Download as PDF, PPTX









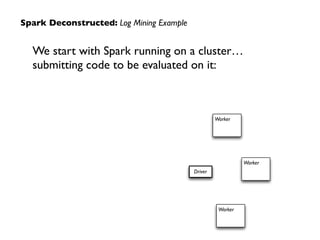

![Spark Deconstructed: Log Mining Example
scala> messages.toDebugString!
res5: String = !
MappedRDD[4] at map at <console>:16 (3 partitions)!
MappedRDD[3] at map at <console>:16 (3 partitions)!
FilteredRDD[2] at filter at <console>:14 (3 partitions)!
MappedRDD[1] at textFile at <console>:12 (3 partitions)!
HadoopRDD[0] at textFile at <console>:12 (3 partitions)
At this point, take a look at the transformed
RDD operator graph:](https://image.slidesharecdn.com/ddtxsession-150110141104-conversion-gate01/85/Microservices-Containers-and-Machine-Learning-11-320.jpg)







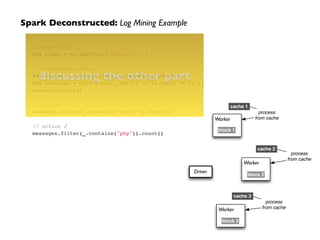




![// http://spark.apache.org/docs/latest/graphx-programming-guide.html!
!
import org.apache.spark.graphx._!
import org.apache.spark.rdd.RDD!
!
case class Peep(name: String, age: Int)!
!
val nodeArray = Array(!
(1L, Peep("Kim", 23)), (2L, Peep("Pat", 31)),!
(3L, Peep("Chris", 52)), (4L, Peep("Kelly", 39)),!
(5L, Peep("Leslie", 45))!
)!
val edgeArray = Array(!
Edge(2L, 1L, 7), Edge(2L, 4L, 2),!
Edge(3L, 2L, 4), Edge(3L, 5L, 3),!
Edge(4L, 1L, 1), Edge(5L, 3L, 9)!
)!
!
val nodeRDD: RDD[(Long, Peep)] = sc.parallelize(nodeArray)!
val edgeRDD: RDD[Edge[Int]] = sc.parallelize(edgeArray)!
val g: Graph[Peep, Int] = Graph(nodeRDD, edgeRDD)!
!
val results = g.triplets.filter(t => t.attr > 7)!
!
for (triplet <- results.collect) {!
println(s"${triplet.srcAttr.name} loves ${triplet.dstAttr.name}")!
}
GraphX: demo](https://image.slidesharecdn.com/ddtxsession-150110141104-conversion-gate01/85/Microservices-Containers-and-Machine-Learning-24-320.jpg)





