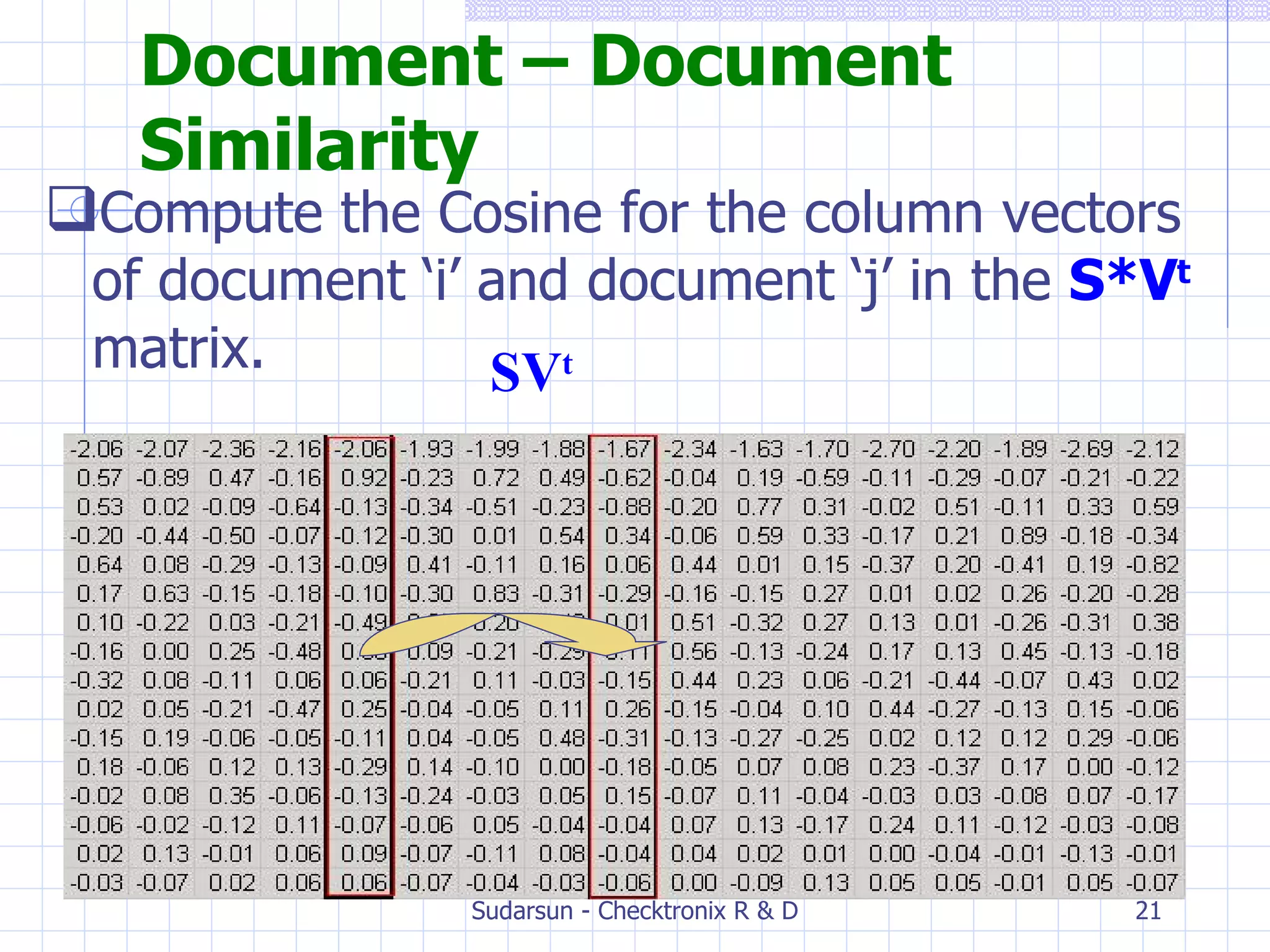
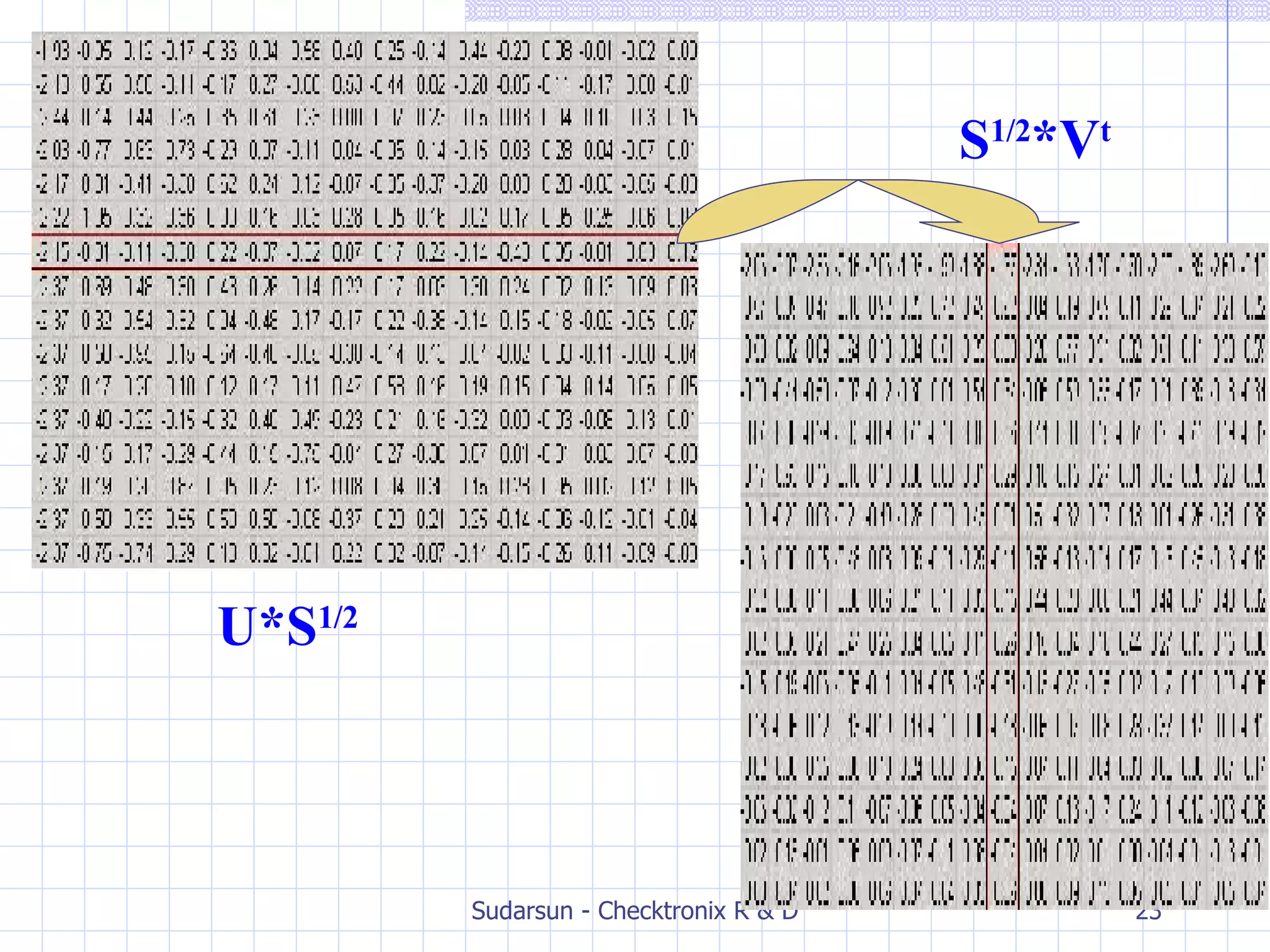
The document discusses Latent Semantic Analysis (LSA), a statistical method for analyzing relationships between documents and terms by reducing large datasets into significant information. It explains concepts such as singular value decomposition, semantic representation, and methods for computing term-document similarities. Additionally, it addresses limitations of LSA and mentions alternative techniques like Probabilistic LSA and Latent Dirichlet Allocation.
