Downloaded 91 times



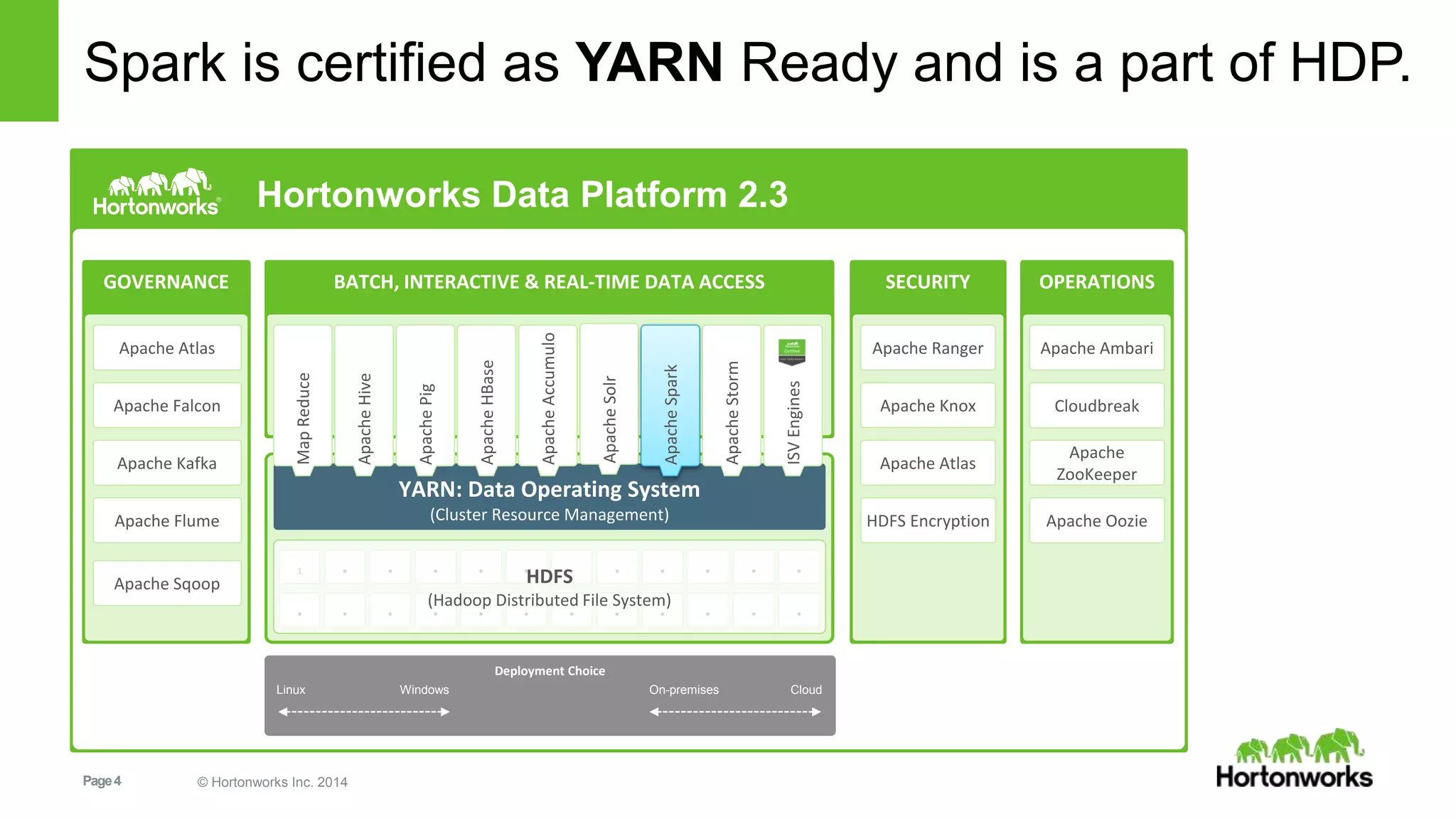
















![Page26 © Hortonworks Inc. 2014
Spark Applications
Are a definition in code of
• RDD creation
• Actions
• Persistence
Results in the creation of a DAG (Directed Acyclic Graph) [workflow]
• Each DAG is compiled into stages
• Each Stage is executed as a series of Tasks
• Each Task operates in parallel on assigned partitions](https://image.slidesharecdn.com/sparkrecommendationdeckzeltov-160318135534/75/Spark-Advanced-Analytics-NJ-Data-Science-Meetup-Princeton-University-26-2048.jpg)

