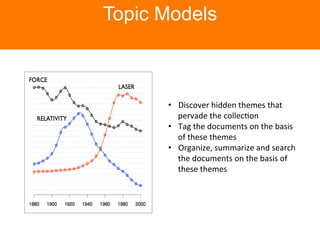
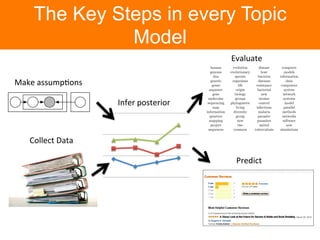
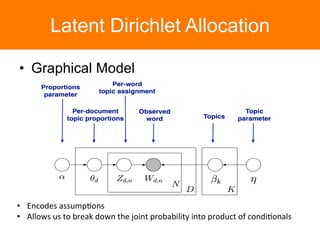
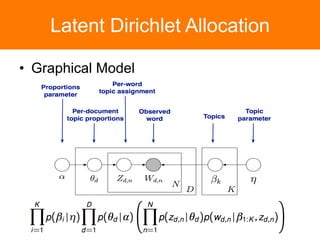
The document is a tutorial on topic modeling, covering concepts such as probabilistic topic models, their applications, and training/inference methods, particularly focusing on Latent Dirichlet Allocation (LDA). It discusses the evaluation of topic models and introduces advanced concepts like sentiment analysis and rating prediction. Additionally, it outlines future directions in topic modeling, emphasizing the need for model selection and incorporating linguistic structures.




















































![[Final]collaborative filtering and recommender systems](https://cdn.slidesharecdn.com/ss_thumbnails/finalcollaborativefilteringandrecommendersystems-141103044224-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)

























![Document Clustering using LDA | Haridas Narayanaswamy [Pramati]](https://cdn.slidesharecdn.com/ss_thumbnails/documentclusteringusinglda-190430091535-thumbnail.jpg?width=640&height=640&fit=bounds)




















