Downloaded 34 times









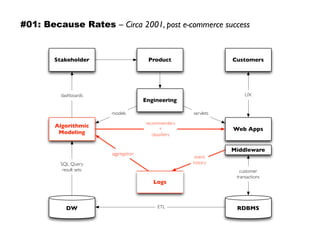





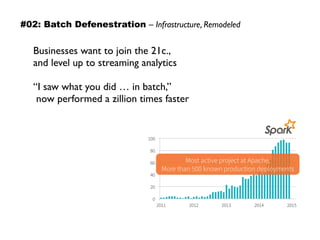
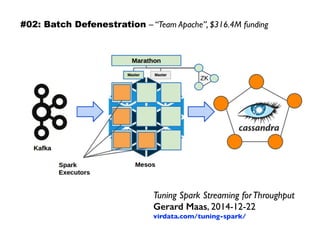
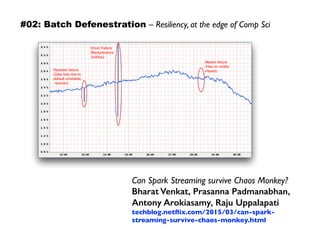







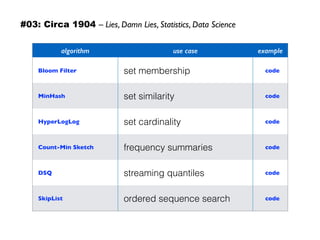



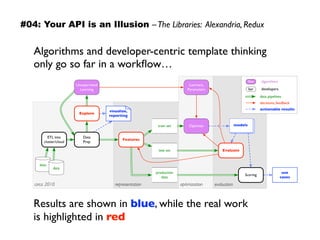









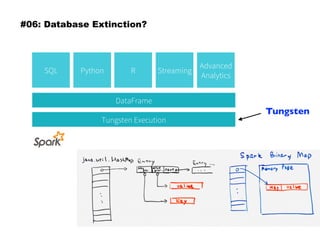



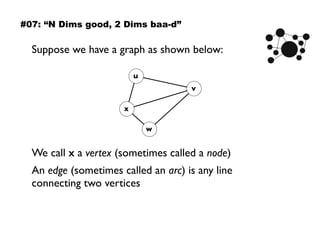
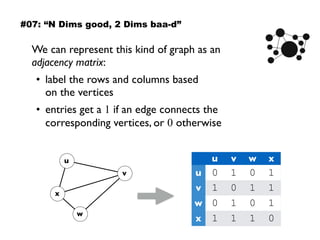
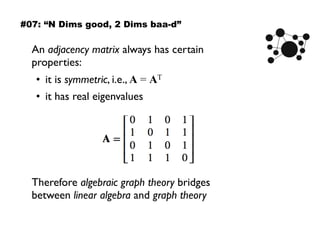


























The document discusses eleven almost-truisms about data to consider when entering data science, focusing on the realities that differ from common preconceptions. It covers topics such as the rapid evolution of data rates, the transition from batch to streaming analytics, the implications of database management, multidimensional thinking in data representation, and the interdisciplinary nature of data science. Additionally, it emphasizes the importance of learning curves and the need for data teams to adapt and innovate continuously.



























































































