Downloaded 26 times




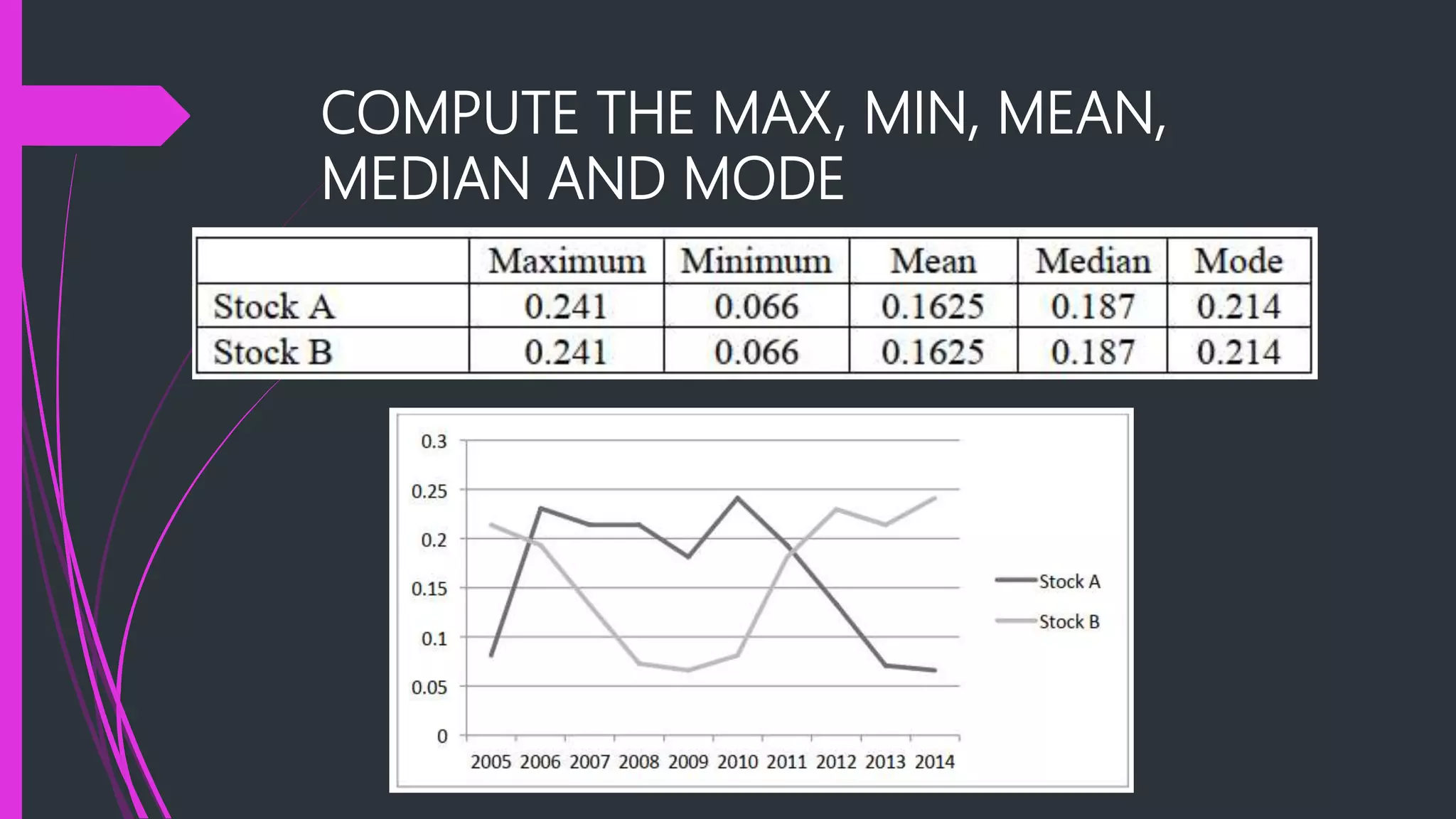









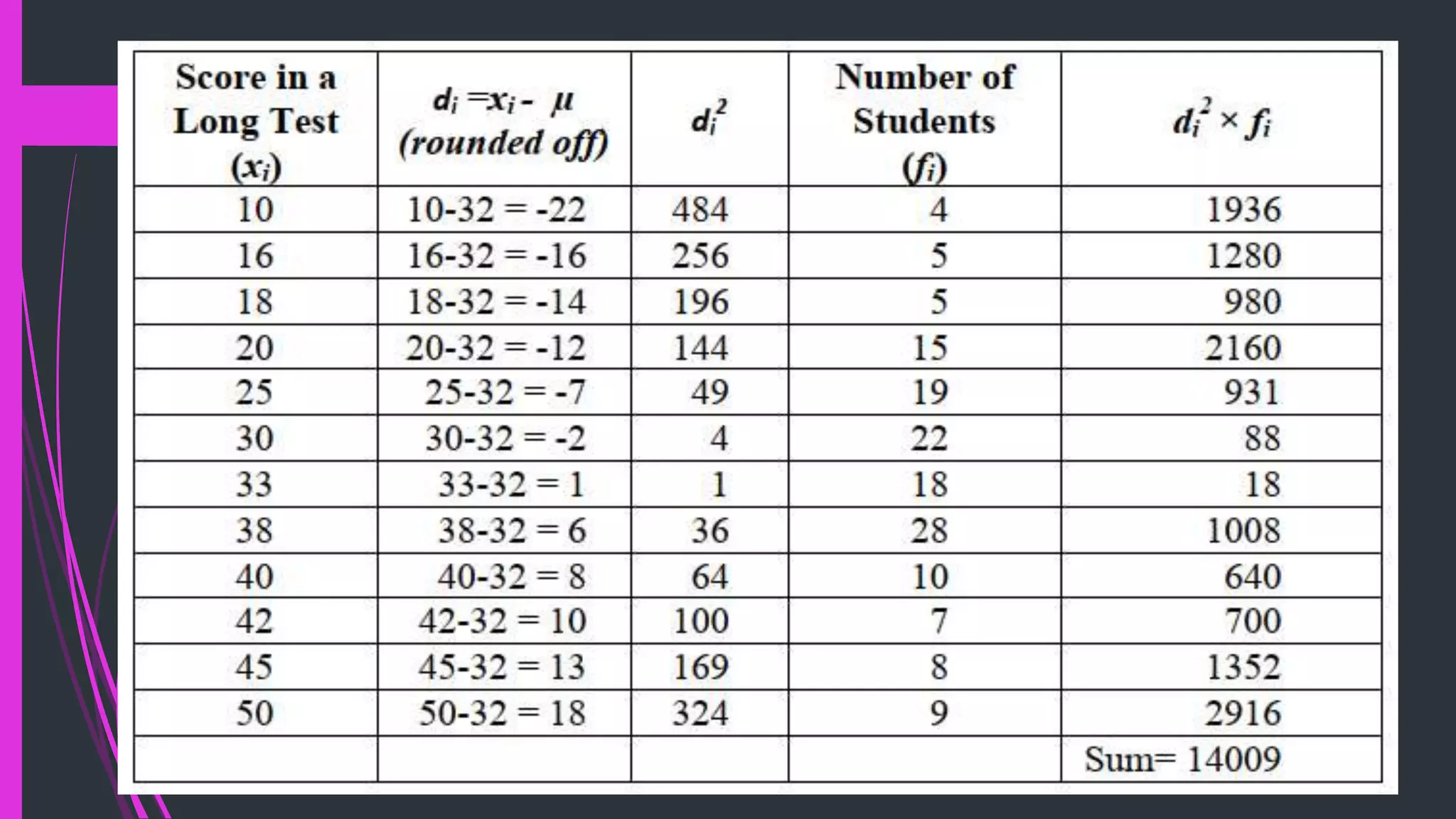










The document discusses measures of variation and dispersion in the context of learning outcomes and stock returns. It explains absolute measures (range, interquartile range, variance, and standard deviation) and relative measures (coefficient of variation) for evaluating data variability and investment risks. The importance of these measures is emphasized in providing a comprehensive understanding of data beyond just location measures.












































































