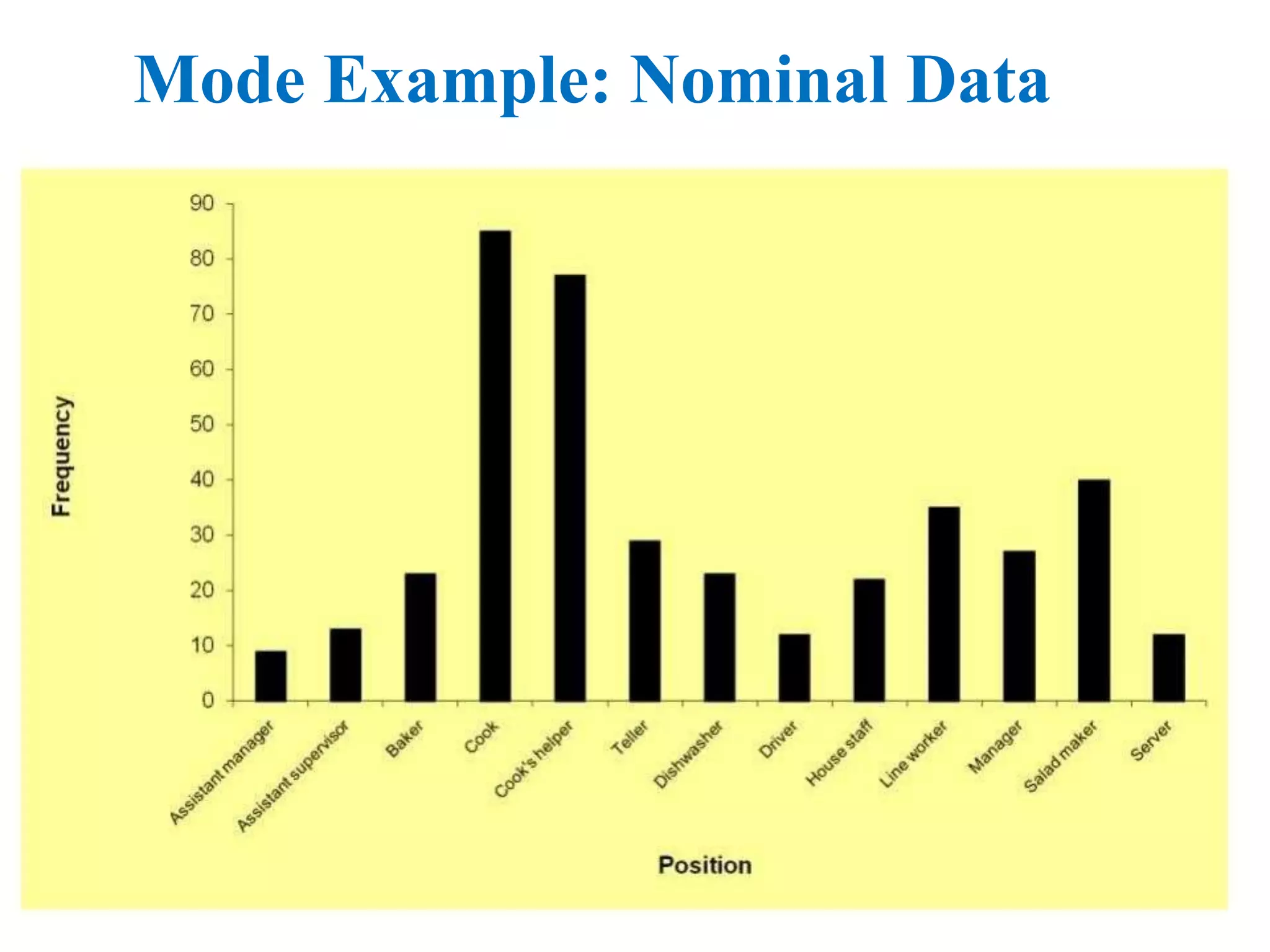
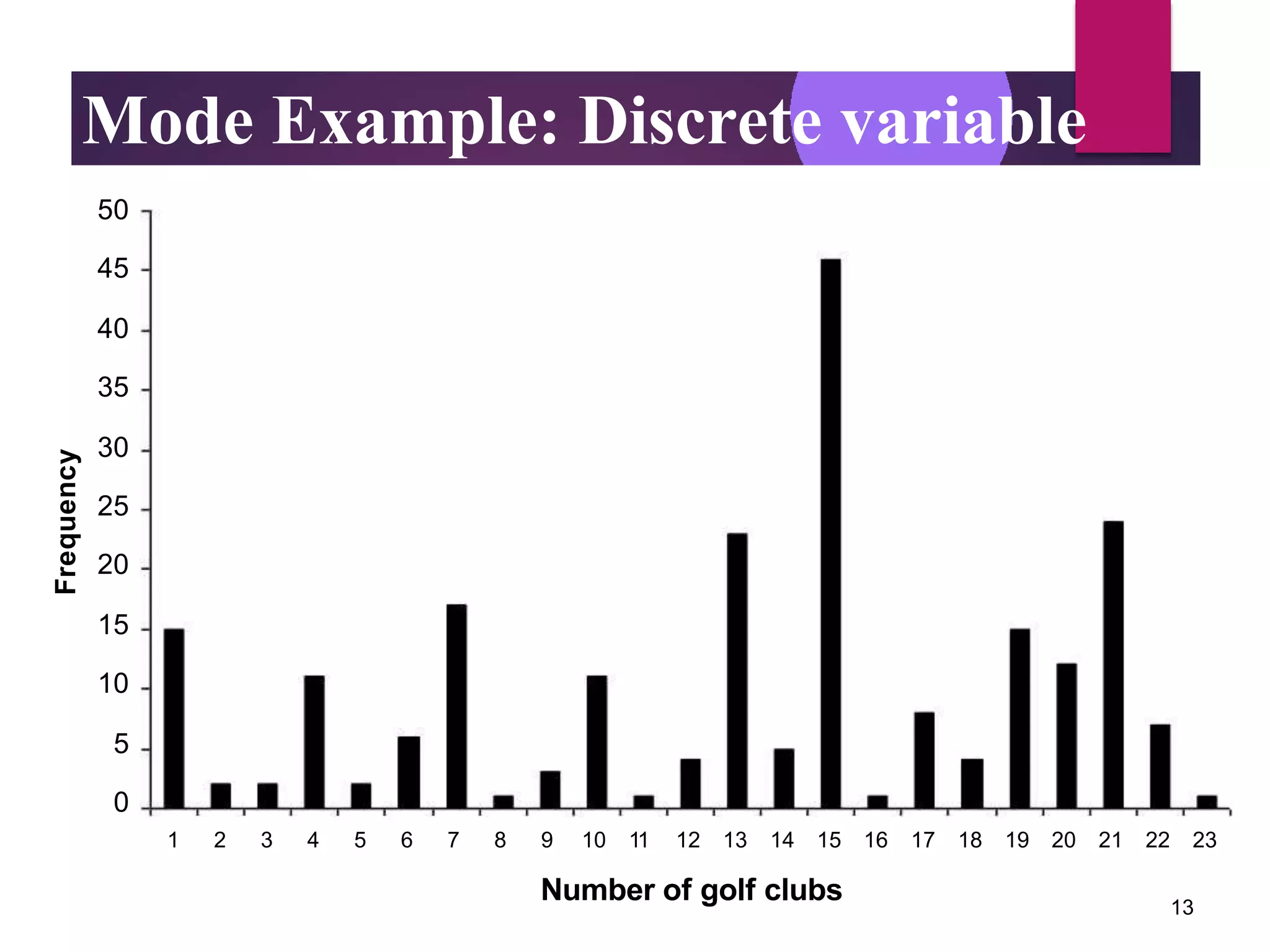
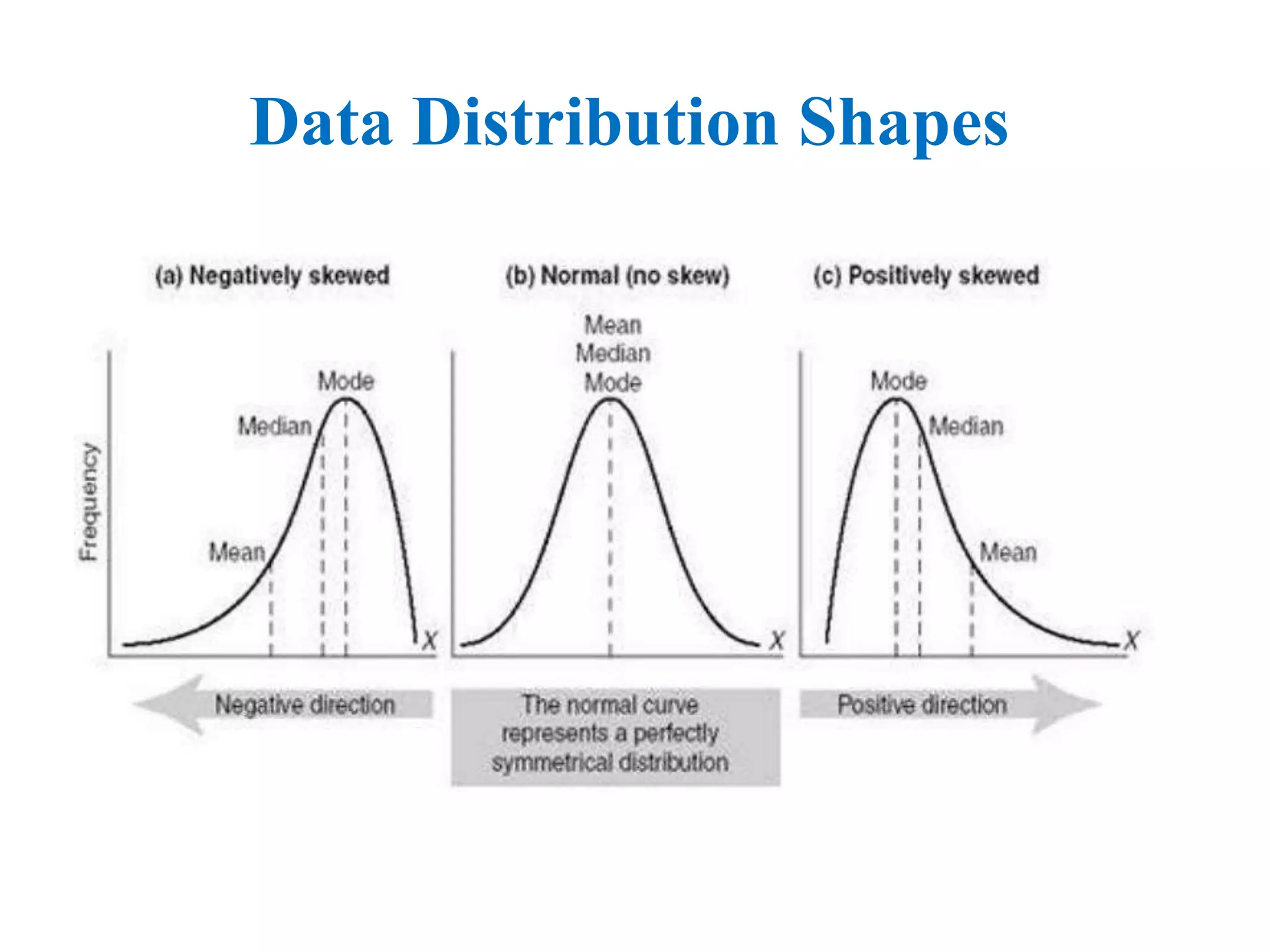
