Download as PDF, PPTX

















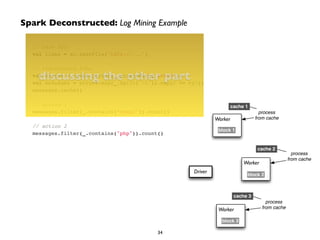
![Spark Deconstructed: Log Mining Example
At this point, take a look at the transformed
RDD operator graph:
scala> messages.toDebugString!
res5: String = !
MappedRDD[4] at map at <console>:16 (3 partitions)!
MappedRDD[3] at map at <console>:16 (3 partitions)!
FilteredRDD[2] at filter at <console>:14 (3 partitions)!
MappedRDD[1] at textFile at <console>:12 (3 partitions)!
HadoopRDD[0] at textFile at <console>:12 (3 partitions)
26](https://image.slidesharecdn.com/amswhatsnew-141129225019-conversion-gate02/85/What-s-new-with-Apache-Spark-26-320.jpg)










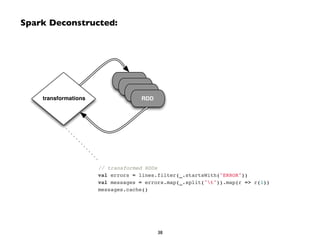




![Unifying the Pieces: GraphX
// http://spark.apache.org/docs/latest/graphx-programming-guide.html!
!
import org.apache.spark.graphx._!
import org.apache.spark.rdd.RDD!
!
case class Peep(name: String, age: Int)!
!
val vertexArray = Array(!
(1L, Peep("Kim", 23)), (2L, Peep("Pat", 31)),!
(3L, Peep("Chris", 52)), (4L, Peep("Kelly", 39)),!
(5L, Peep("Leslie", 45))!
)!
val edgeArray = Array(!
Edge(2L, 1L, 7), Edge(2L, 4L, 2),!
Edge(3L, 2L, 4), Edge(3L, 5L, 3),!
Edge(4L, 1L, 1), Edge(5L, 3L, 9)!
)!
!
val vertexRDD: RDD[(Long, Peep)] = sc.parallelize(vertexArray)!
val edgeRDD: RDD[Edge[Int]] = sc.parallelize(edgeArray)!
val g: Graph[Peep, Int] = Graph(vertexRDD, edgeRDD)!
!
val results = g.triplets.filter(t => t.attr > 7)!
!
for (triplet <- results.collect) {!
println(s"${triplet.srcAttr.name} loves ${triplet.dstAttr.name}")!
}
44](https://image.slidesharecdn.com/amswhatsnew-141129225019-conversion-gate02/85/What-s-new-with-Apache-Spark-44-320.jpg)


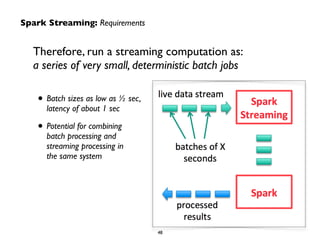












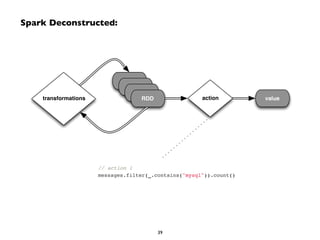
![Demo: PySpark Streaming Network Word Count
import sys!
from pyspark import SparkContext!
from pyspark.streaming import StreamingContext!
!
sc = SparkContext(appName="PyStreamNWC", master="local[*]")!
ssc = StreamingContext(sc, Seconds(5))!
!
lines = ssc.socketTextStream(sys.argv[1], int(sys.argv[2]))!
!
counts = lines.flatMap(lambda line: line.split(" ")) !
.map(lambda word: (word, 1)) !
.reduceByKey(lambda a, b: a+b)!
!
counts.pprint()!
!
ssc.start()!
ssc.awaitTermination()
61](https://image.slidesharecdn.com/amswhatsnew-141129225019-conversion-gate02/85/What-s-new-with-Apache-Spark-61-320.jpg)
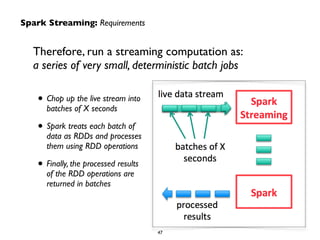
![Demo: PySpark Streaming Network Word Count - Stateful
import sys!
from pyspark import SparkContext!
from pyspark.streaming import StreamingContext!
!
def updateFunc (new_values, last_sum):!
return sum(new_values) + (last_sum or 0)!
!
sc = SparkContext(appName="PyStreamNWC", master="local[*]")!
ssc = StreamingContext(sc, Seconds(5))!
ssc.checkpoint("checkpoint")!
!
lines = ssc.socketTextStream(sys.argv[1], int(sys.argv[2]))!
!
counts = lines.flatMap(lambda line: line.split(" ")) !
.map(lambda word: (word, 1)) !
.updateStateByKey(updateFunc) !
.transform(lambda x: x.sortByKey())!
!
counts.pprint()!
!
ssc.start()!
ssc.awaitTermination()
62](https://image.slidesharecdn.com/amswhatsnew-141129225019-conversion-gate02/85/What-s-new-with-Apache-Spark-62-320.jpg)

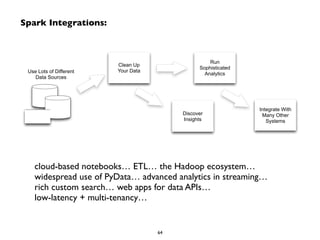


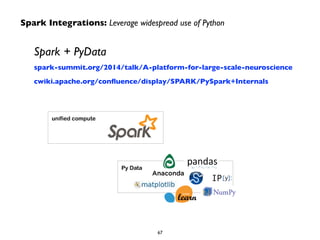
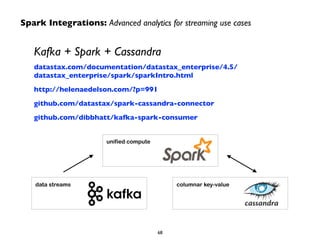






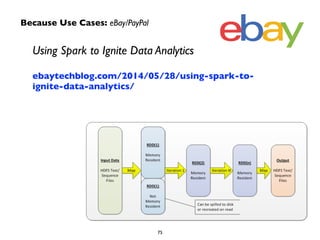

















The document provides an overview of Apache Spark, including its history and key capabilities. It discusses how Spark was developed in 2009 at UC Berkeley and later open sourced, and how it has since become a major open-source project for big data. The document summarizes that Spark provides in-memory performance for ETL, storage, exploration, analytics and more on Hadoop clusters, and supports machine learning, graph analysis, and SQL queries.
























































































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)





