Download to read offline













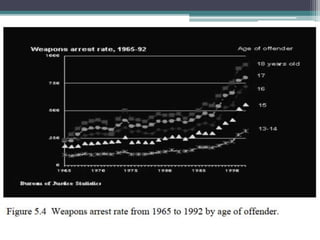













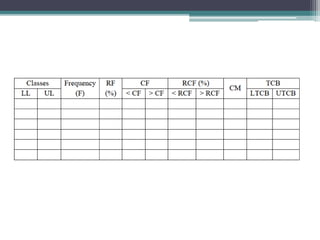





The document discusses three primary methods for presenting data: textual, tabular, and graphical, each suitable for specific contexts and types of data. It explains the components and construction techniques of frequency distribution tables (FDT) and highlights steps for creating grouped FDTs, including determining class intervals and tallying data. The importance of combining methods to effectively communicate data findings is emphasized throughout the material.












































