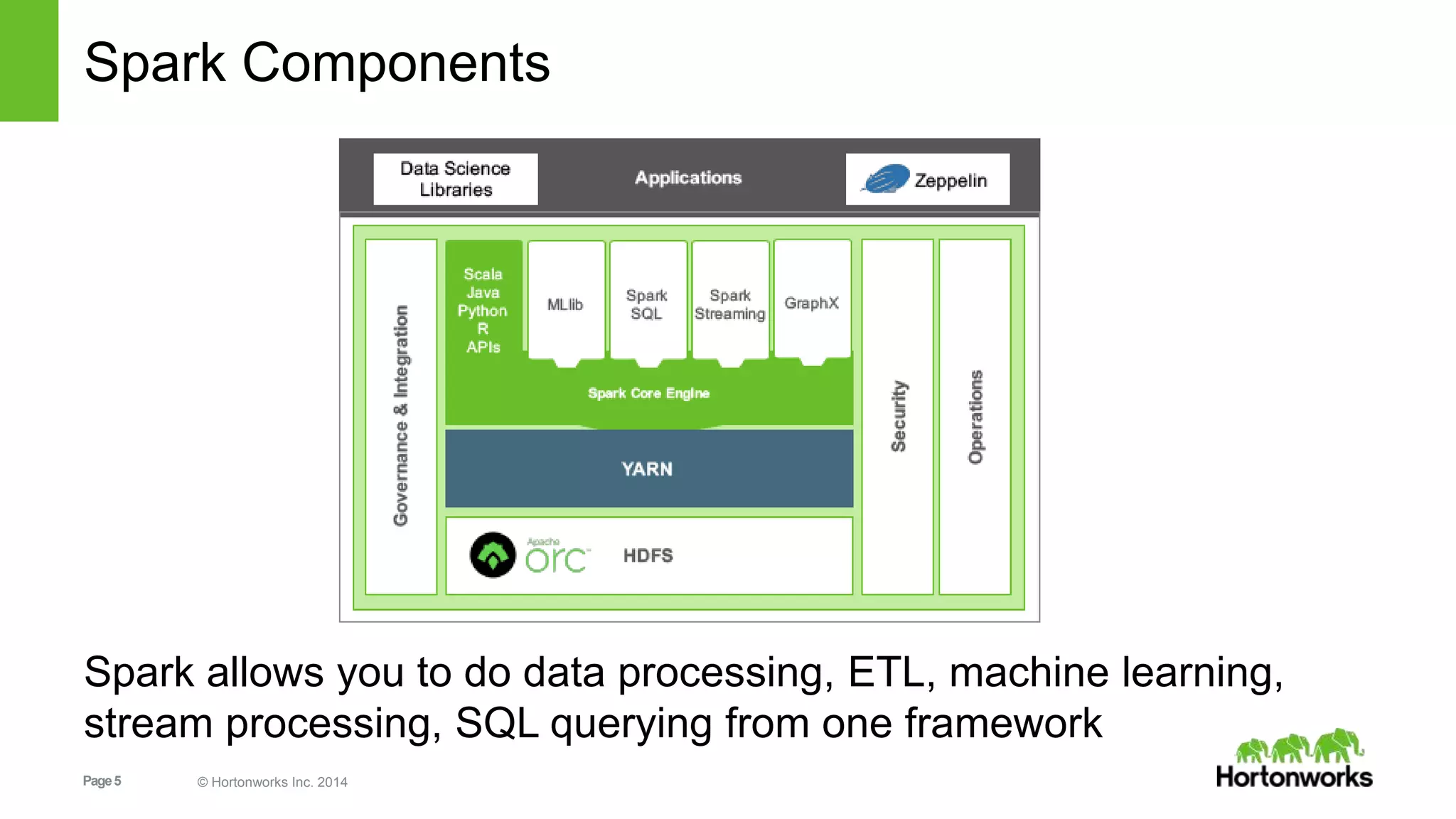
![Page28 © Hortonworks Inc. 2014
1. Resilient Distributed Dataset [RDD] Graph
val v = sc.textFile("hdfs://…some-hdfs-data")
mapmap reduceByKey collecttextFile
v.flatMap(line=>line.split(" "))
.map(word=>(word, 1)))
.reduceByKey(_ + _, 3)
.collect()
RDD[String]
RDD[List[String]]
RDD[(String, Int)]
Array[(String, Int)]
RDD[(String, Int)]](https://image.slidesharecdn.com/sparkrecommendationdeckzeltov-160318135534/75/Spark-Advanced-Analytics-NJ-Data-Science-Meetup-Princeton-University-28-2048.jpg)

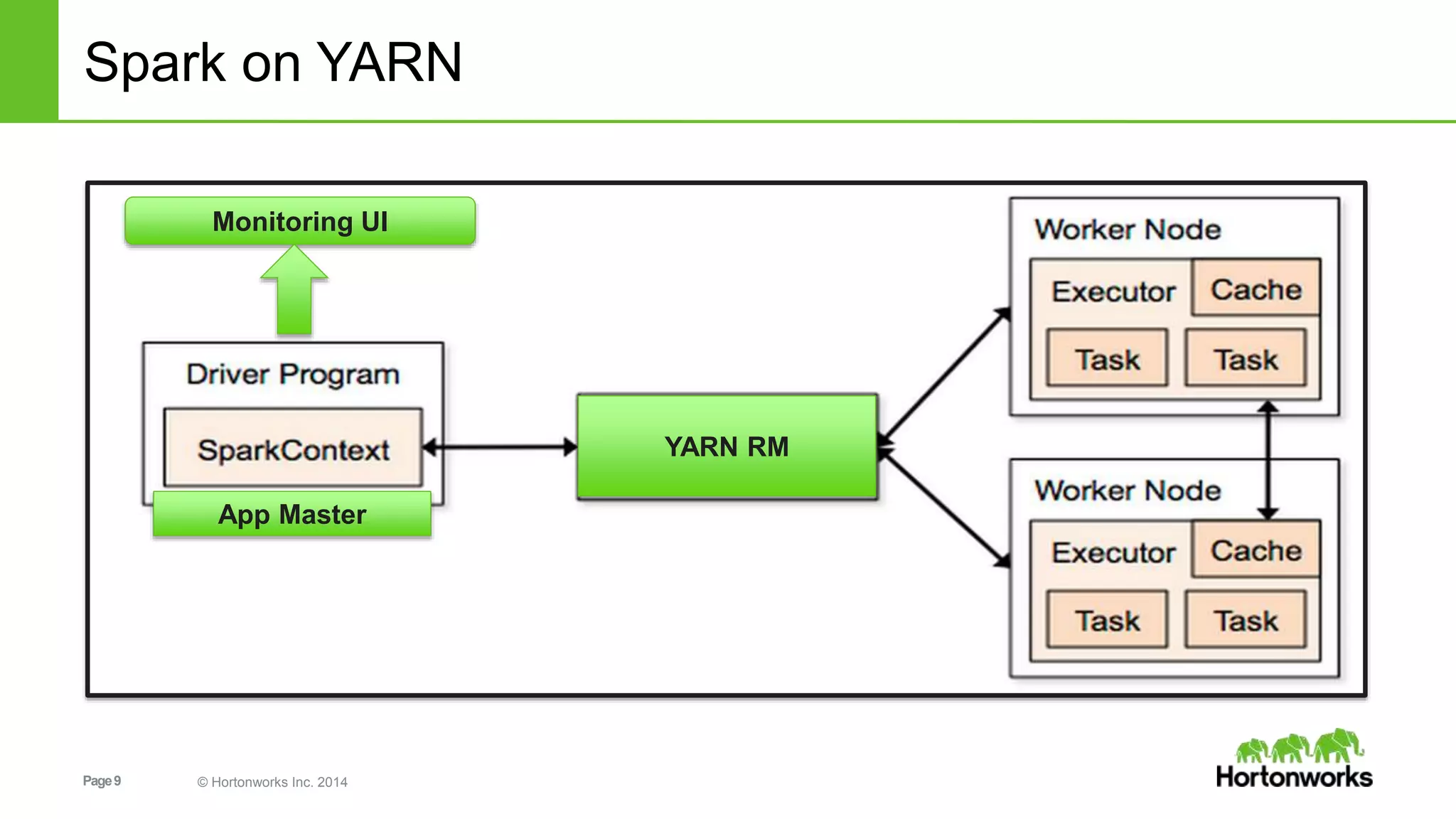
![Page30 © Hortonworks Inc. 2014
Looking at the State in the Machine
//run debug command to inspect RDD:
scala> fltr.toDebugString
//simplified output:
res1: String =
FilteredRDD[2] at filter at <console>:14
MappedRDD[1] at textFile at <console>:12
HadoopRDD[0] at textFile at <console>:12
30](https://image.slidesharecdn.com/sparkrecommendationdeckzeltov-160318135534/75/Spark-Advanced-Analytics-NJ-Data-Science-Meetup-Princeton-University-30-2048.jpg)


