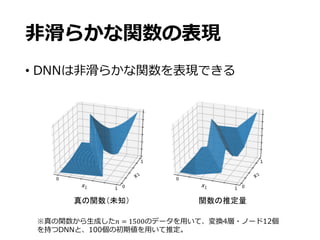
主結果1
• ⾮ベイズ推定量は以下のレートを持つ
𝑓∗
∈ ℱw,c,f,xとする。層が𝑂• 1 +
x
-
+
f
Z-GZ
で⾮ゼロパラメタ
数がΘ 𝑛
‘
’“”‘ + 𝑛
‘•–
—”‘•– のDNNのうち、以下を⾼確率で満たす
ものが存在する:
定理1
⼀項⽬:滑らかな関数 𝑓 ∈ 𝐻x
の推定レート
⼆項⽬:区分の境界関数 𝑏 ∈ ℬc,f の推定レート
𝑂• は対数項を省略したランダウ記法
k ˆfL
f⇤
k2
L2 = ˜O
⇣
max
n
n 2 /(2 +D)
, n ↵/(↵+D 1)
o⌘
28.
主結果2
• ベイズ推定量も同様のレートを持つ
𝑓∗
∈ ℱw,c,f,xとする。層が𝑂• 1 +
x
-
+
f
Z-GZ
で⾮ゼロパラメタ
数がΘ 𝑛
‘
’“”‘ + 𝑛
‘•–
—”‘•– のDNNのうち、以下を満たすものが存
在する:
定理2
DNNによる両推定量は、同じレートで
区分上で滑らかな関数を⼀致推定できる
E
h
k ˆfB
f⇤
k2
L2
i
= ˜O
⇣
max
n
n 2 /(2 +D)
, n ↵/(↵+D 1)
o⌘
29.
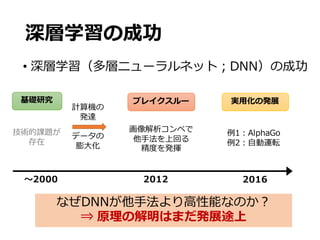
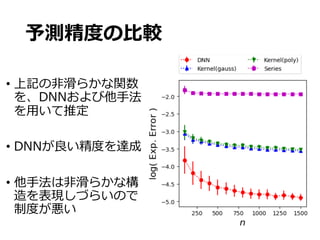
DNNの最適性の結果
• なおこのレートは、区分上で滑らかな関数を推定
する上での最適レートである
• これを収束レートのminimax下限といい、達成でき
る精度の理論的な限界値を表現している。
𝑓̅ を任意の推定量とする。このとき、ある定数 𝐶 > 0 が存在
し、以下の不等式が成⽴する:
定理3
inf
¯f
sup
f⇤2FM,J,↵,
E
⇥
k ¯f f⇤
k2
L2
⇤
> C max
n
n 2 /(2 +D)
, n ↵/(↵+D 1)
o
30.
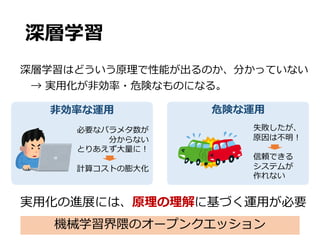
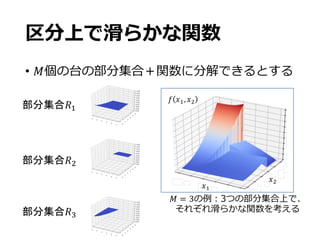
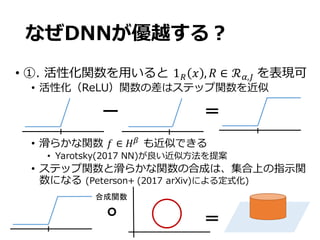
他⼿法に関する命題
• いくつかの他⼿法は⾮滑らかな関数が表現できない
• 𝑓∗
∈ℱc,w,f,xのような⾮滑らかな関数は、上記カーネルに
よるRKHSでは表現できない
𝑓"š
をカーネル法による推定量とする。カーネル関数は
Gaussian or 多項式カーネルとする。
ある𝑓∗
∈ ℱc,w,f,xと定数𝐶š > 0が存在し、以下が成⽴する:
命題1
E
h
k ˆfK
f⇤
k2
L2
i
! CK > 0.
31.
他⼿法に関する命題
• 表現⼒が⾼い⼿法も、精度が悪化する。
• フーリエ基底は𝑓∗
∈ℱc,w,f,xを表現できるが、表現
に必要な基底の数が多いため、精度が下がる。
𝑓"›
を直交シリーズ法による推定量とし、基底関数はフーリ
エ or 三⾓関数基底とする。ある𝑓∗
∈ ℱw,c,f,xが存在し、パ
ラメタ𝜅 > max −
Zx
Zx•-
, −
f
f•-G9
のもと以下が成⽴する:
命題2
E
h
k ˆfF
f⇤
k2
L2
i
> Cn
参照論⽂
• Stone, C.J. (1982). Optimal global rates of convergence for nonparametric regression.
The annals of statistics, 1040-1053.
• Suzuki, T. (2018). Fast learning rate of deep learning via a kernel perspective. JMLR
W&CP (AISTATS).
• Schmidt-Hieber, J. (2017). Nonparametric regression using deep neural networks with
ReLU activation function. arXiv.
• Neyshabur, B., Tomioka, R., & Srebro, N. (2015). Norm-based capacity control in neural
networks. JMLR W&CP (COLT).
• Sun, S., Chen, W., Wang, L., & Liu, T. Y. (2015). Large margin deep neural networks:
theory and algorithms, arXiv.
• Choromanska, A., Henaff, M., Mathieu, M., Arous, G. B., & LeCun, Y. (2017) The loss
surfaces of multilayer networks. JMLR W&CP (AISTATS).
• Kawaguchi, K. (2016). Deep learning without poor local minima. In Advances in Neural
Information Processing Systems.
• Yarotsky, D. (2017). Error bounds for approximations with deep ReLU networks. Neural
Networks, 94, 103-114.
• Safran, I., & Shamir, O. (2017). Depth-width tradeoffs in approximating natural functions
with neural networks. JMLR W&CP (ICML).
• Zhang, C., Bengio, S., Hardt, M., Recht, B., & Vinyals, O. (2016). Understanding deep
learning requires rethinking generalization. ICLR.
• Xu, A., & Raginsky, M. (2017). Information-theoretic analysis of generalization capability
of learning algorithms. In Advances in Neural Information Processing Systems.





