Downloaded 87 times




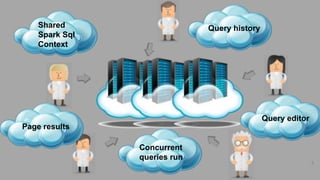


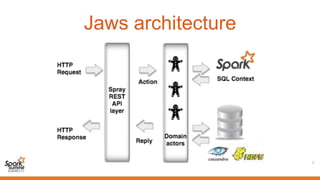
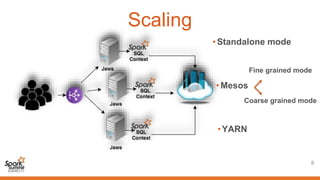








1) Jaws is a highly scalable and resilient data warehouse explorer that allows submitting Spark SQL queries concurrently and asynchronously through a RESTful API. 2) It provides features like persisted query logs, results pagination, and pluggable storage layers. Queries can be run on Spark SQL contexts configured to use data from HDFS, Cassandra, Parquet files on HDFS or Tachyon. 3) The architecture allows Jaws to scale on standalone, Mesos, or YARN clusters by distributing queries across multiple worker nodes, and supports canceling running queries.






































































































