Download to read offline













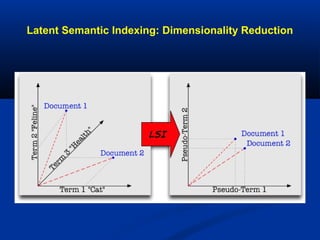



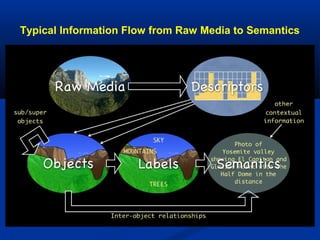










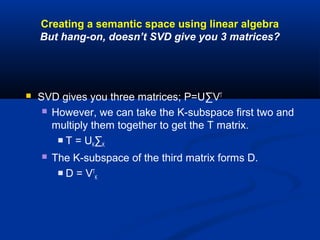












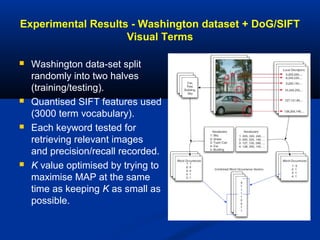






The document discusses multimodal searching and semantic spaces to enhance image retrieval, particularly for unannotated images. It explores computational and mathematical techniques like latent semantic indexing to enable content-based multimedia search without relying on extensive metadata. Experimental results demonstrate the effectiveness of these methods in various datasets, including applications for kennel club imagery.














































