![Latent Semantic Indexing Sudarsun. S., M.Tech Checktronix India Pvt Ltd, Chennai 600034 [email_address]](https://image.slidesharecdn.com/latent-semantic-indexing-for-information-retrieval-1193735645789623-4/75/Latent-Semantic-Indexing-For-Information-Retrieval-1-2048.jpg)






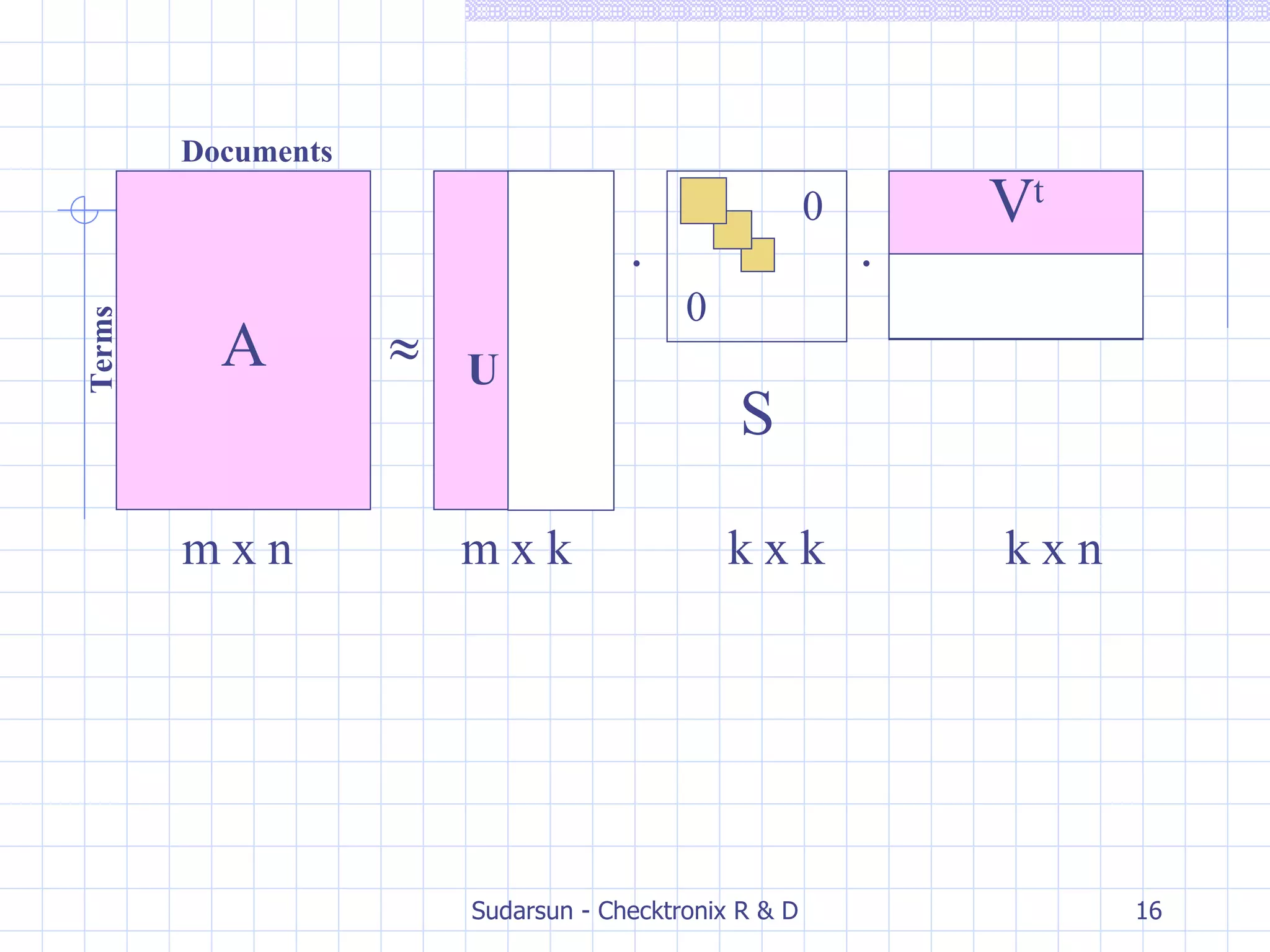
![Computation of SVD To Find U,S and V matrices Find Eigen Values and their corresponding Eigen Vectors of the matrix AA t Singular values = Square root of Eigen Values. These Singular values arranged in descending order forms the diagonal elements of the diagonal matrix S . Divide each Eigen vector by its length. These Eigen vectors forms the columns of the matrix U . Similarly Eigen Vectors of the matrix A t A forms the