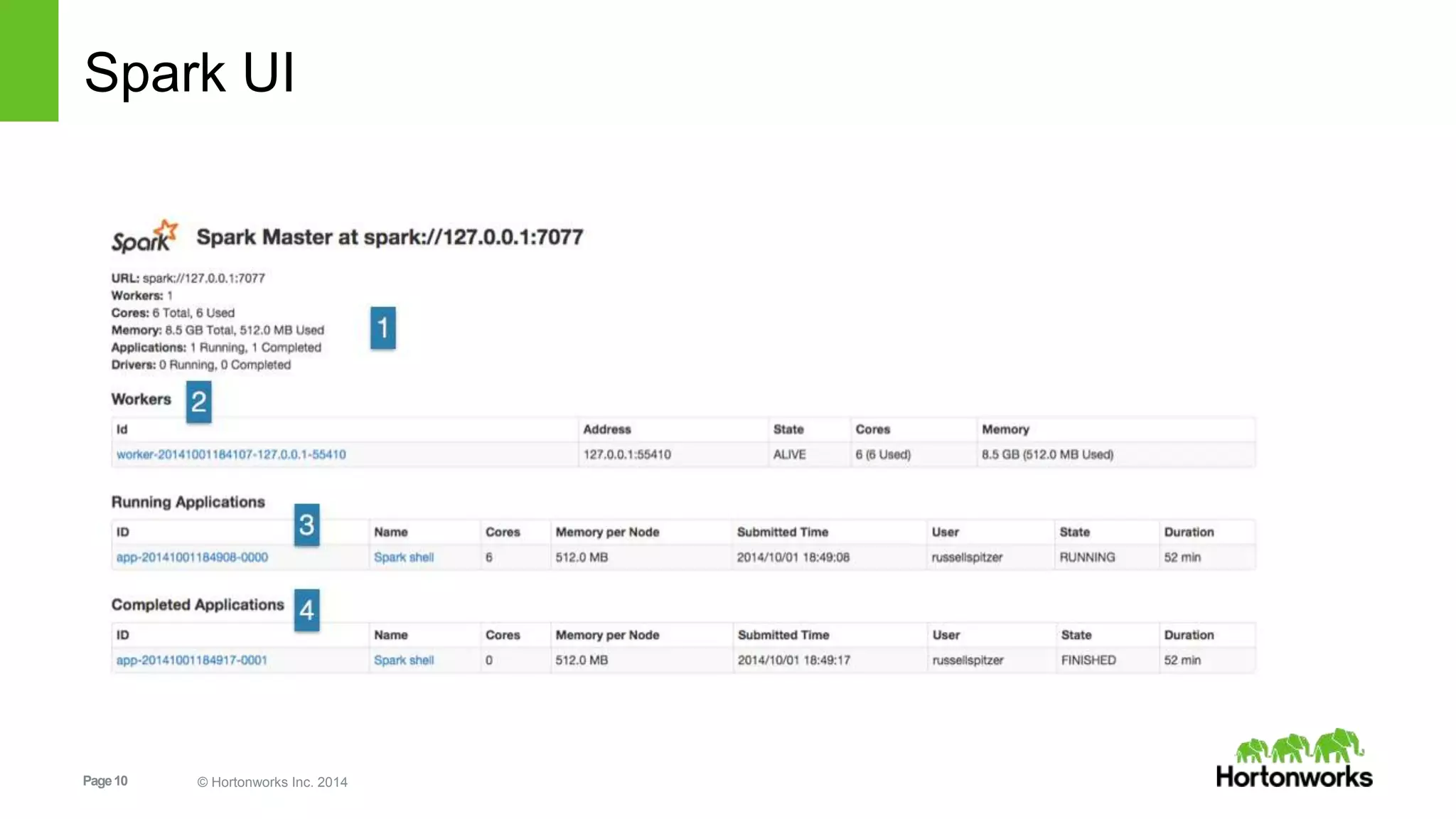
![Page33 © Hortonworks Inc. 2014
And Finally – the Formal ‘def’
def myFunc(line:String): Array[String]={
return line.split(",")
}
//and now that it has a name:
myFunc("Hi Mom, I’m home.").foreach(println)
Return type of the function)
Body of the function
Argument to the function)](https://image.slidesharecdn.com/sparkrecommendationdeckzeltov-160318135534/75/Spark-Advanced-Analytics-NJ-Data-Science-Meetup-Princeton-University-33-2048.jpg)