![TextBlob
tag and
lemmatize
words
TextBlob
segment
sentences
TextBlob
sentiment
analysis
Py
generate
skip-grams
parsed
JSON
message
JSON Treebank,
WordNet
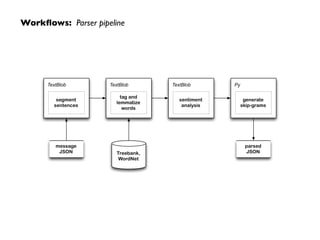
Workflows: Parser pipeline
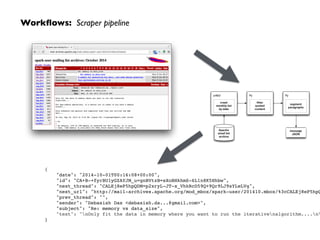
{!
"graf": [ [1, "Only", "only", "RB", 1, 0], [2, "fit", "fit", "VBP", 1, 1 ] ... ],!
"id": “CA+B-+fyrBU1yGZAYJM_u=gnBVtzB=sXoBHkhmS-6L1n8K5Hhbw",!
"polr": 0.2,!
"sha1": "178b7a57ec6168f20a8a4f705fb8b0b04e59eeb7",!
"size": 14,!
"subj": 0.7,!
"tile": [ [1, 2], [2, 3], [3, 4] ... ]!
]!
}
{!
"date": "2014-10-01T00:16:08+00:00",!
"id": "CA+B-+fyrBU1yGZAYJM_u=gnBVtzB=sXoBHkhmS-6L1n8K5Hhbw",!
"next_thread": "CALEj8eP5hpQDM=p2xryL-JT-x_VhkRcD59Q+9Qr9LJ9sYLeLVg",!
"next_url": "http://mail-archives.apache.org/mod_mbox/spark-user/201410.mbox/%3cCALEj8eP5hpQDM=p
"prev_thread": "",!
"sender": "Debasish Das <debasish.da...@gmail.com>",!
"subject": "Re: memory vs data_size",!
"text": "nOnly fit the data in memory where you want to run the iterativenalgorithm....nnFor
}](https://image.slidesharecdn.com/ddtxsession-150110141104-conversion-gate01/85/Microservices-Containers-and-Machine-Learning-36-320.jpg)
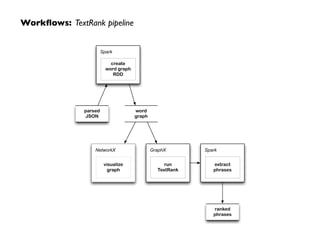
![Workflows: TextRank pipeline
"Compatibility of systems of linear constraints"
[{'index': 0, 'stem': 'compat', 'tag': 'NNP','word': 'compatibility'},
{'index': 1, 'stem': 'of', 'tag': 'IN', 'word': 'of'},
{'index': 2, 'stem': 'system', 'tag': 'NNS', 'word': 'systems'},
{'index': 3, 'stem': 'of', 'tag': 'IN', 'word': 'of'},
{'index': 4, 'stem': 'linear', 'tag': 'JJ', 'word': 'linear'},
{'index': 5, 'stem': 'constraint', 'tag': 'NNS','word': 'constraints'}]
compat
system
linear
constraint
1:
2:
3:
TextRank: Bringing Order intoTexts
Rada Mihalcea, Paul Tarau
http://web.eecs.umich.edu/~mihalcea/
papers/mihalcea.emnlp04.pdf](https://image.slidesharecdn.com/ddtxsession-150110141104-conversion-gate01/85/Microservices-Containers-and-Machine-Learning-38-320.jpg)


![TextRank impl: use SparkSQL to collect node list + edge list
val sql = """!
SELECT node_id, root !
FROM node !
WHERE id='%s' AND keep='1'!
""".format(msg_id)!
!
val n = sqlCtx.sql(sql.stripMargin).distinct()!
val nodes: RDD[(Long, String)] = n.map{ p =>!
(p(0).asInstanceOf[Int].toLong, p(1).asInstanceOf[String])!
}!
nodes.collect()!
!
val sql = """!
SELECT node0, node1 !
FROM edge !
WHERE id='%s'!
""".format(msg_id)!
!
val e = sqlCtx.sql(sql.stripMargin).distinct()!
val edges: RDD[Edge[Int]] = e.map{ p =>!
Edge(p(0).asInstanceOf[Int].toLong, p(1).asInstanceOf[Int].toLong, 0)!
}!
edges.collect()](https://image.slidesharecdn.com/ddtxsession-150110141104-conversion-gate01/85/Microservices-Containers-and-Machine-Learning-42-320.jpg)
![TextRank impl: use GraphX to run PageRank
// run PageRank!
val g: Graph[String, Int] = Graph(nodes, edges)!
val r = g.pageRank(0.0001).vertices!
!
r.join(nodes).sortBy(_._2._1, ascending=false).foreach(println)!
!
// save the ranks!
case class Rank(id: Int, rank: Float)!
val rank = r.map(p => Rank(p._1.toInt, p._2.toFloat))!
rank.registerTempTable("rank")!
!
def median[T](s: Seq[T])(implicit n: Fractional[T]) = {!
import n._!
val (lower, upper) = s.sortWith(_<_).splitAt(s.size / 2)!
if (s.size % 2 == 0) (lower.last + upper.head) / fromInt(2) else upper.head!
}!
!
val min_rank = median(r.map(_._2).collect())](https://image.slidesharecdn.com/ddtxsession-150110141104-conversion-gate01/85/Microservices-Containers-and-Machine-Learning-43-320.jpg)
![TextRank impl: join ranked words with parsed text
var span:List[String] = List()!
var last_index = -1!
var rank_sum = 0.0!
!
var phrases:collection.mutable.Map[String, Double] = collection.mutable.Map()!
!
val sql = """!
SELECT n.num, n.raw, r.rank!
FROM node n JOIN rank r ON n.node_id = r.id !
WHERE n.id='%s' AND n.keep='1'!
ORDER BY n.num!
""".format(msg_id)!
!
val s = sqlCtx.sql(sql.stripMargin).collect()](https://image.slidesharecdn.com/ddtxsession-150110141104-conversion-gate01/85/Microservices-Containers-and-Machine-Learning-44-320.jpg)