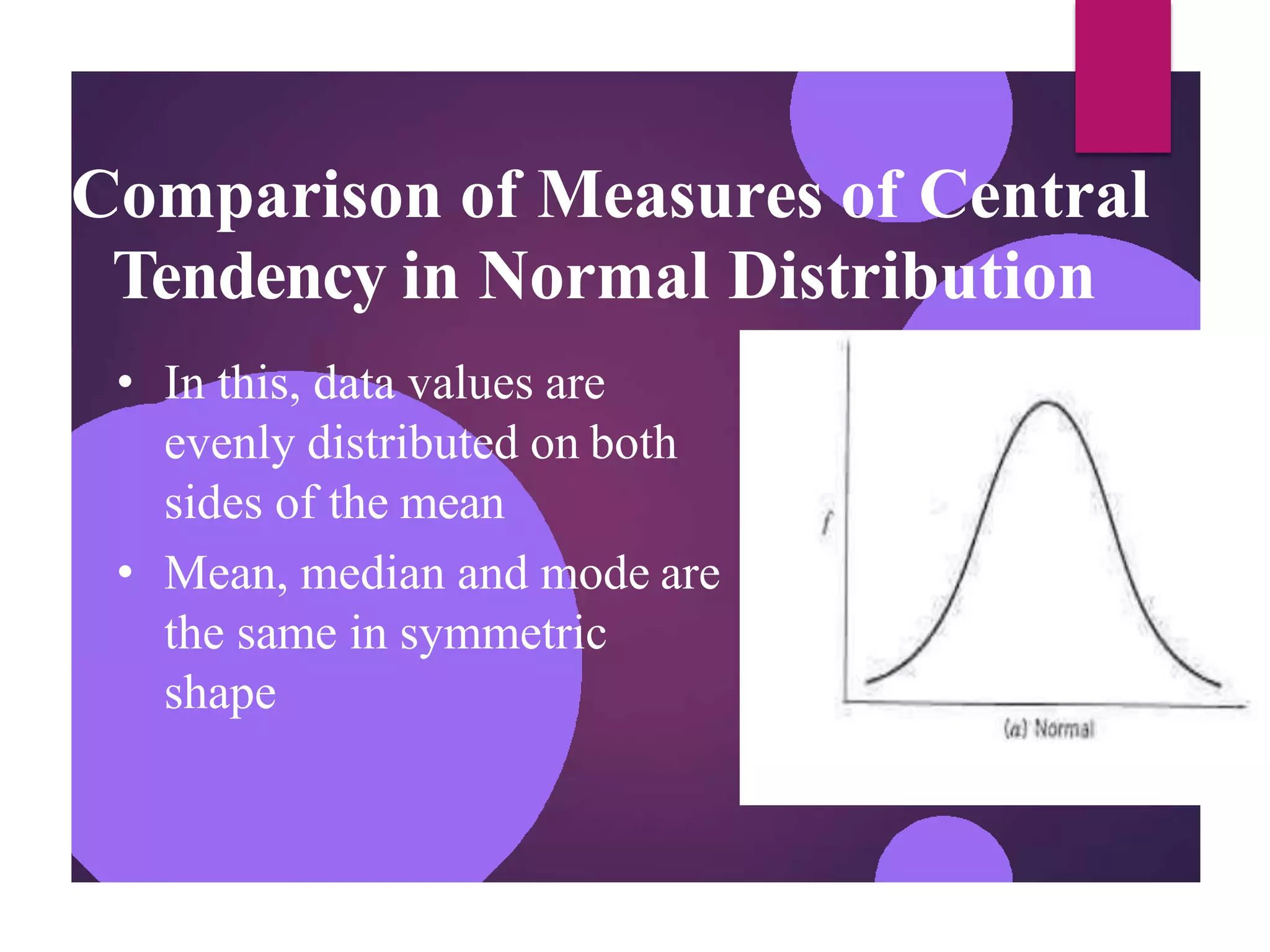
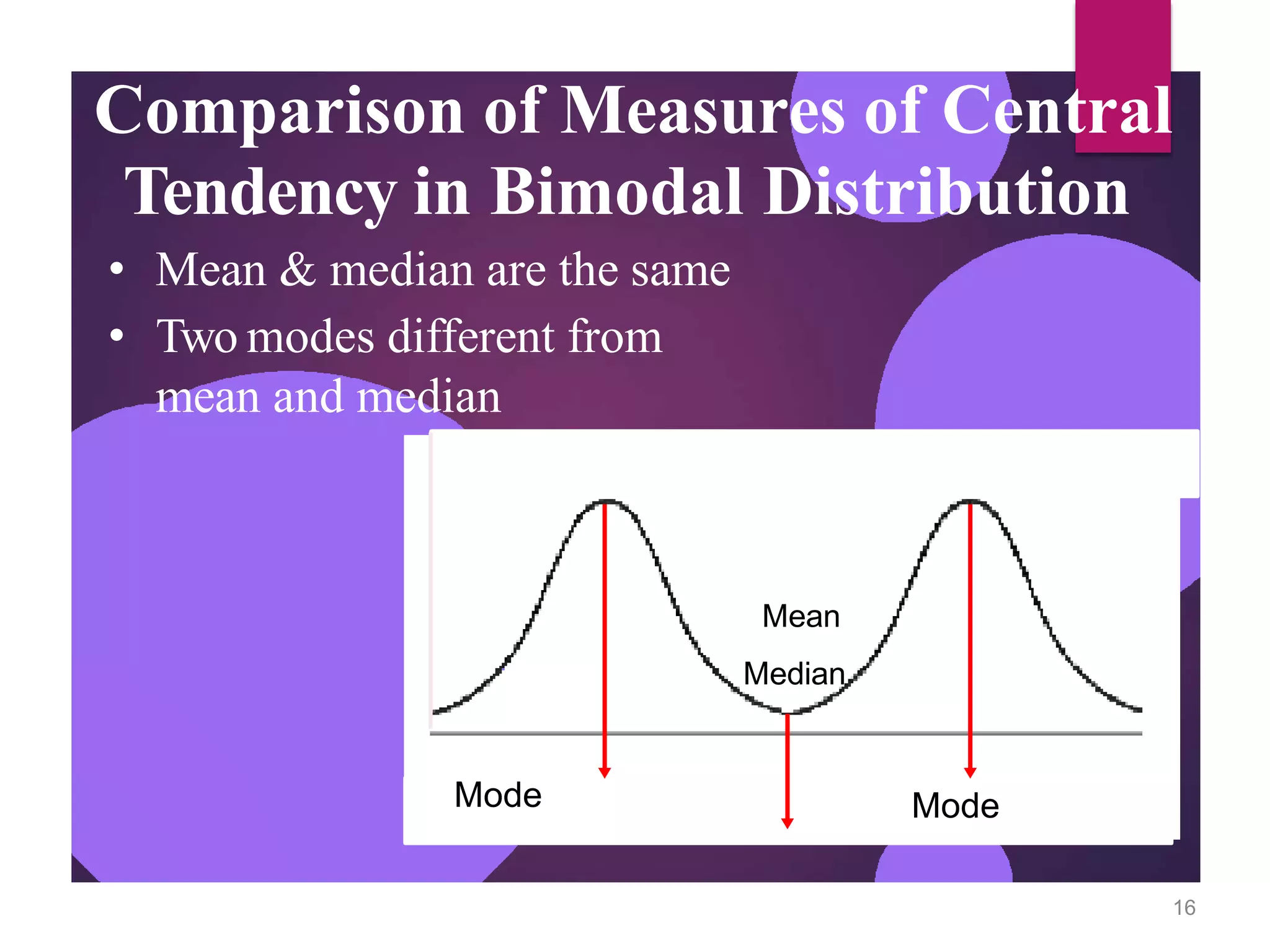