![Page49 © Hortonworks Inc. 2014
What About Integration With Hive?
scala> val hiveCTX = new org.apache.spark.sql.hive.HiveContext(sc)
scala> hiveCTX.hql("SHOW TABLES").collect().foreach(println)
…
[omniture]
[omniturelogs]
[orc_table]
[raw_products]
[raw_users]
…
49](https://image.slidesharecdn.com/sparkrecommendationdeckzeltov-160318135534/75/Spark-Advanced-Analytics-NJ-Data-Science-Meetup-Princeton-University-49-2048.jpg)
![Page50 © Hortonworks Inc. 2014
More Integration With Hive:
scala> hCTX.hql("DESCRIBE raw_users").collect().foreach(println)
[swid,string,null]
[birth_date,string,null]
[gender_cd,string,null]
scala> hCTX.hql("SELECT * FROM raw_users WHERE gender_cd='F' LIMIT
5").collect().foreach(println)
[0001BDD9-EABF-4D0D-81BD-D9EABFCD0D7D,8-Apr-84,F]
[00071AA7-86D2-4EB9-871A-A786D27EB9BA,7-Feb-88,F]
[00071B7D-31AF-4D85-871B-7D31AFFD852E,22-Oct-64,F]
[000F36E5-9891-4098-9B69-CEE78483B653,24-Mar-85,F]
[00102F3F-061C-4212-9F91-1254F9D6E39F,1-Nov-91,F]
50](https://image.slidesharecdn.com/sparkrecommendationdeckzeltov-160318135534/75/Spark-Advanced-Analytics-NJ-Data-Science-Meetup-Princeton-University-50-2048.jpg)
![Page51 © Hortonworks Inc. 2014
ORC at Spotify
16x less HDFS read when
using ORC versus Avro.(5)
IOi
32x less CPU when using ORC
versus Avro.(5)
CPUi
[2]](https://image.slidesharecdn.com/sparkrecommendationdeckzeltov-160318135534/75/Spark-Advanced-Analytics-NJ-Data-Science-Meetup-Princeton-University-51-2048.jpg)