![深層学習が解く問題
• 推定量 𝑓" ∈ ℱ%% による誤差 を評価
真の関数(未知) 𝑓∗
: [0,1]-
→ ℝ
データの生成分布 Y = 𝑓∗
𝑋 + 𝜖
𝑛個のi.i.d.観測 𝑋6, 𝑌6 689
:
ℱ%%:DNNで表現できる関数の集合
※分類問題( 𝑌 が離散値)の場合でも同じフレームに当てはまる
回帰による関数の推定
k ˆf f⇤
k2](https://image.slidesharecdn.com/slide180214-180214073347/85/slide-9-320.jpg)

![深層学習が解く問題
• 興味がある問題
• なぜDNNによる推定量 𝑓" ∈ ℱ%% は が
⼩さいのか?
真の関数(未知) 𝑓∗
: [0,1]-
→ ℝ
データの生成分布 Y = 𝑓∗
𝑋 + 𝜖
𝑛個のi.i.d.観測 𝑋6, 𝑌6 689
:
ℱ%%:DNNで表現できる関数の集合
回帰による関数の推定
k ˆf f⇤
k2](https://image.slidesharecdn.com/slide180214-180214073347/85/slide-12-320.jpg)





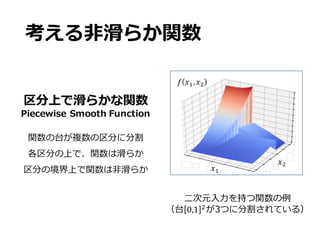
![区分上で滑らかな関数の定式化
• 定式化の流れ
• 1. [0,1]-上の滑らかな関数
• 2. [0,1]-に含まれる区分
• 1. [0,1]-
上の滑らかな関数
• 準備:ヘルダーノルム
• 定義:ヘルダー空間
G[✓`](x) = x(`)
,
where x` is defined inductively as
x(0)
:= x,
x(`0)
:= ⌘(A`0 x(`0 1)
+ b`0 ), for `0
= 1, ..., ` 1,
where ⌘ is an element-wise ReLU function, i.e., ⌘(x) = (max{0, x1}, ..., max{0, x
Here, we define that c(✓) denotes a number of non-zero parameters in ✓.
1.2. Characterization for True functions. We consider a piecewise smooth
functions for characterizing f⇤. To this end, we introduce a formation of
some set of functions.
Smooth Functions Secondly, a set for smooth functions is introduced.
With ↵ > 0, let us define the H¨older norm
kfkH := max
|a|b c
sup
x2[ 1,1]D
|@a
f(x)| + max
|a|=b c
sup
x,x02[ 1,1]D
|@af(x) @af(x0)|
|x x0| b c
,
and also H ([ 1, 1]d) be the H¨older space such that
H = H ([ 1, 1]D
) := f : [ 1, 1]D
! R |kfkH CH ,
where CH is some finite constant.
Date: January 13, 2018.
H = H ([0, 1]D
) = f : [0, 1]D
! R|kfkH < 1](https://image.slidesharecdn.com/slide180214-180214073347/85/slide-19-320.jpg)
![ℝ-
[0,1]-
境界線関数 𝒃
𝐽個に分割した円周の変形で得られる。 𝛼回微分可能。
