Download as PDF, PPTX













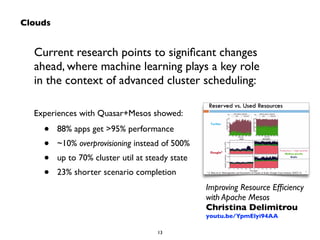


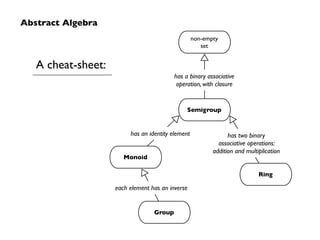



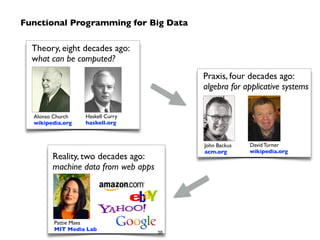


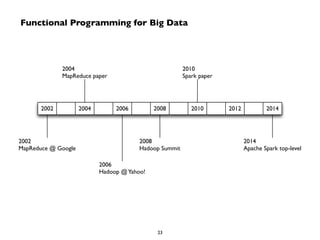
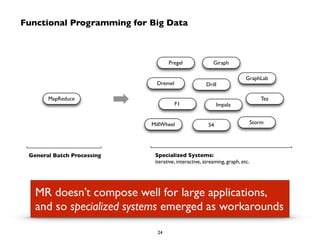





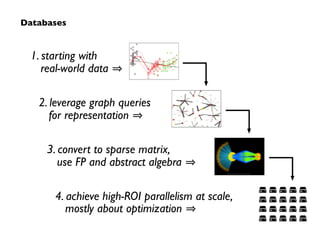





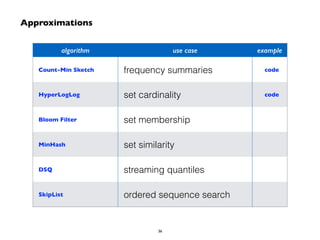








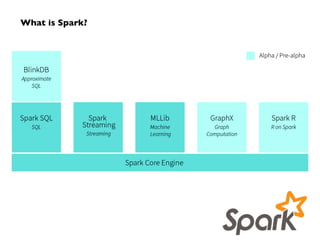


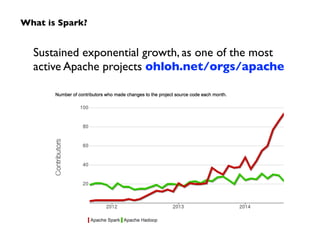


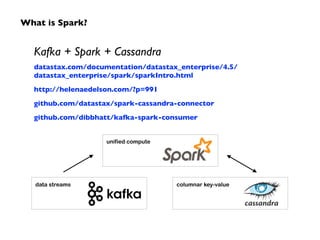
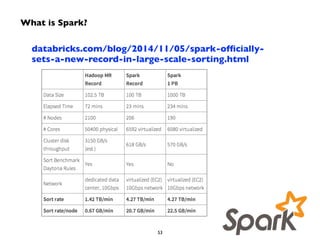








Big Data technologies are changing rapidly due to shifts in hardware, data types, and software frameworks. Incumbent Big Data technologies do not fully leverage newer hardware like multicore processors and large memory spaces, while newer open source projects like Spark have emerged to better utilize these resources. Containers, clouds, functional programming, databases, approximations, and notebooks represent significant trends in how Big Data is managed and analyzed at large scale.











































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)