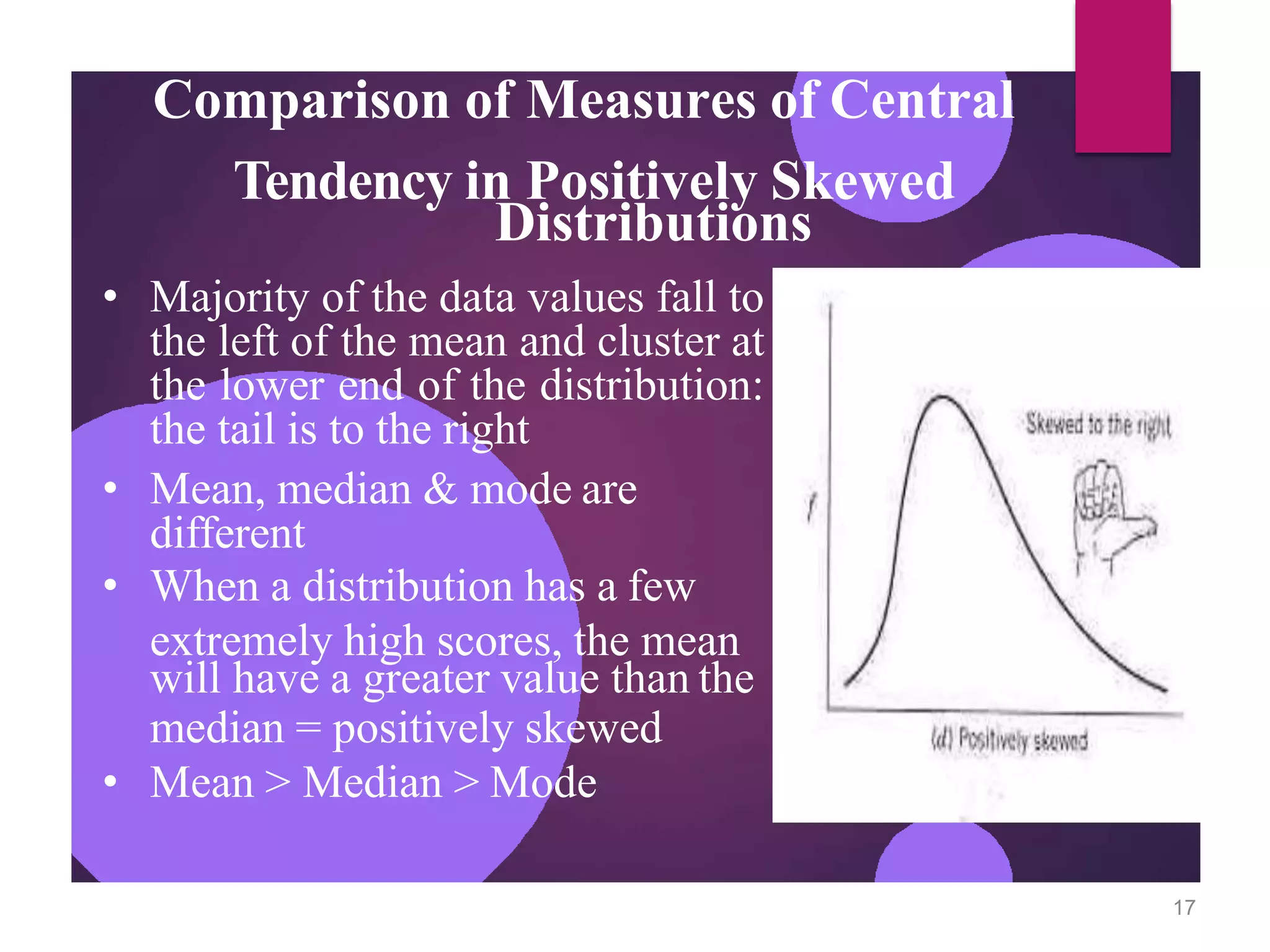
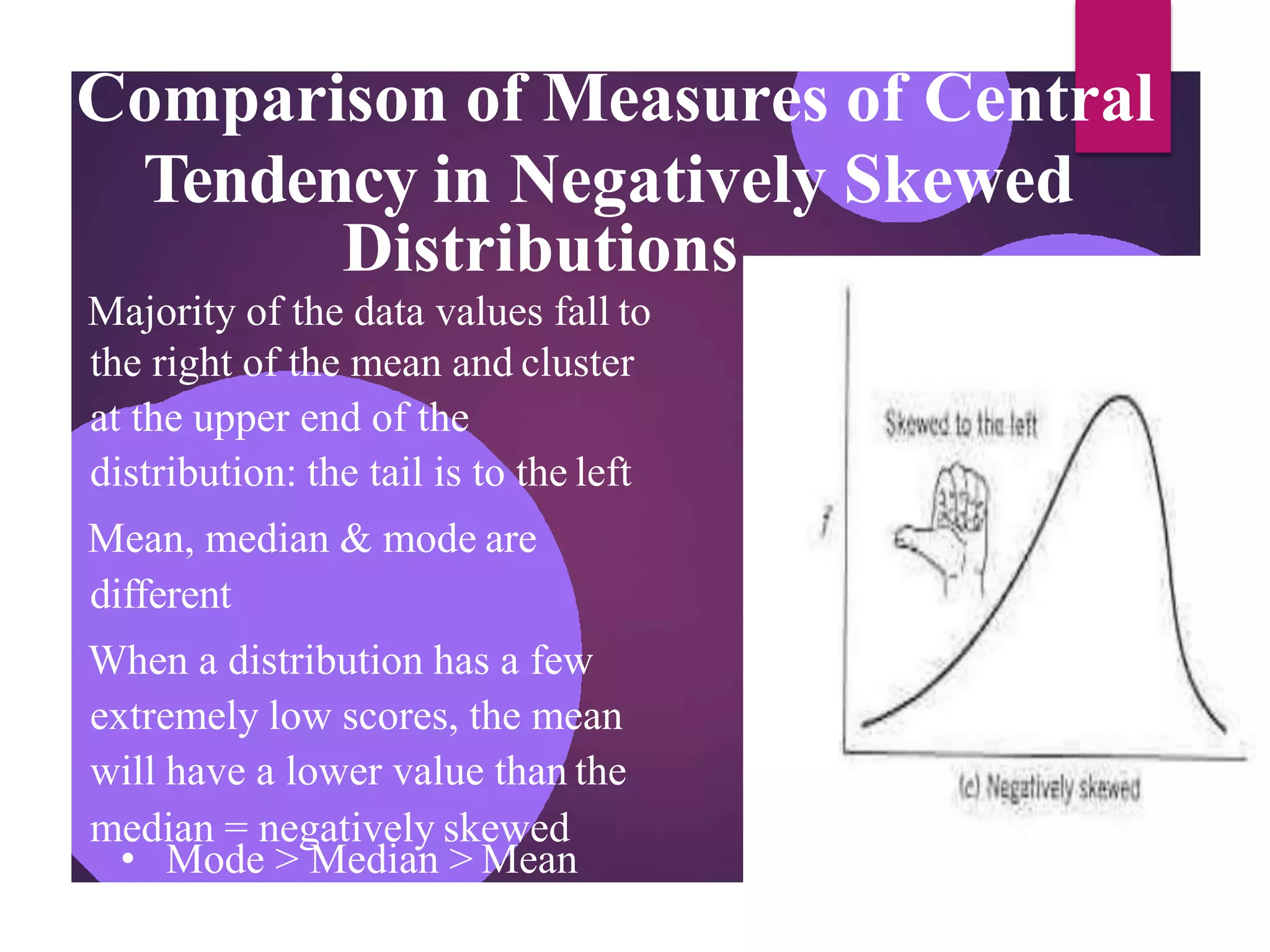
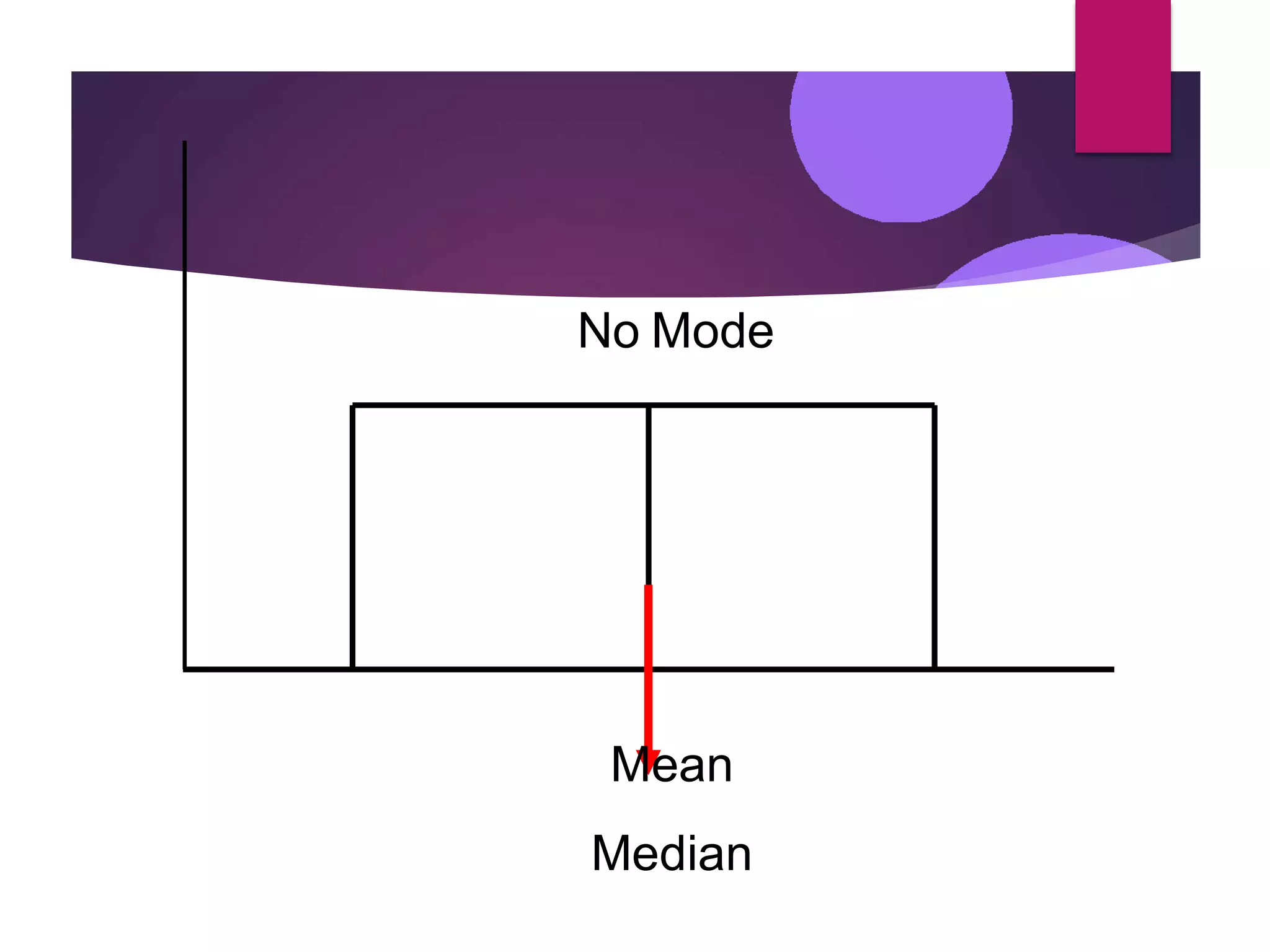