区分上で滑らかな関数の定式化
• 2. [0,1]-
に含まれる区分
• 準備:区分の滑らかな境界線
• 𝑆-G9: 𝐷次元空間内の球⾯, 𝑆̅-G9: 𝐷次元空間内の球⾯
• 𝑉9,… , 𝑉c:ℝ-内の分割, 𝐹S:𝑆̅-G9 → 𝑉S : 滑らかな写像
ℬc,f ≔ 𝑏: 𝑆-G9
→ ℝ-
𝑖𝑛𝑗𝑒𝑐𝑡𝑖𝑣𝑒, 𝑏@ ∘ 𝐹S ∈ 𝐻f
, 𝑑 ∈ 𝐷 , 𝑗 ∈ 𝐽
𝑏𝑆-G9](https://image.slidesharecdn.com/slide180214-180214073347/85/slide-20-320.jpg)
![区分上で滑らかな関数の定式化
• 2. [0,1]-
に含まれる区分
• 境界線の内部を 𝐼(⋅) で表現するとする
• 関数の台の部分集合の族
ℛc,f ≔ 𝐼 𝑏 ∩ 0,1 -
: 𝑏 ∈ ℬc,f
Boundary Fragment 集合族(の拡張)
Dudley (1974 JAT)
𝐼 𝑏
境界線は折点を除いて𝛼回微分可能
𝛼 = 2のとき、[0,1]-内の全ての凸集合
族で稠密](https://image.slidesharecdn.com/slide180214-180214073347/85/slide-21-320.jpg)


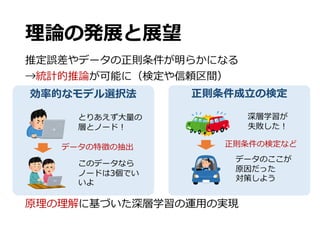
![⼆種類の推定量
• ベイズ推定量
• ⾮凸最適化の問題が発⽣しない
• 計算量は⽐較的⼤きい
事前分布 Π… 𝑓 for 𝑓 ∈ ℱ%%
Π… はNNの⾮ゼロパラメタ(固定)に⼀様分布
事後分布 dΠ… 𝑓|𝐷 ∝ exp −∑ 𝑌6 − 𝑓 𝑋6
Z
6∈ : 𝜎GZ
dΠ… 𝑓
𝐷 = 𝑋6, 𝑌6 6∈[:]: データセット, 𝜎Z
: ノイズ分散
推定量 𝑓"Œ ≔ ∫ 𝑓𝑑Π…(𝑓|𝐷)
ベイズ事後平均
◎
×](https://image.slidesharecdn.com/slide180214-180214073347/85/slide-25-320.jpg)



















![[DL輪読会]Neural Ordinary Differential Equations](https://cdn.slidesharecdn.com/ss_thumbnails/nnasode1-190111001755-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]A Bayesian Perspective on Generalization and Stochastic Gradient Descent](https://cdn.slidesharecdn.com/ss_thumbnails/20171106dl2-171108033614-thumbnail.jpg?width=640&height=640&fit=bounds)








![[DL輪読会]Flow-based Deep Generative Models](https://cdn.slidesharecdn.com/ss_thumbnails/20190307-190328024744-thumbnail.jpg?width=640&height=640&fit=bounds)















![[DL輪読会]Scalable Training of Inference Networks for Gaussian-Process Models](https://cdn.slidesharecdn.com/ss_thumbnails/mainslideshare1-190927025239-thumbnail.jpg?width=640&height=640&fit=bounds)















