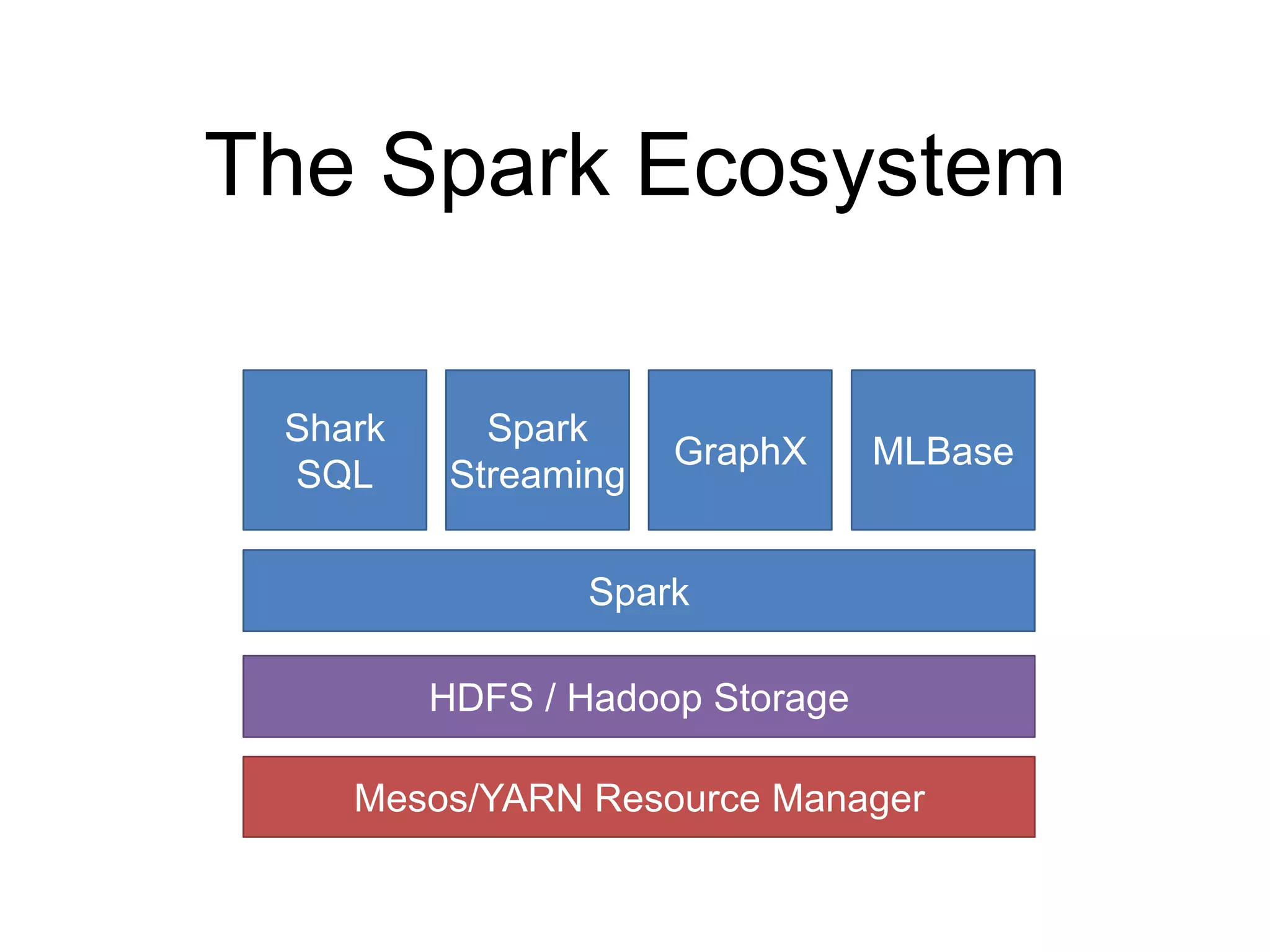
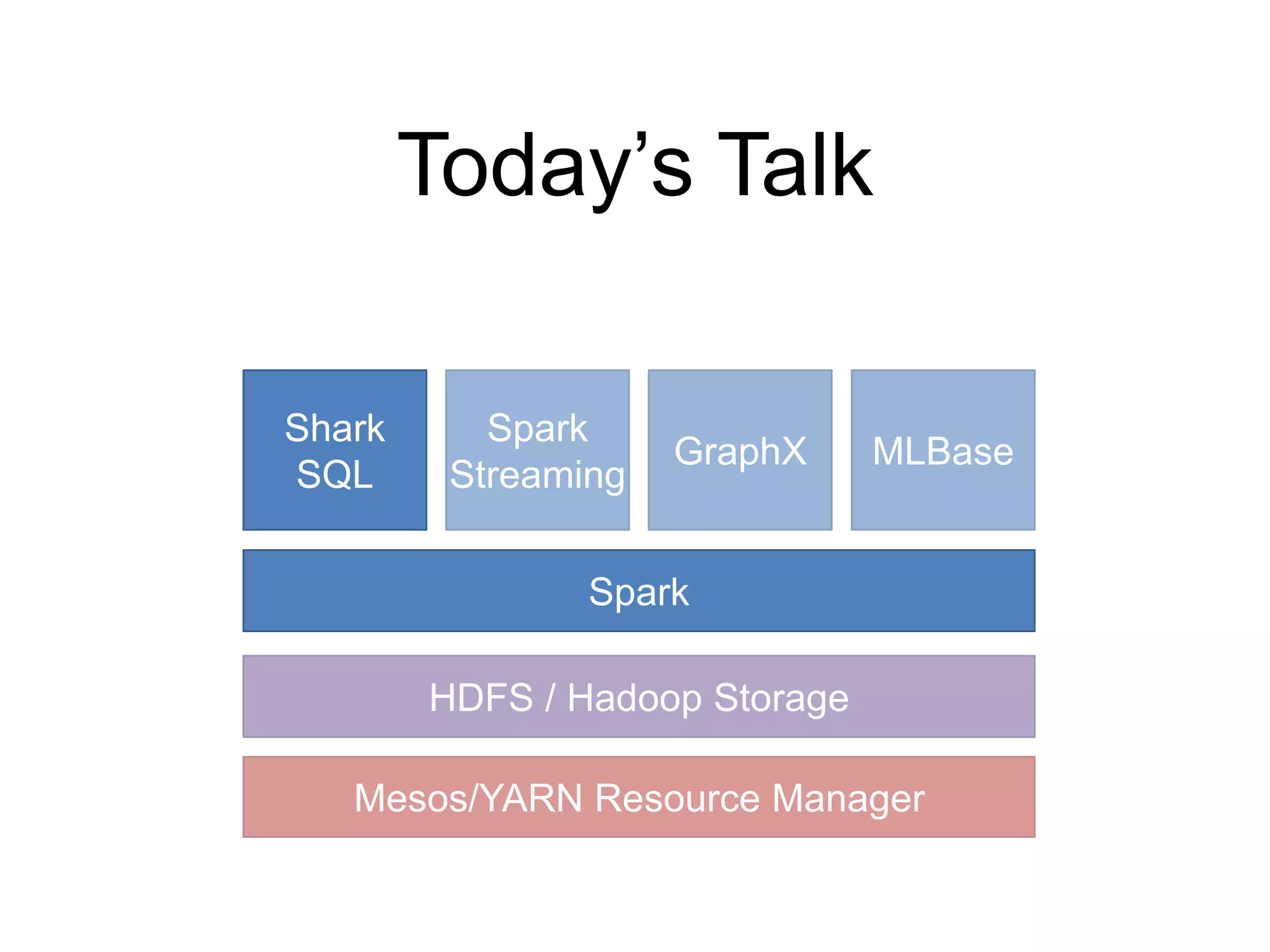
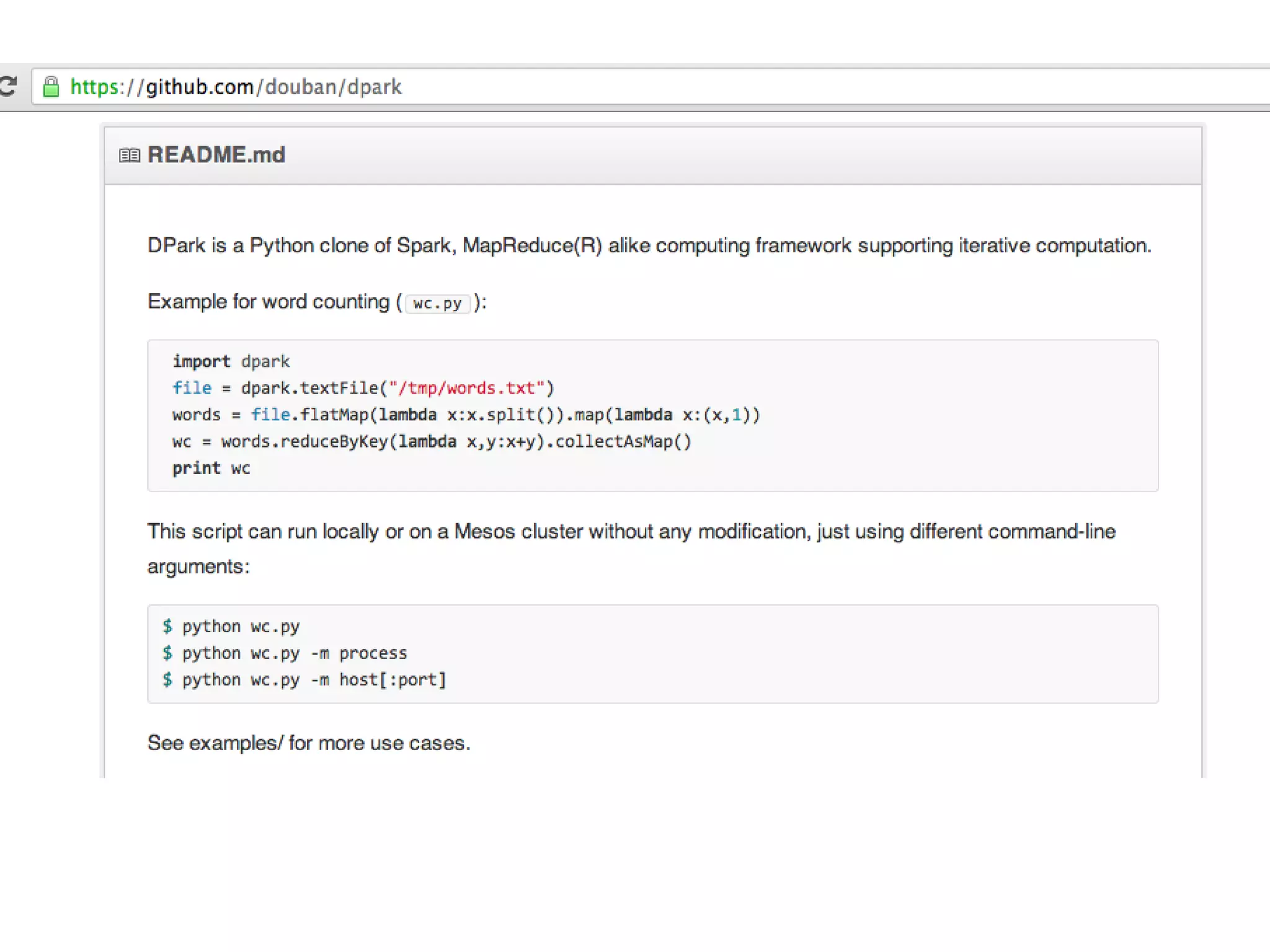
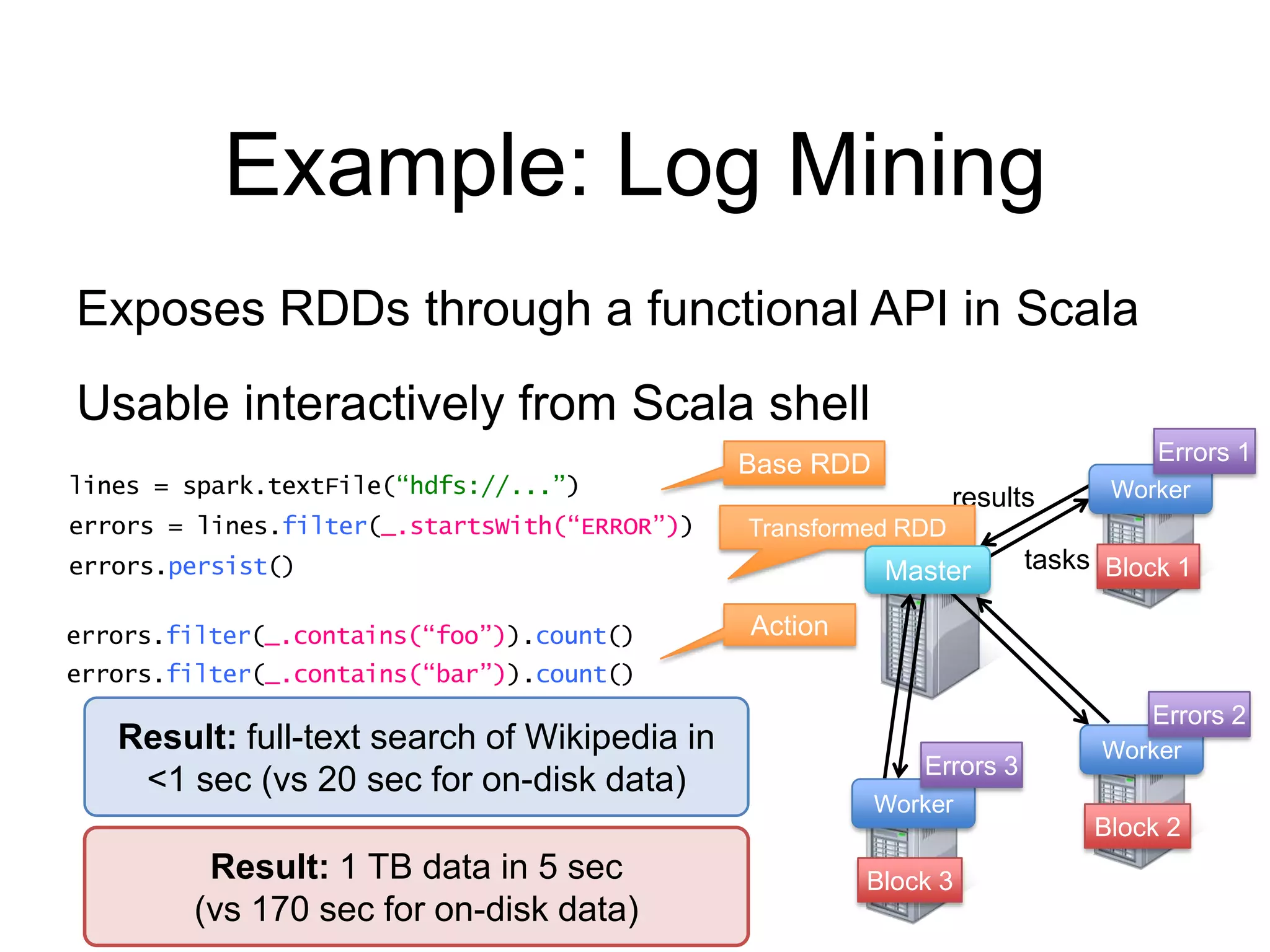
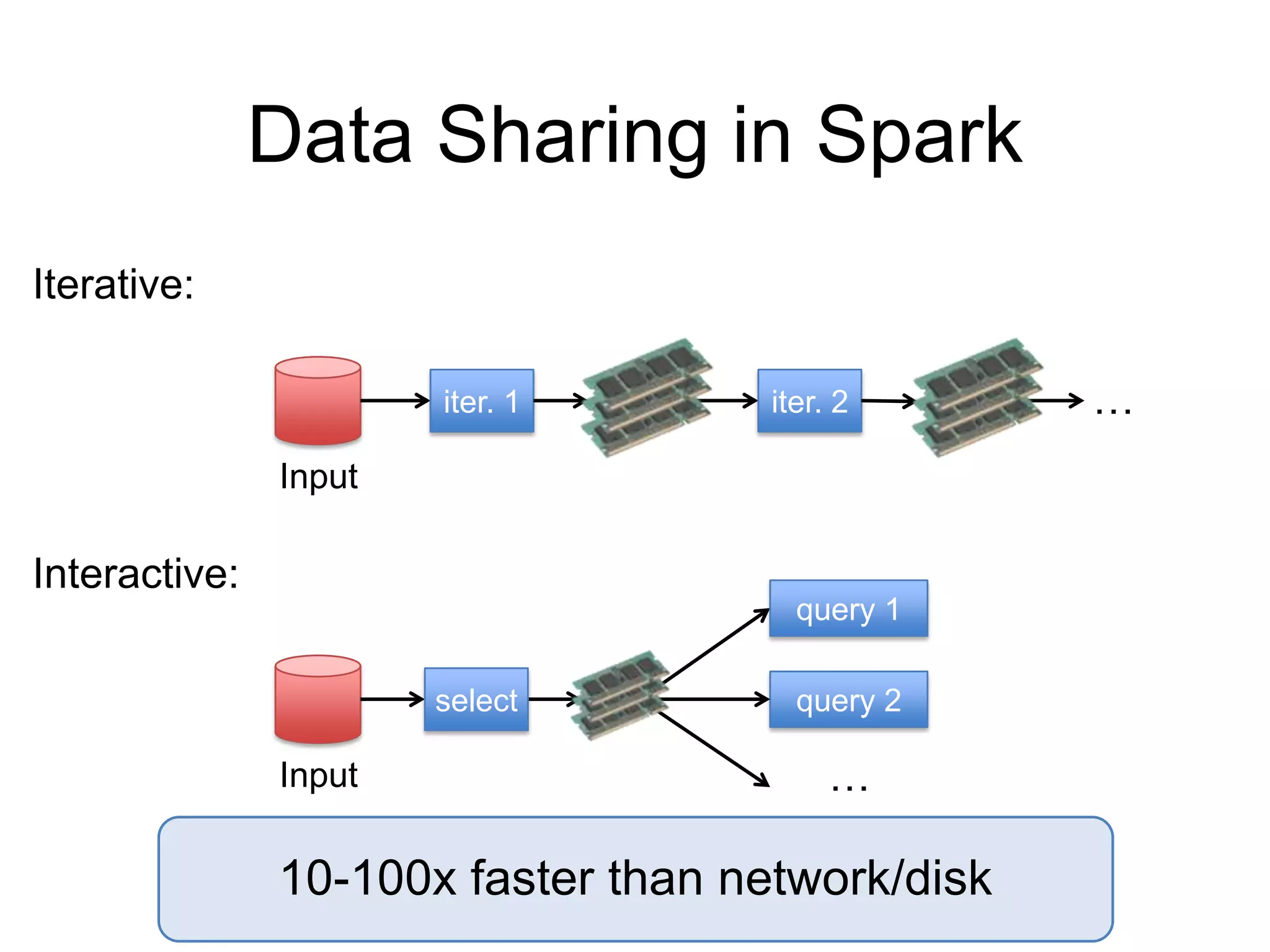
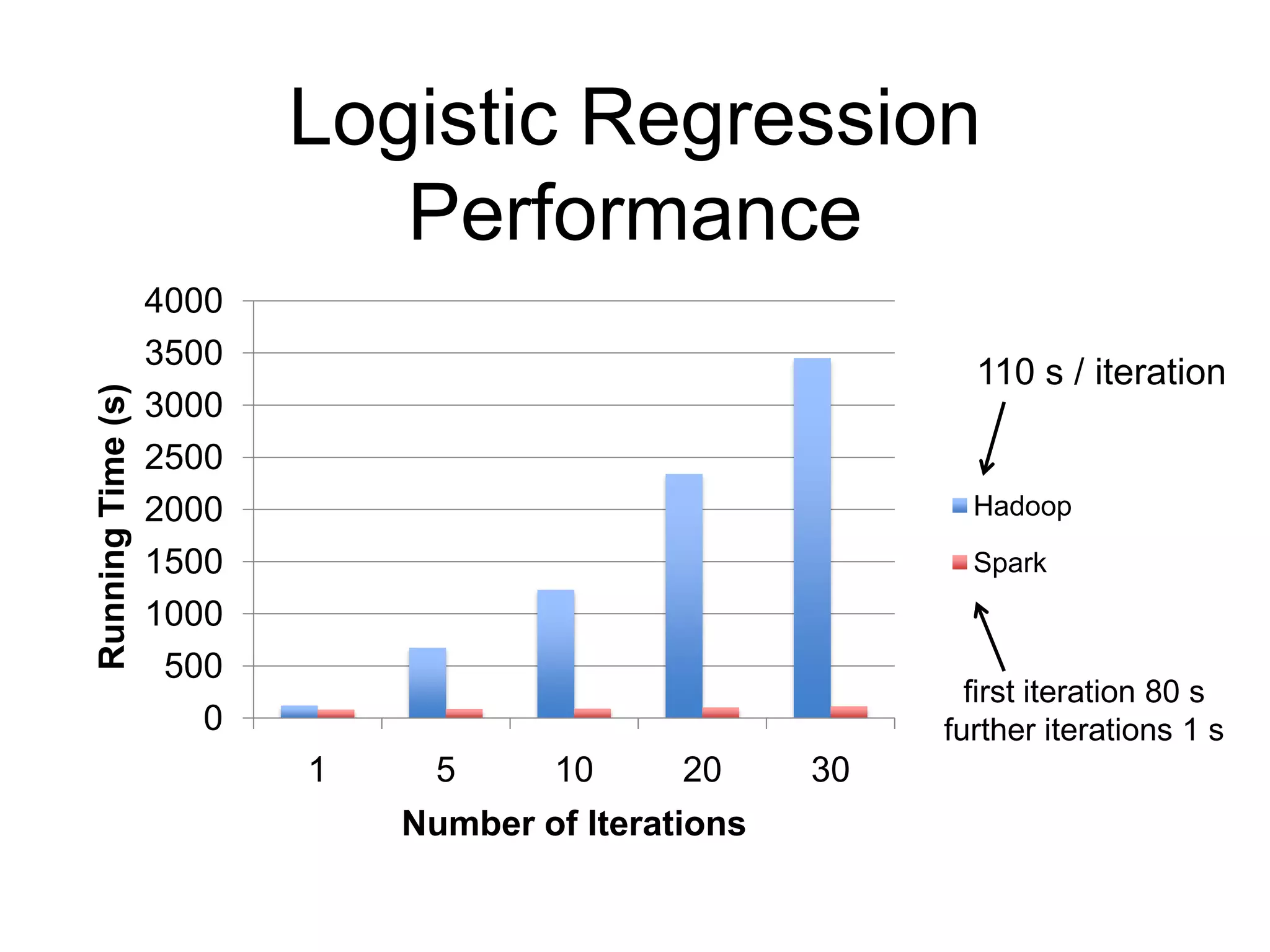
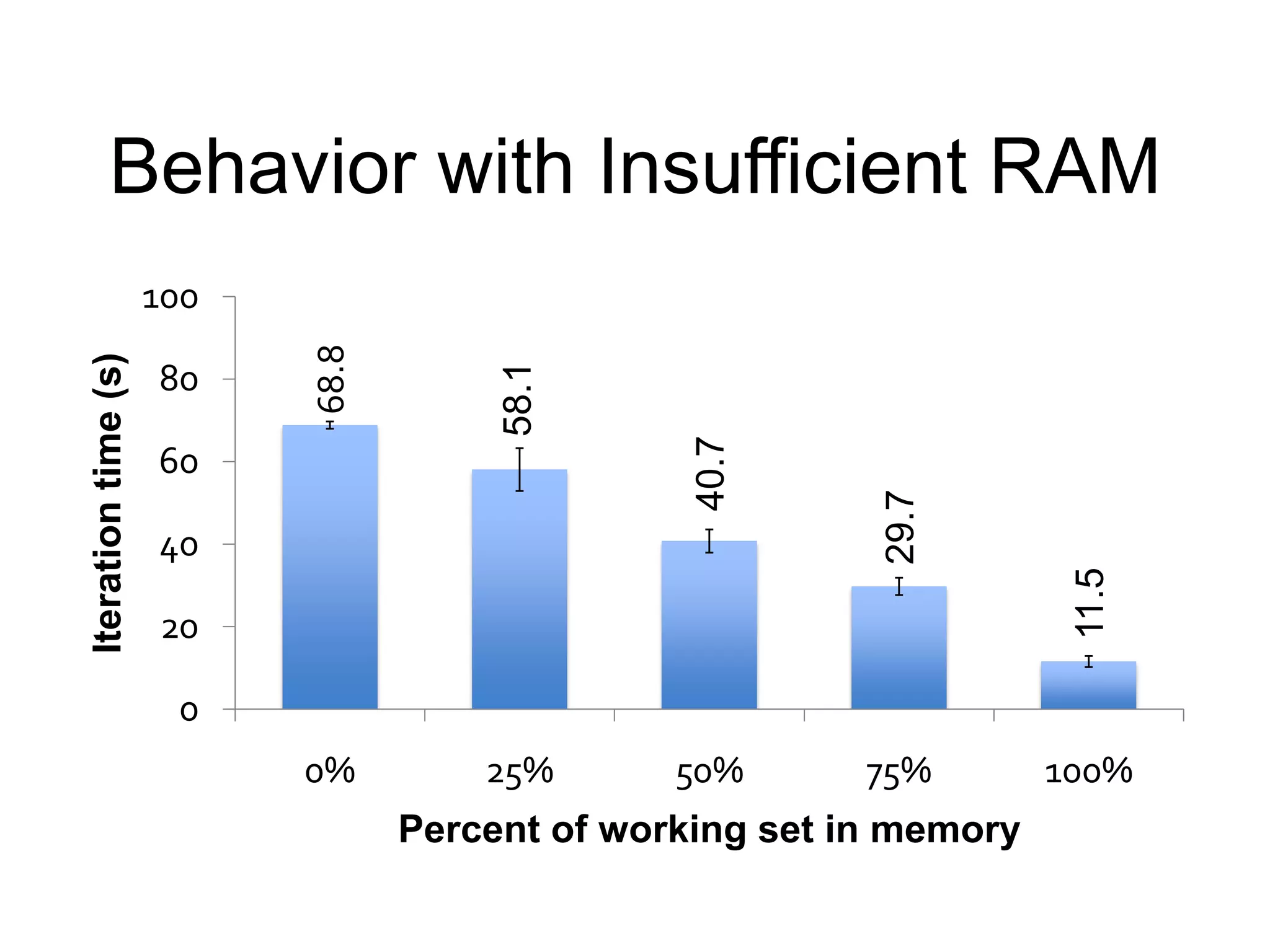
The document presents an overview of Spark and Shark, highlighting their capabilities for high-speed