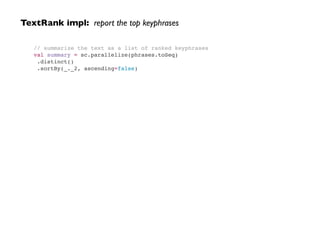


![Reply Graph: use SparkSQL to collect node list + edge list
val sql = "SELECT id, sender FROM node"!
val n = sqlCtx.sql(sql).distinct()!
val nodes: RDD[(Long, String)] = n.map{ p =>!
(p(0).asInstanceOf[Long], p(1).asInstanceOf[String])!
}!
nodes.collect()!
!
val sql = "SELECT replier, sender, num FROM edge"!
val e = sqlCtx.sql(sql).distinct()!
val edges: RDD[Edge[Int]] = e.map{ p =>!
Edge(p(0).asInstanceOf[Long], p(1).asInstanceOf[Long], p(2).asInstanceOf[Int])!
}!
edges.collect()](https://image.slidesharecdn.com/ddtxsession-150110141104-conversion-gate01/85/Microservices-Containers-and-Machine-Learning-49-320.jpg)
![Reply Graph: use GraphX to run graph analytics
// run graph analytics!
val g: Graph[String, Int] = Graph(nodes, edges)!
val r = g.pageRank(0.0001).vertices!
r.join(nodes).sortBy(_._2._1, ascending=false).foreach(println)!
!
// define a reduce operation to compute the highest degree vertex!
def max(a: (VertexId, Int), b: (VertexId, Int)): (VertexId, Int) = {!
if (a._2 > b._2) a else b!
}!
!
// compute the max degrees!
val maxInDegree: (VertexId, Int) = g.inDegrees.reduce(max)!
val maxOutDegree: (VertexId, Int) = g.outDegrees.reduce(max)!
val maxDegrees: (VertexId, Int) = g.degrees.reduce(max)!
!
// connected components!
val scc = g.stronglyConnectedComponents(10).vertices!
node.join(scc).foreach(println)](https://image.slidesharecdn.com/ddtxsession-150110141104-conversion-gate01/85/Microservices-Containers-and-Machine-Learning-50-320.jpg)

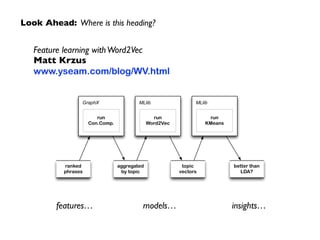









The document discusses the implementation of microservices, containers, and machine learning workflows using Apache Spark. It provides step-by-step instructions for downloading and setting up various components including Java JDK, Python, and Spark, along with detailed code examples for working with log data and graph analytics using Spark's GraphX API. Additionally, it covers topics related to ETL processes and the use of Docker for deploying Python-based services.






















































