columns of matrix V. [ Note : Eigen Values of AA t and A t A are equal.]](https://image.slidesharecdn.com/latent-semantic-indexing-for-information-retrieval-1193735645789623-4/75/Latent-Semantic-Indexing-For-Information-Retrieval-8-2048.jpg)






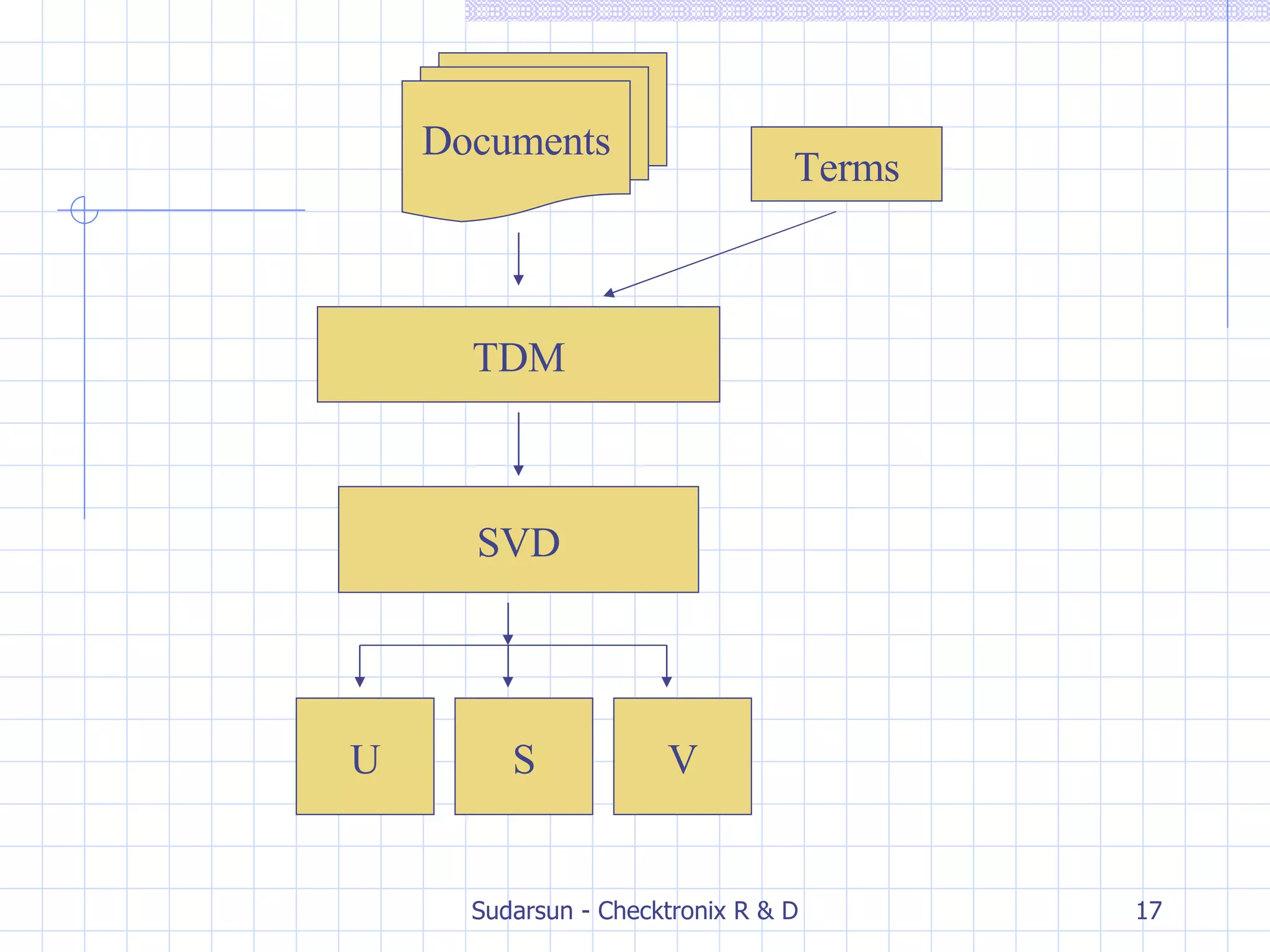
![Step #3: SVD Perform SVD on term-document matrix X. SVD removes noise or infrequent words that do not help to classify a document. Octave/Mat lab can be used [u, s, v] = svd(A);](https://image.slidesharecdn.com/latent-semantic-indexing-for-information-retrieval-1193735645789623-4/75/Latent-Semantic-Indexing-For-Information-Retrieval-15-2048.jpg)

























































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)