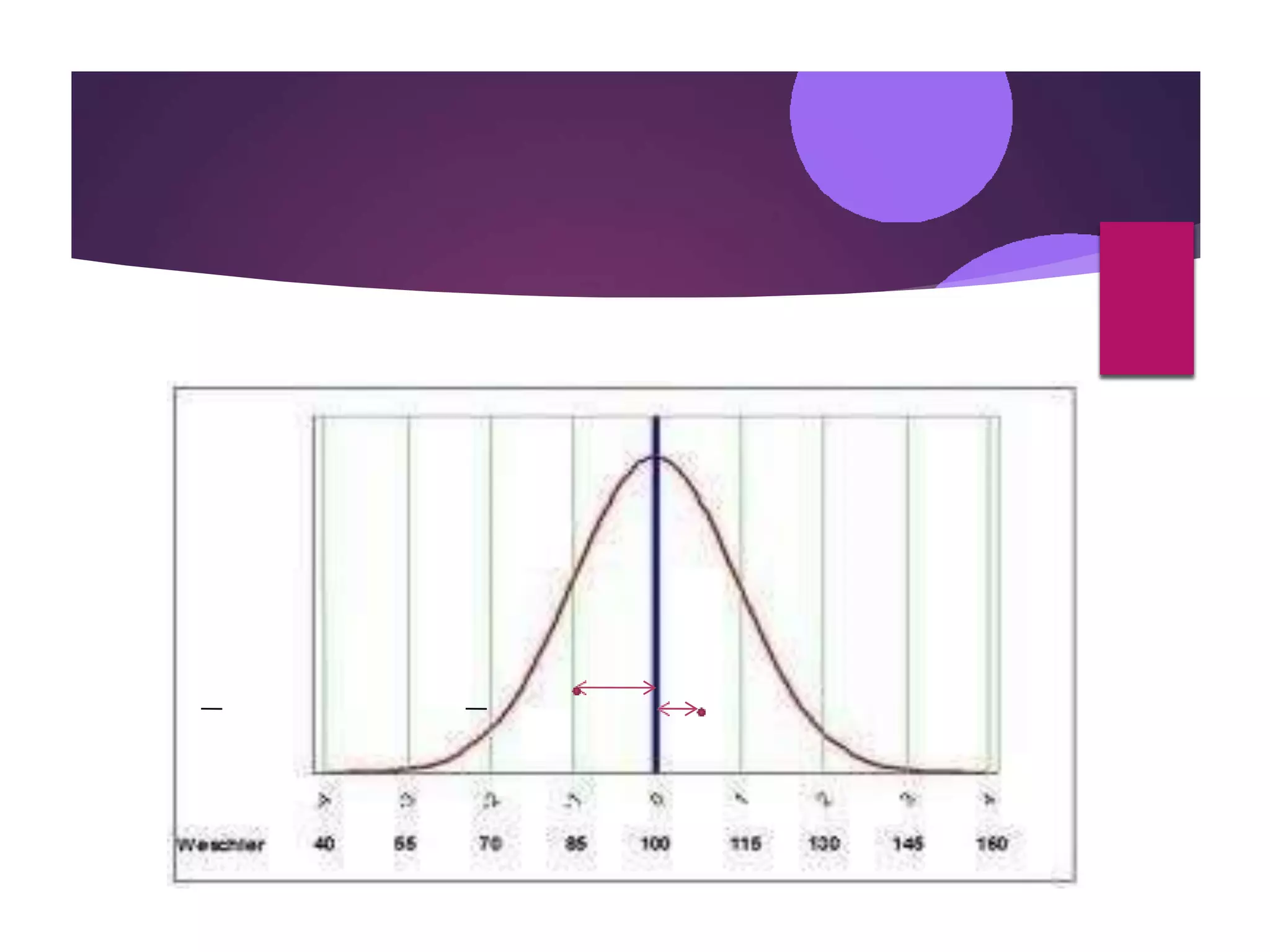
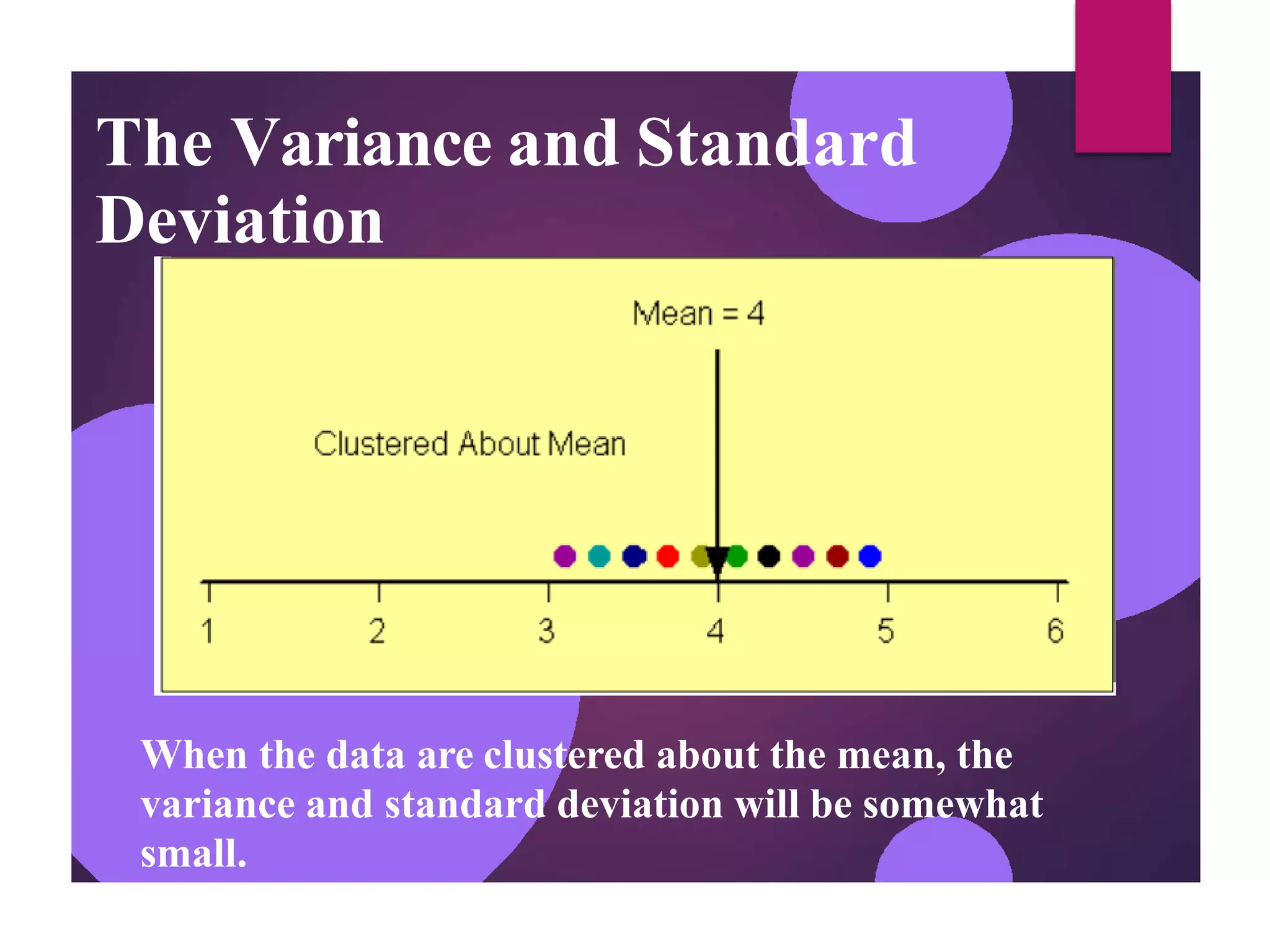
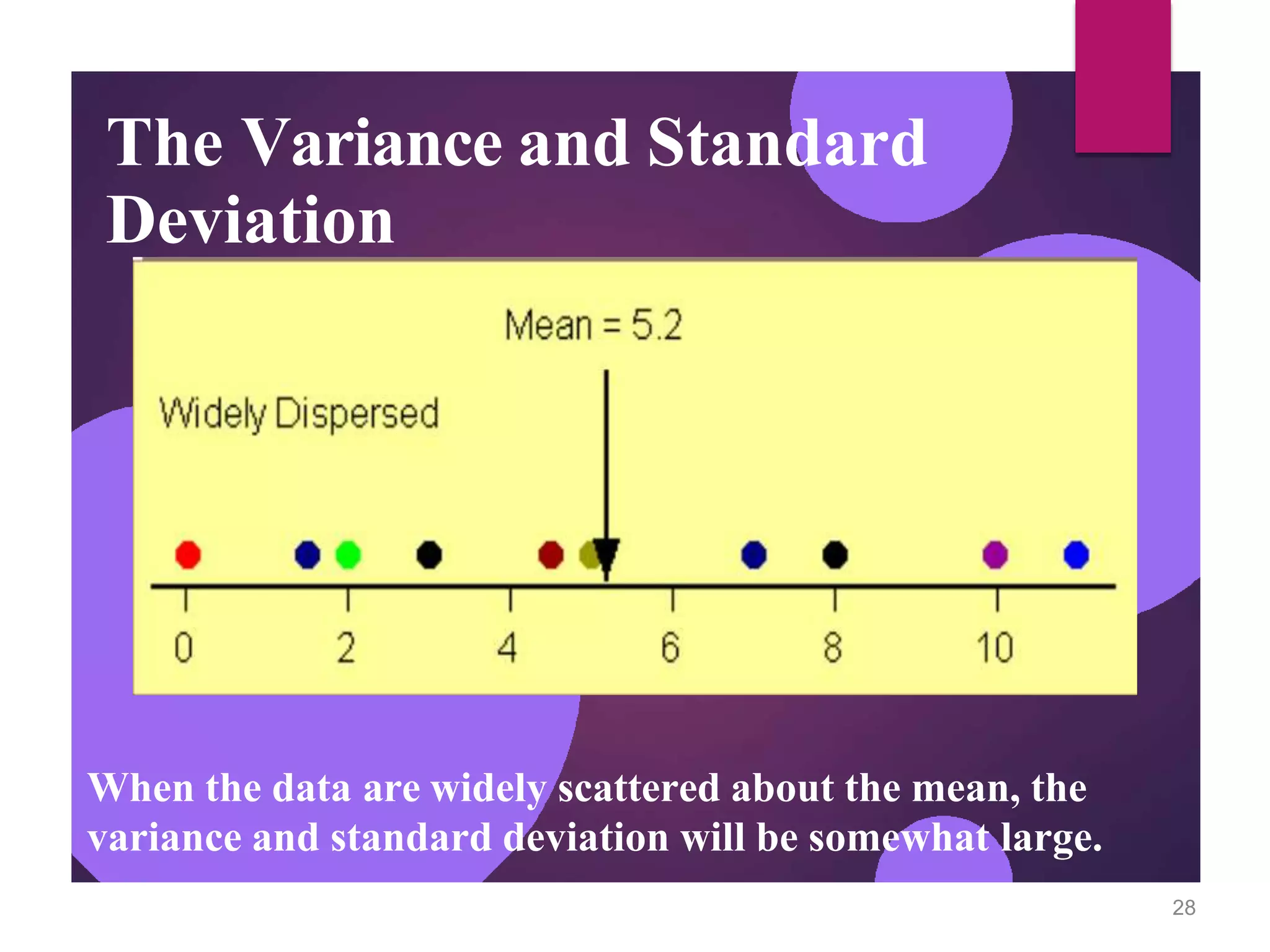
The document discusses measures of central tendency (mean, median, mode) and dispersion (variance, standard deviation) in statistical analysis, detailing their definitions, computations, and applications. It emphasizes the importance of these measures in summarizing data, identifying typical values, and understanding data variability. Additionally, the document provides examples and comparisons of different measures in various data distributions.