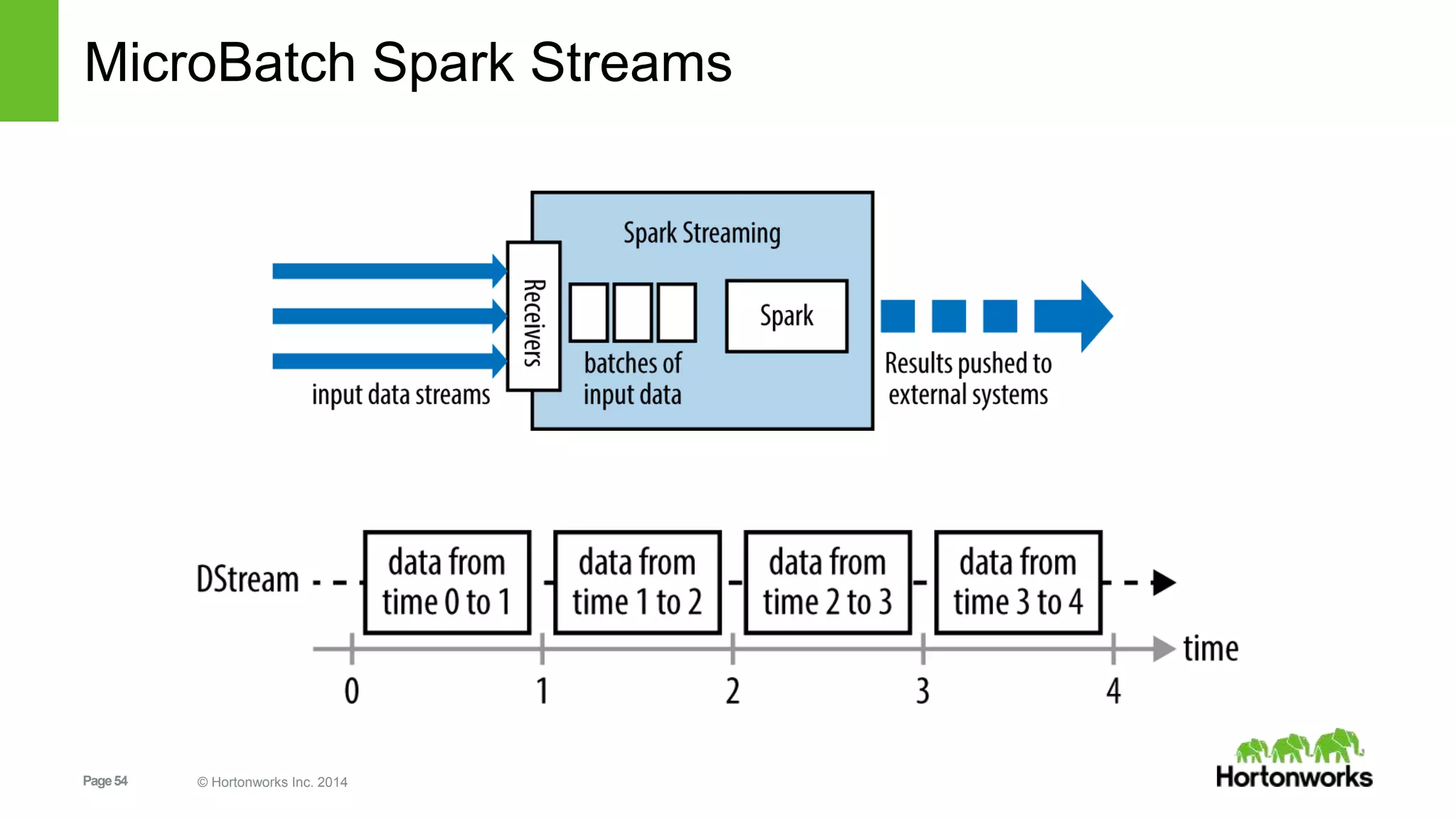



![Page59 © Hortonworks Inc. 2014 59
ML - Pipelines
• New algorithms KMeans [SPARK-7879], Naive Bayes [SPARK-
8600], Bisecting KMeans
• [SPARK-6517], Multi-layer Perceptron (ANN) [SPARK-2352],
Weighting for
• Linear Models [SPARK-7685]
• New transformers (close to parity with SciKit learn):
CountVectorizer [SPARK-8703],
• PCA [SPARK-8664], DCT [SPARK-8471], N-Grams [SPARK-8455]
• Calling into single machine solvers (coming soon as a package)](https://image.slidesharecdn.com/sparkrecommendationdeckzeltov-160318135534/75/Spark-Advanced-Analytics-NJ-Data-Science-Meetup-Princeton-University-59-2048.jpg)







![Page67 © Hortonworks Inc. 2014
Step 2: Feature Extraction
• Transform the string data in tuples of useful data and remove
unwanted pieces
• Ratings: UserID::MovieID::Rating::TImestamp
1::1193::5::978300760
1::661::3::978302109 => [(1, 1193, 5.0), (1, 914, 3.0), …]
• Movies: MovieID::Title::Genres
1::Toy Story (1995):: Animation|Children’s|Comedy
2::Jumanji (1995)::Adventure|Children’s|Fantasy
=> [(1, 'Toy Story (1995)'), (2, u'Jumanji (1995)'), …]](https://image.slidesharecdn.com/sparkrecommendationdeckzeltov-160318135534/75/Spark-Advanced-Analytics-NJ-Data-Science-Meetup-Princeton-University-67-2048.jpg)
![Page68 © Hortonworks Inc. 2014
def get_ratings_tuple(entry):
float(items[2])
items = entry.split('::')
return int(items[0]), int(items[1]),
def get_movie_tuple(entry):
items = entry.split('::')
return int(items[0]), items[1]
ratingsRDD = rawRatings.map(get_ratings_tuple).cache()
moviesRDD = rawMovies.map(get_movie_tuple).cache()
Step 2: Feature Extraction](https://image.slidesharecdn.com/sparkrecommendationdeckzeltov-160318135534/75/Spark-Advanced-Analytics-NJ-Data-Science-Meetup-Princeton-University-68-2048.jpg)
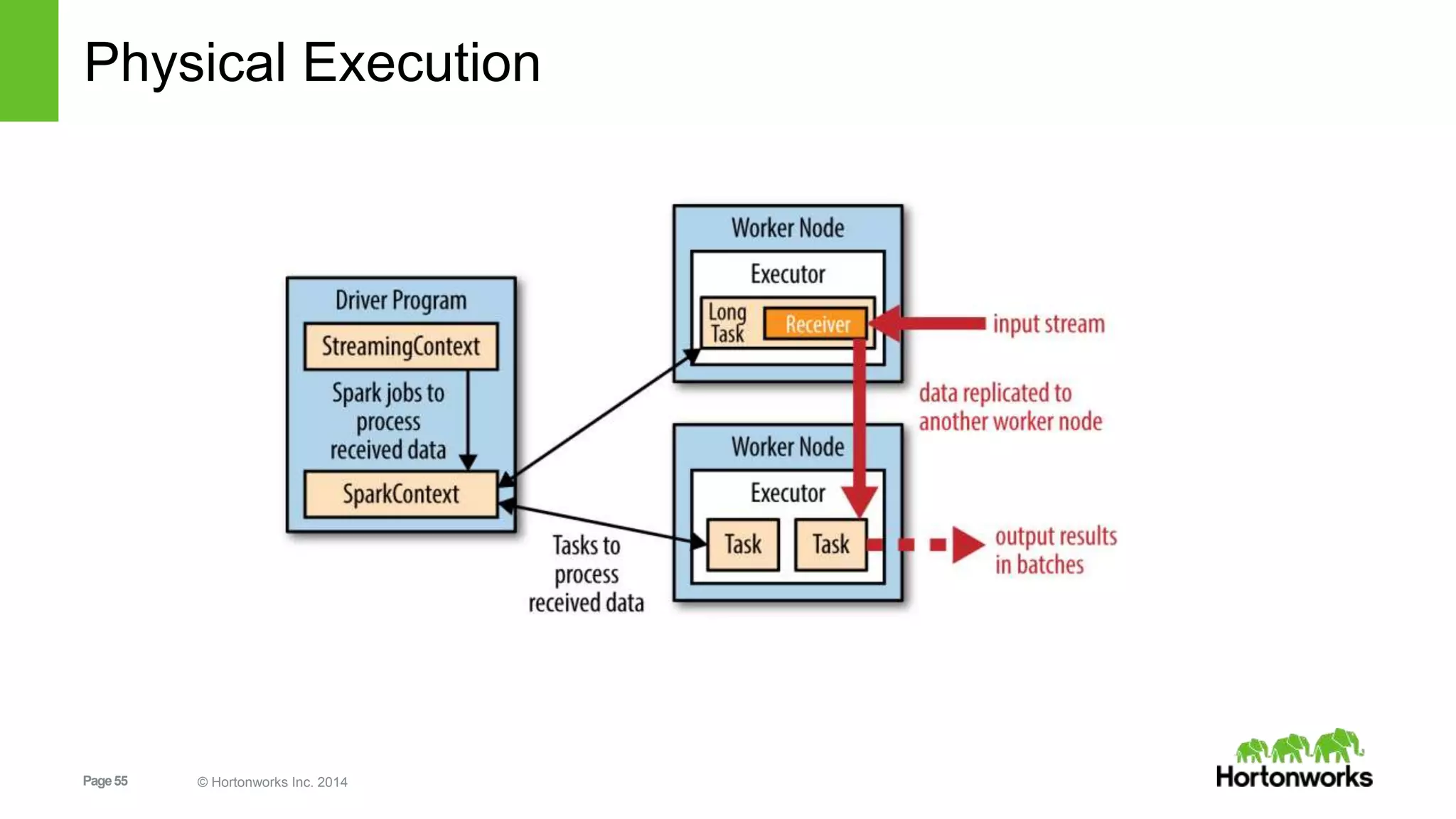
![Page69 © Hortonworks Inc. 2014
Step 2: Feature Extraction
• Inspect RDD using collect()
• Careful: make sure the whole dataset fits in the
memory of the driver
Driver
job
Executor
Task
Executor
Task
• Use take(num)
• Safer: takes a num-size subset
print 'Ratings: %s' % ratingsRDD.take(2)
Ratings: [(1, 1193, 5.0), (1, 914, 3.0)]
print 'Movies: %s' % moviesRDD.take(2)
Movies: [(1, u'Toy Story (1995)'), (2, u'Jumanji (1995)')]](https://image.slidesharecdn.com/sparkrecommendationdeckzeltov-160318135534/75/Spark-Advanced-Analytics-NJ-Data-Science-Meetup-Princeton-University-69-2048.jpg)

