Download as PDF, PPTX















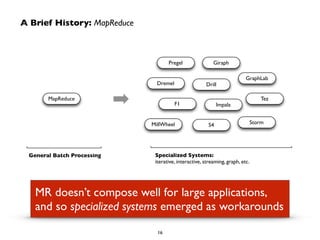
















The document outlines details for a series of events and training sessions focused on Apache Spark, including hands-on tutorials, talks from Spark experts, and a certification for developers. It highlights the growth and evolution of Spark, its components, use cases, and the community's efforts to adapt and enhance the platform for broader applications. Keynotes, workshops, and resources for participants are also mentioned, emphasizing the growing demand for Spark expertise in the big data landscape.






















































































