Downloaded 255 times








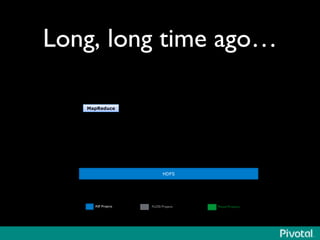
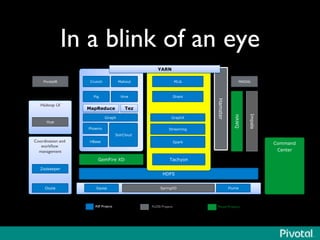
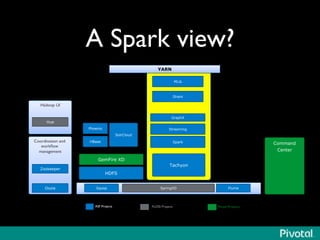
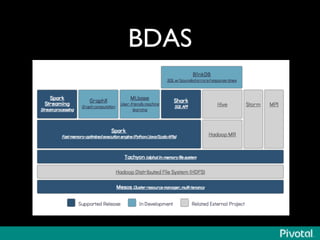



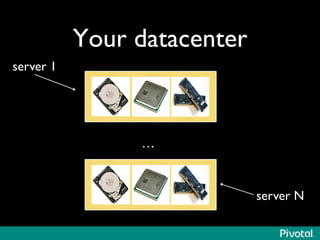
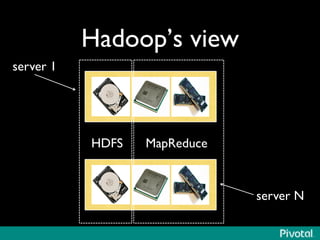
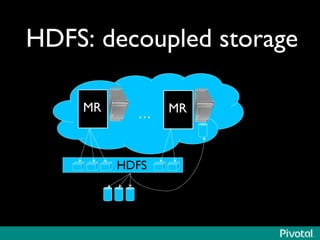

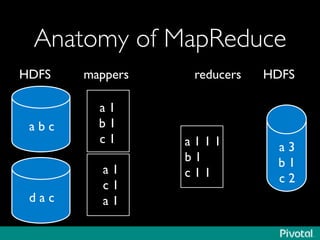
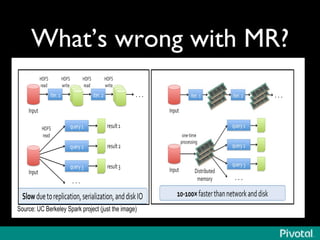


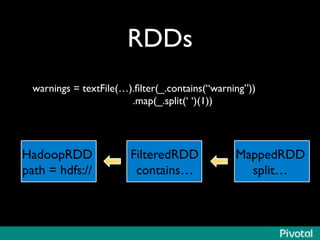





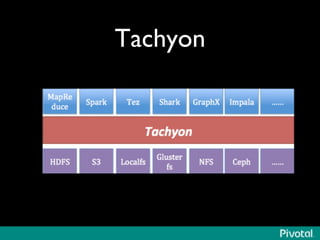






The document discusses the evolution of in-memory computing with a focus on Tachyon and Apache Spark, highlighting key innovations such as resilient distributed datasets (RDDs) that enhance data processing. It compares Hadoop's traditional MapReduce framework with Spark's capabilities and examines the role of Tachyon as an in-memory data-exchange layer, suggesting it is beneficial for cloud environments. Overall, it emphasizes the shift toward faster, iterative processing in big data applications.













































































![谷歌留痕技术教程[ 𝙩𝙤𝙥 𝟮𝟯𝟯. 𝙘 𝙤𝙢 ]](https://cdn.slidesharecdn.com/ss_thumbnails/top233-260130173900-2eb784f9-thumbnail.jpg?width=640&height=640&fit=bounds)


![20260201 [FOSDEM] gomodjail - library sandboxing for Go modules.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/20260201fosdemgomodjail-librarysandboxingforgomodules-260201225659-76609ec4-thumbnail.jpg?width=640&height=640&fit=bounds)