![Page71 © Hortonworks Inc. 2014
Step 3: Create Model – The naïve approach
• Calculate the average rating of a movie
• From the ratingsRDD, we create tuples containing all the ratings for a movie:
– Remember: ratingsRDD = (UserID, MovieID, Rating)
movieIDsWithRatingsRDD = (ratingsRDD
.map(lambda (user_id,movie_id,rating): (movie_id,[rating]))
.reduceByKey(lambda a,b: a+b))
• This is simpele map-reduce in spark:
• Map: (UserID, MovieID, Rating) => (MovieID, [Rating])
• Reduce: (MovieID1, [Rating1]), (MovieID1, [Rating2]) => (MovieID1, [Rating1,Rating2])](https://image.slidesharecdn.com/sparkrecommendationdeckzeltov-160318135534/75/Spark-Advanced-Analytics-NJ-Data-Science-Meetup-Princeton-University-71-2048.jpg)
![Page72 © Hortonworks Inc. 2014
Step 3: Create Model – The naïve approach
( len(RatingsTuple[1]), total/len(RatingsTuple[1])) )
movieIDsWithAvgRatingsRDD =
movieIDsWithRatingsRDD.map(getCountsAndAverages)
• Note that the new key-value tuples have MovieID as key and a nested tuple
(ratings,average) as value: [ (2, (332, 3.174698795180723) ), … ]
• Next map the data to an RDD with average and number of ratings
def getCountsAndAverages(RatingsTuple):
total = 0.0
for rating in RatingsTuple[1]:
total += rating
return ( RatingsTuple[0],](https://image.slidesharecdn.com/sparkrecommendationdeckzeltov-160318135534/75/Spark-Advanced-Analytics-NJ-Data-Science-Meetup-Princeton-University-72-2048.jpg)

![Page74 © Hortonworks Inc. 2014
Step 3: Create Model – The naïve approach
• The RDD now contains tuples of the correct form
Print movieNameWithAvgRatingsRDD.take(3)
[
(3.68181818181818, 'Happiest Millionaire, The (1967)', 22),
(3.04682274247491, 'Grumpier Old Men (1995)', 299),
(2.88297872340425, 'Hocus Pocus (1993)', 94)
]](https://image.slidesharecdn.com/sparkrecommendationdeckzeltov-160318135534/75/Spark-Advanced-Analytics-NJ-Data-Science-Meetup-Princeton-University-74-2048.jpg)

![Page76 © Hortonworks Inc. 2014
Step 3: Create Model – The naïve approach
value =
return
tuple[1]
(key + ' ' + value)
• sortFunction makes sure the tuples are sorted using both key and
value which insures a consistent sort, even if a key appears more
than once
def sortFunction(tuple):
key = unicode('%.3f' % tuple[0])](https://image.slidesharecdn.com/sparkrecommendationdeckzeltov-160318135534/75/Spark-Advanced-Analytics-NJ-Data-Science-Meetup-Princeton-University-76-2048.jpg)



