Downloaded 100 times


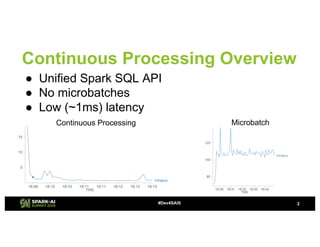


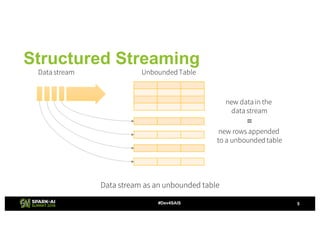

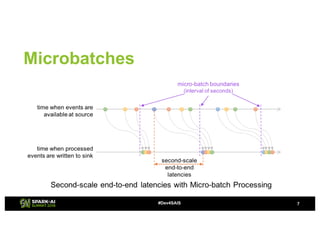
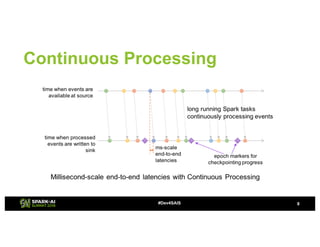
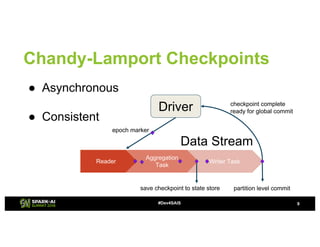
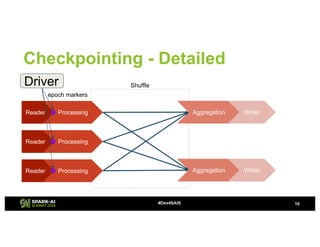
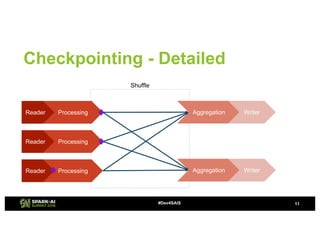
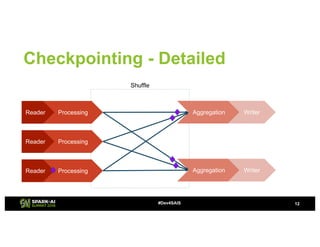
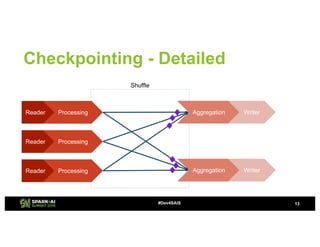
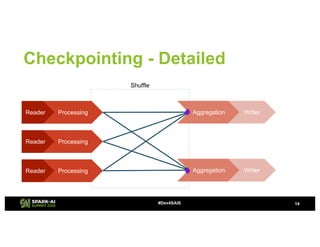
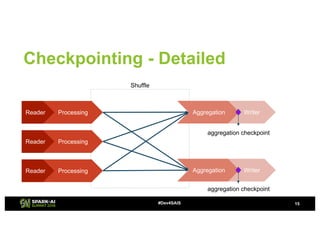
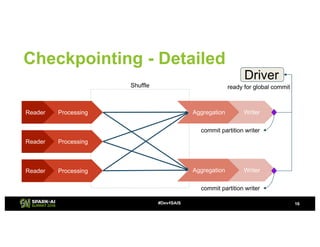





The document provides an overview of continuous processing in Databricks structured streaming, highlighting features such as the unified Spark SQL API, low latency, and the representation of data as a virtual append-only table. It discusses the differences between continuous processing and microbatches, and outlines the ongoing work for improvements in event time handling, performance testing, and additional data sources. The content also addresses checkpointing and data processing mechanisms within the continuous processing framework.












































































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)










