










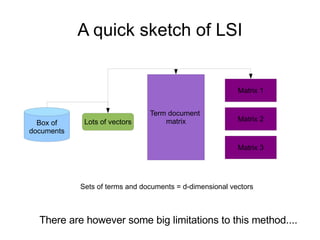












An index is a database that stores information collected from documents in a way that allows quick retrieval. It maps words to their locations in documents. Different indexing methods exist, including inverted indexes and latent semantic indexing (LSI). Probabilistic latent semantic indexing (PLSI) is an improvement over LSI as it has a stronger statistical model and can handle issues like synonyms and multiple meanings of words better. Creating accurate indexes is important for search engines to return relevant results but it involves challenges like document formatting, language processing, and updating as new information is added.






























































