analytics over Hadoop data. Spark provides an efficient and expressive computing model with in-memory processing, while Shark offers a fast analytic query engine compatible with Hive. The document also discusses various features, programming interfaces, and performance comparisons with traditional Hadoop MapReduce.
















![Logistic Regression: Prep the Data
val sc = new SparkContext(“spark://master”, “LRExp”)
def loadDict(): Map[String, Double] = { … }
val dict = sc.broadcast( loadDict() )
def parser(s: String): (Array[Double], Double) = {
val parts = s.split(„t‟)
val y = parts(0).toDouble
val x = parts.drop(1).map(dict.getOrElse(_, 0.0))
(x, y)
}
val data = sc.textFile(“hdfs://d”).map(parser).cache()
Load data in memory once
Start a new Spark Session
Build a dictionary for file parsing
Broadcast the Dictionary to the Cluster
Line Parser which uses the Dictionary
23](https://image.slidesharecdn.com/20130912ytcreynoldxinsparkandshark-130917062125-phpapp02/75/20130912-YTC_Reynold-Xin_Spark-and-Shark-22-2048.jpg)
![Logistic Regression: Grad. Desc.
val sc = new SparkContext(“spark://master”, “LRExp”)
// Parsing …
val data: Spark.RDD[(Array[Double],Double)] = …
var w = Vector.random(D)
val lambda = 1.0/data.count
for (i <- 1 to ITERATIONS) {
val gradient = data.map {
case (x, y) => (1.0/(1+exp(-y*(w dot x)))–1)*y*x
}.reduce( (g1, g2) => g1 + g2 )
w -= (lambda / sqrt(i) ) * gradient
}
Initial parameter vector
Iterate
Set Learning Rate
Apply Gradient on Master
Compute Gradient Using
Map & Reduce
