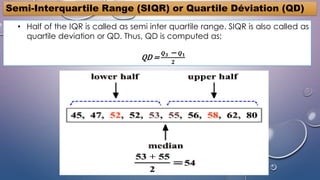
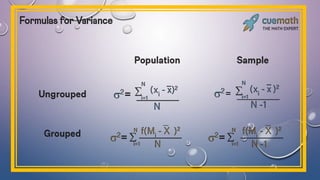
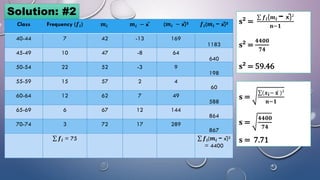
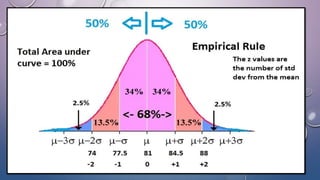
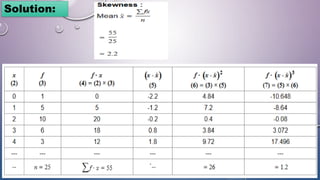
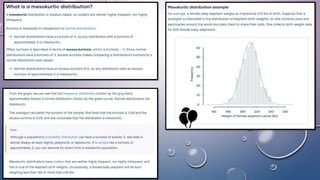
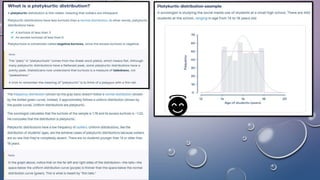
The document discusses various concepts related to variability and measures of dispersion in statistics:
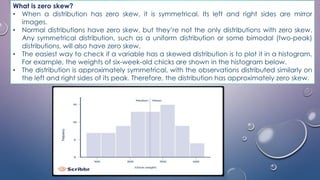
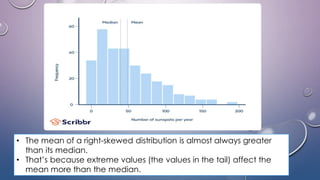
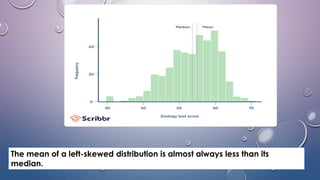
- Variability refers to the spread or deviation of scores from the mean in a data set. Measures of variability quantify how concentrated or dispersed the data is.
- Common measures of variability include range, quartile deviation, mean deviation, variance, standard deviation, and coefficient of variation. Range simply measures the highest and lowest scores while other measures account for dispersion across all scores.
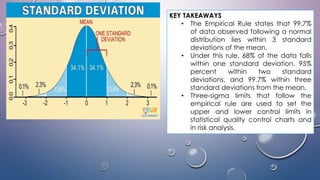
- The standard deviation is the most widely used measure of variability as it expresses dispersion in the same units as the original data. It quantifies how far scores deviate from the mean on average.
- Understanding variability is important for determining if averages