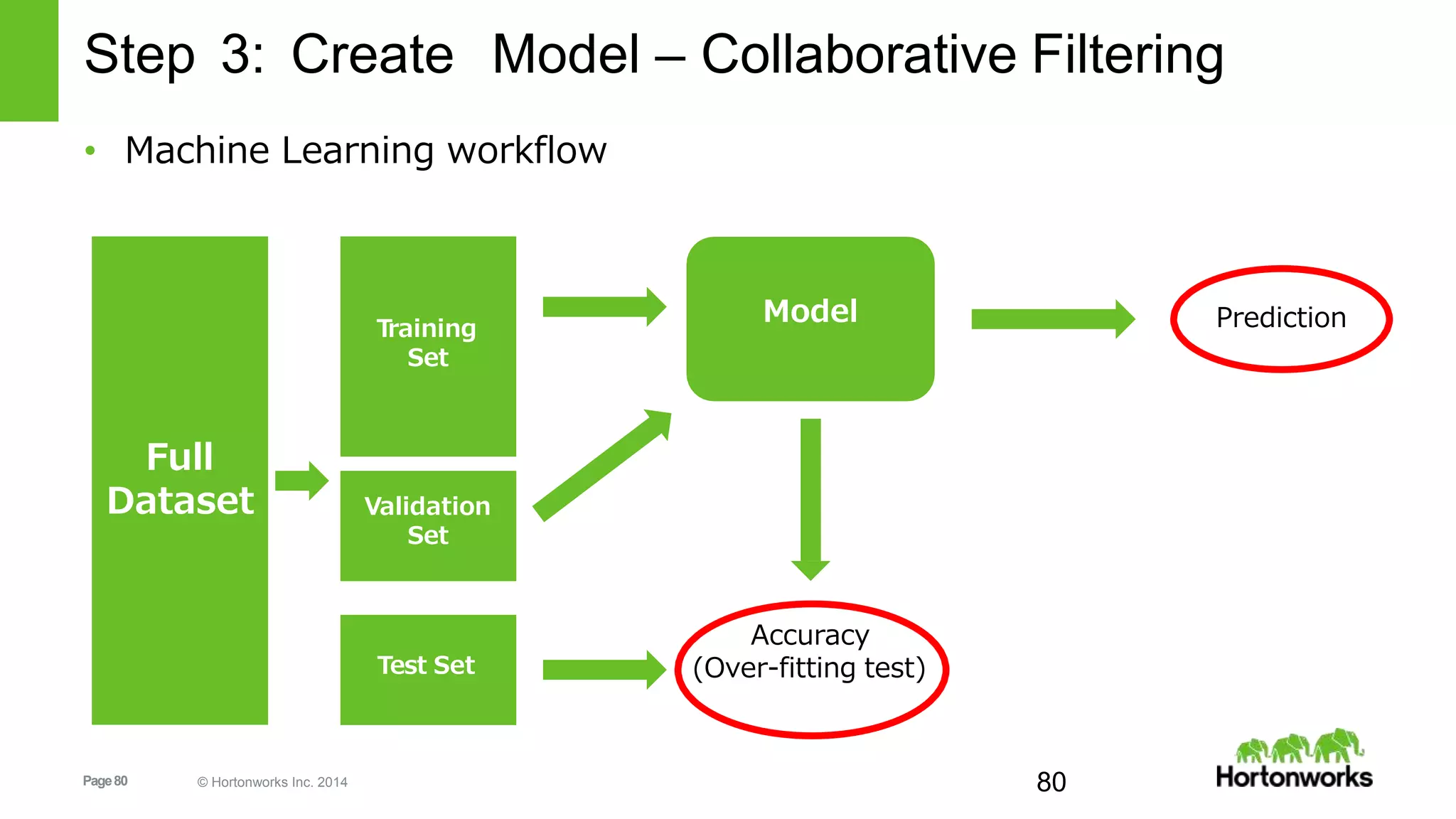
![Page81 © Hortonworks Inc. 2014
Step 3: Create Model – Collaborative Filtering
• Randomly split the dataset we have in multiple groups for training,
validating and testing using randomSplit(weights, seed=None)
trainingRDD, validationRDD, testRDD =
ratingsRDD.randomSplit([6, 2, 2], seed=0L)
print 'Training: %s, validation: %s, test: %sn' %
trainingRDD.count(),
validationRDD.count(),
testRDD.count())
Training: 292716, validation: 96902, test: 98032](https://image.slidesharecdn.com/sparkrecommendationdeckzeltov-160318135534/75/Spark-Advanced-Analytics-NJ-Data-Science-Meetup-Princeton-University-81-2048.jpg)





![Page87 © Hortonworks Inc. 2014
Step 3: Create Model – Collaborative Filtering
from pyspark.mllib.recommendation import ALS
validationForPredictRDD = ( validationRDD
.map(lambda (UserID, MovieID, Rating): (UserID, MovieID))
ranks = [4, 8, 12]
errors = [0, 0
,
0]
err = 0
minError = float('inf')
bestRank = -1bestIteration = -1
• Import the ALS module, create the “empty” validatio RDD for prediction and set up some
variables](https://image.slidesharecdn.com/sparkrecommendationdeckzeltov-160318135534/75/Spark-Advanced-Analytics-NJ-Data-Science-Meetup-Princeton-University-87-2048.jpg)
![Page88 © Hortonworks Inc. 2014
Step 3: Create Model – Collaborative Filtering
for rank in ranks:
model = ALS.train( trainingRDD, rank, seed=5L,
iterations=5, lambda_=0.1)
predictedRatingsRDD =
model.predictAll(validationForPredictRDD)
error = computeError(predictedRatingsRDD, validationRDD)
errors[err] = error
err += 1
print 'For rank %s the RMSE is %s' % (rank, error)
minError:if error <
minError
bestRank
= error
= rank](https://image.slidesharecdn.com/sparkrecommendationdeckzeltov-160318135534/75/Spark-Advanced-Analytics-NJ-Data-Science-Meetup-Princeton-University-88-2048.jpg)




![Page93 © Hortonworks Inc. 2014
Step 5: Use the model
• Let’s get some movie predictions!
• First I need to give the data set some ratings so it has something to deduce my taste
myRatedMovies = [ # Rating
(0, 845,5.0), # Blade Runner (1982) - 5.0/5
(0, 789,4.5), # Good Will Hunting (1997) - 4.5/5
(0, 983,4.8), # Christmas Story, A (1983) - 4.8/5
(0, 551,2.0), # Taxi Driver (1976) - 2.0/5
(0,1039,2.0), # Pulp Fiction (1994) - 2.0/5
(0, 651,5.0), # Dr. Strangelove (1963) - 5.0/5
(0,1195,4.0), # Raiders of the Lost Ark (1981) - 4.0/5
(0,1110,5.0), # Sixth Sense, The (1999) - 4.5/5
(0,1250,4.5), # Matrix, The (1999) - 4.5/5
- 4.0/5(0,1083,4.0) # Princess Bride, The (1987)
]
myRatingsRDD = sc.parallelize(myRatedMovies)](https://image.slidesharecdn.com/sparkrecommendationdeckzeltov-160318135534/75/Spark-Advanced-Analytics-NJ-Data-Science-Meetup-Princeton-University-93-2048.jpg)