24](https://image.slidesharecdn.com/20130912ytcreynoldxinsparkandshark-130917062125-phpapp02/75/20130912-YTC_Reynold-Xin_Spark-and-Shark-23-2048.jpg)

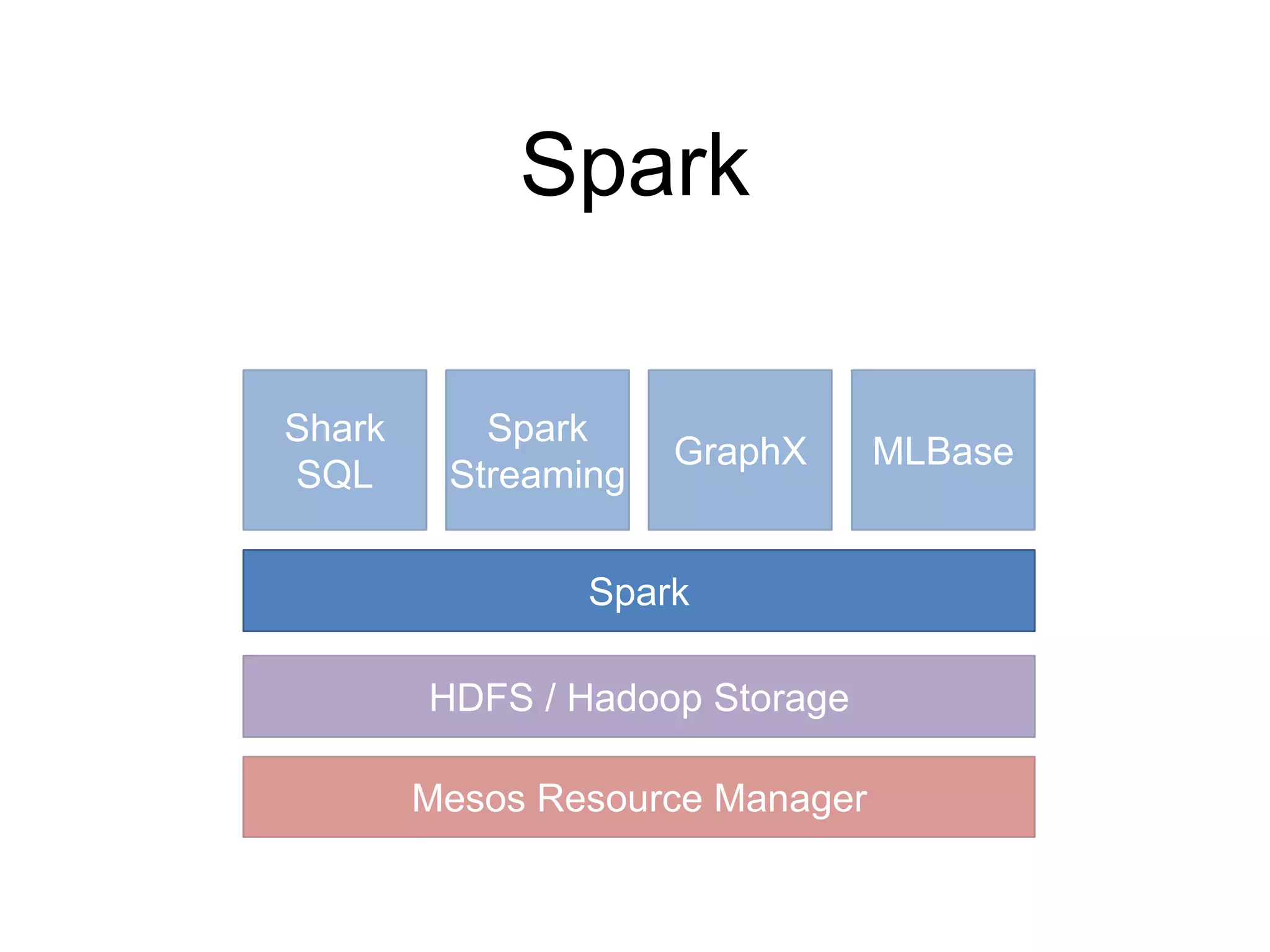







![Spark Integration
Unified system for query
processing and Spark
analytics
Query processing and ML
share the same set of
workers and caches
def logRegress(points: RDD[Point]): Vector {
var w = Vector(D, _ => 2 * rand.nextDouble - 1)
for (i <- 1 to ITERATIONS) {
val gradient = points.map { p =>
val denom = 1 + exp(-p.y * (w dot p.x))
(1 / denom - 1) * p.y * p.x
}.reduce(_ + _)
w -= gradient
}
w
}
val users = sql2rdd("SELECT * FROM user u
JOIN comment c ON c.uid=u.uid")
val features = users.mapRows { row =>
new Vector(extractFeature1(row.getInt("age")),
extractFeature2(row.getStr("country")),
...)}
val trainedVector = logRegress(features.cache())](https://image.slidesharecdn.com/20130912ytcreynoldxinsparkandshark-130917062125-phpapp02/75/20130912-YTC_Reynold-Xin_Spark-and-Shark-34-2048.jpg)


































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)

![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)











