Downloaded 89 times




























![Unifying the Pieces: GraphX
// http://spark.apache.org/docs/latest/graphx-programming-guide.html!
!
val vertexArray = Array(!
(1L, ("Alice", 28)),!
(2L, ("Bob", 27)),!
(3L, ("Charlie", 65)),!
(4L, ("David", 42)),!
(5L, ("Ed", 55)),!
(6L, ("Fran", 50))!
)!
!
val edgeArray = Array(!
Edge(2L, 1L, 7),!
Edge(2L, 4L, 2),!
Edge(3L, 2L, 4),!
Edge(3L, 6L, 3),!
Edge(4L, 1L, 1),!
Edge(5L, 2L, 2),!
Edge(5L, 3L, 8),!
Edge(5L, 6L, 3)!
)!
!
val vertexRDD: RDD[(Long, (String, Int))] = sc.parallelize(vertexArray)!
val edgeRDD: RDD[Edge[Int]] = sc.parallelize(edgeArray)!
!
val graph: Graph[(String, Int), Int] = Graph(vertexRDD, edgeRDD)](https://image.slidesharecdn.com/sparkmesoscon-140820135216-phpapp01/85/MesosCon-2014-Spark-on-Mesos-34-320.jpg)









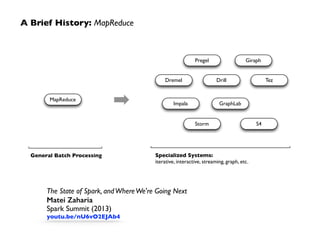
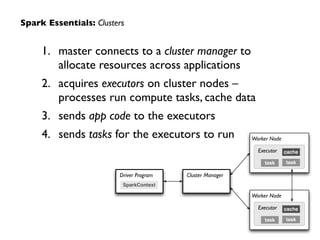
This document discusses Spark, an open-source cluster computing framework. It provides a brief history of Spark, describing how it generalized MapReduce to support more types of applications. Spark allows for batch, interactive, and real-time processing within a single framework using Resilient Distributed Datasets (RDDs) and a logical plan represented as a directed acyclic graph (DAG). The document also discusses how Spark can be used for applications like machine learning via MLlib, graph processing with GraphX, and streaming data with Spark Streaming.




































































