![Page96 © Hortonworks Inc. 2014
Step 5: Use the model
• Now we need an RDD with only the movies I did not rate, to run
predictAll() on. (my userid is set to zero)
• [(0, movieID1), (0, movieID2), (0, movieID3), …]
myUnratedMoviesRDD = (moviesRDD
.map(lambda (movieID, name): movieID)
.filter(lambda movieID:
in myRatedMovies] )movieID not in [ mine[1] for mine
.map(lambda movieID: (0, movieID)))
predictedRatingsRDD =
myRatingsModel.predictAll(myUnratedMoviesRDD)](https://image.slidesharecdn.com/sparkrecommendationdeckzeltov-160318135534/75/Spark-Advanced-Analytics-NJ-Data-Science-Meetup-Princeton-University-96-2048.jpg)


![Page99 © Hortonworks Inc. 2014
Step 5: Use the model
• And finally get the top 20 recommended movies for myself
predictedHighestRatedMovies =
ratingsWithNamesRDD.takeOrdered(20, key=lambda x: -x[0])
print ('My highest rated movies as predictedn%s' %
'n'.join(map(str, predictedHighestRatedMovies)))](https://image.slidesharecdn.com/sparkrecommendationdeckzeltov-160318135534/75/Spark-Advanced-Analytics-NJ-Data-Science-Meetup-Princeton-University-99-2048.jpg)

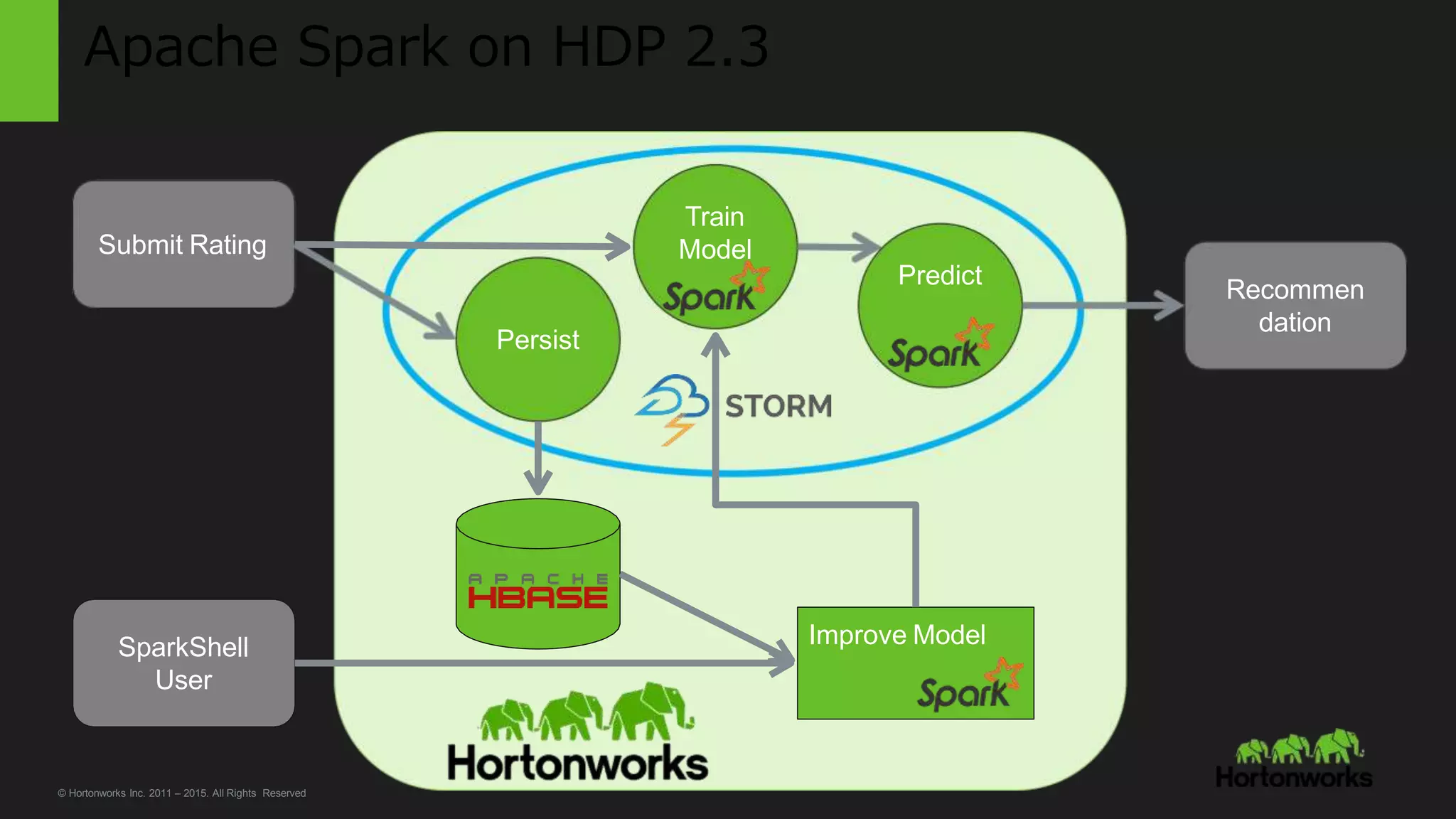



This document covers a workshop on advanced analytics using Apache Spark and Apache Zeppelin within the Hortonworks Data Platform (HDP). It details Spark's capabilities, including data processing, machine learning, and SQL querying, as well as the integration of Zeppelin for interactive analytics. The content also provides insights into deploying Spark applications, using RDDs and DataFrames, and performing data transformations and actions.























































































